|
Gromacs
2022.2
|


All Classes Namespaces Files Functions Variables Typedefs Enumerations Enumerator Friends Macros Groups Pages
|
Gromacs
2022.2
|
A new modular approach to the GROMACS simulator is described. The simulator in GROMACS is the object which carries out a simulation. The simulator object is created and owned by the runner object, which is outside of the scope of this new approach, and will hence not be further described. The simulator object provides access to some generally used data, most of which is owned by the runner object.
GROMACS will automatically use the modular simulator for the velocity verlet integrator (integrator = md-vv), if the functionality chosen in the other input parameters is implemented in the new framework. Currently, this includes NVE, NVT, NPH, and NPT simulations, with or without free energy perturbation, using all available temperature and pressure coupling algorithms. It also includes pull and expanded ensemble simulations.
To disable the modular simulator for cases defaulting to the new framework, the environment variable GMX_DISABLE_MODULAR_SIMULATOR=ON can be set. To use the new framework also for integrator = md (where the functionality is implemented), the environment variable GMX_USE_MODULAR_SIMULATOR=ON can be set to override legacy default.
In the legacy implementation, the simulator consisted of a number of independent functions carrying out different type of simulations, such as do_md (MD simulations), do_cg and do_steep (minimization), do_rerun (force and energy evaluation of simulation trajectories), do_mimic (MiMiC QM/MM simulations), do_nm (normal mode analysis), and do_tpi (test-particle insertion).
The legacy approach has some obvious drawbacks:
do_* functions defines local data, including complex objects encapsulating some data and functionality, but also data structures effectively used as "global variables" for communication between different parts of the simulation. Neither the ownership nor the access rights (except for const qualifiers) are clearly defined.do_* functions are dependent on each others, i.e. rely on being called in a specific order, but these dependencies are not clearly defined.do_* functions are hard to understand due to branching. At setup time, and then at every step of the simulation run, a number of booleans are set (e.g. bNS (do neighbor searching), bCalcEner (calculate energies), do_ene (write energies), bEner (energy calculation needed), etc). These booleans enable or disable branches of the code (for the current step or the entire run), mostly encoded as if(...) statements in the main do_* loop, but also in functions called from there.The main design goals of the new, fully modular simulator approach include
The general design approach is that of a task scheduler. Tasks are argument-less functions which perform a part of the computation. Periodically during the simulation, the scheduler builds a queue of tasks, i.e. a list of tasks which is then run through in order. Over time, with data dependencies clearly defined, this approach can be modified to have independent tasks run in parallel.
The task scheduler holds a list of simulator elements, defined by the ISimulatorElement interface. These elements have a scheduleTask(Step, Time) function, which gets called by the task scheduler. This allows the simulator element to register one (or more) function pointers to be run at that specific (Step, Time). From the point of view of the element, it is important to note that the computation will not be carried out immediately, but that it will be called later during the actual (partial) simulation run. From the point of view of the builder of the task scheduler, it is important to note that the order of the elements determines the order in which computation is performed.
class ISimulatorElement
{
public:
/*! \\brief Query whether element wants to run at step / time
*
* Element can register one or more functions to be run at that step through
* the registration pointer.
*/
virtual void scheduleTask(Step, Time, const RegisterRunFunction&) = 0;
//! Method guaranteed to be called after construction, before simulator run
virtual void elementSetup() = 0;
//! Method guaranteed to be called after simulator run, before deconstruction
virtual void elementTeardown() = 0;
//! Standard virtual destructor
virtual ~ISimulatorElement() = default;
};
The task scheduler periodically loops over its list of elements, builds a queue of function pointers to run, and returns this list of tasks. As an example, a possible application would be to build a new queue after each domain-decomposition (DD) / neighbor-searching (NS) step, which might occur every 100 steps. The scheduler would loop repeatedly over all its elements, with elements like the trajectory-writing element registering for only one or no step at all, the energy-calculation element registering for every tenth step, and the force, position / velocity propagation, and constraining algorithms registering for every step. The result would be a (long) queue of function pointers including all computations needed until the next DD / NS step, which can be run without any branching.
Some elements might require computations by other elements. If for example, the trajectory writing is an element independent from the energy-calculation element, it needs to signal to the energy element that it is about to write a trajectory, and that the energy element should be ready for that (i.e. perform an energy calculation in the upcoming step). This requirement, which replaces the boolean branching in the current implementation, is fulfilled by a Signaller - Client model. Classes implementing the ISignaller interface get called before every loop of the element list, and can inform registered clients about things happening during that step. The trajectory element, for example, can tell the energy element that it will write to trajectory at the end of this step. The energy element can then register an energy calculation during that step, being ready to write to trajectory when requested.
class ISignaller
{
public:
//! Function run before every step of scheduling
virtual void signal(Step, Time) = 0;
//! Method guaranteed to be called after construction, before simulator run
virtual void setup() = 0;
};
The approach is most easily displayed using some simplified (pseudo) code.
The simulator itself is responsible to store the elements in the right order (in addIntegrationElements) This includes the different order of elements in different algorithms (e.g. leap-frog vs. velocity verlet), but also logical dependencies (energy output after compute globals). Once the algorithm has been built, the simulator simply executes one task after the next, until the end of the simulation is reached.
class ModularSimulator : public ISimulator
{
public:
//! Run the simulator
void run() override;
}
void ModularSimulator::run()
{
ModularSimulatorAlgorithmBuilder algorithmBuilder();
addIntegrationElements(&algorithmBuilder);
auto algorithm = algorithmBuilder.build();
while (const auto* task = algorithm.getNextTask())
{
// execute task
(*task)();
}
}
The following snippet illustrates building a leap-frog integration algorithm. The algorithm builder allows for a concise description of the simulator algorithm.
void ModularSimulator::addIntegrationElements(ModularSimulatorAlgorithmBuilder* builder)
{
if (legacySimulatorData_->inputrec->eI == eiMD)
{
// The leap frog integration algorithm
builder->add<ForceElement>();
// We have a full state here (positions(t), velocities(t-dt/2), forces(t)
builder->add<StatePropagatorData::Element>();
if (legacySimulatorData_->inputrec->etc == TemperatureCoupling::VRescale)
{
builder->add<VRescaleThermostat>(-1,
VRescaleThermostatUseFullStepKE::No,
PropagatorTag("LeapFrogPropagator"));
}
builder->add<Propagator<IntegrationStage::LeapFrog>>(PropagatorTag("LeapFrogPropagator"),
legacySimulatorData_->inputrec->delta_t);
if (legacySimulatorData_->constr)
{
builder->add<ConstraintsElement<ConstraintVariable::Positions>>();
}
builder->add<ComputeGlobalsElement<ComputeGlobalsAlgorithm::LeapFrog>>();
// We have the energies at time t here
builder->add<EnergyData::Element>();
if (legacySimulatorData_->inputrec->epc == PressureCoupling::ParrinelloRahman)
{
builder->add<ParrinelloRahmanBarostat>(-1, PropagatorTag("LeapFrogPropagator"));
}
}
}
The simulator algorithm is responsible to decide if elements need to run at a specific time step. The elements get called in order, and decide whether they need to run at a specific step. This can be pre-computed for multiple steps. In the current implementation, the tasks are pre-computed for the entire life-time of the neighbor list.
The simulator algorithm offers functionality to get the next task from the queue. It owns all elements involved in the simulation and is hence controlling their lifetime. This ensures that pointers and callbacks exchanged between elements remain valid throughout the duration of the simulation run. It also maintains the list of tasks, and updates it when needed.
class ModularSimulatorAlgorithm
{
public:
//! Get next task in queue
[[nodiscard]] const SimulatorRunFunction* getNextTask();
private:
//! List of signalers
std::vector<std::unique_ptr<ISignaller>> signallerList_;
//! List of elements
std::vector<std::unique_ptr<ISimulatorElement>> elementsList_;
//! The run queue
std::vector<SimulatorRunFunction> taskQueue_;
//! The task iterator
std::vector<SimulatorRunFunction>::const_iterator taskIterator_;
//! Update task queue
void updateTaskQueue();
}
The getNextTask() function is returning the next task in the task queue. It rebuilds the task list when needed.
const SimulatorRunFunction* ModularSimulatorAlgorithm::getNextTask()
{
if (!taskQueue_.empty())
{
taskIterator_++;
}
if (taskIterator_ == taskQueue_.end())
{
if (runFinished_)
{
return nullptr;
}
updateTaskQueue();
taskIterator_ = taskQueue_.begin();
}
return &*taskIterator_;
}
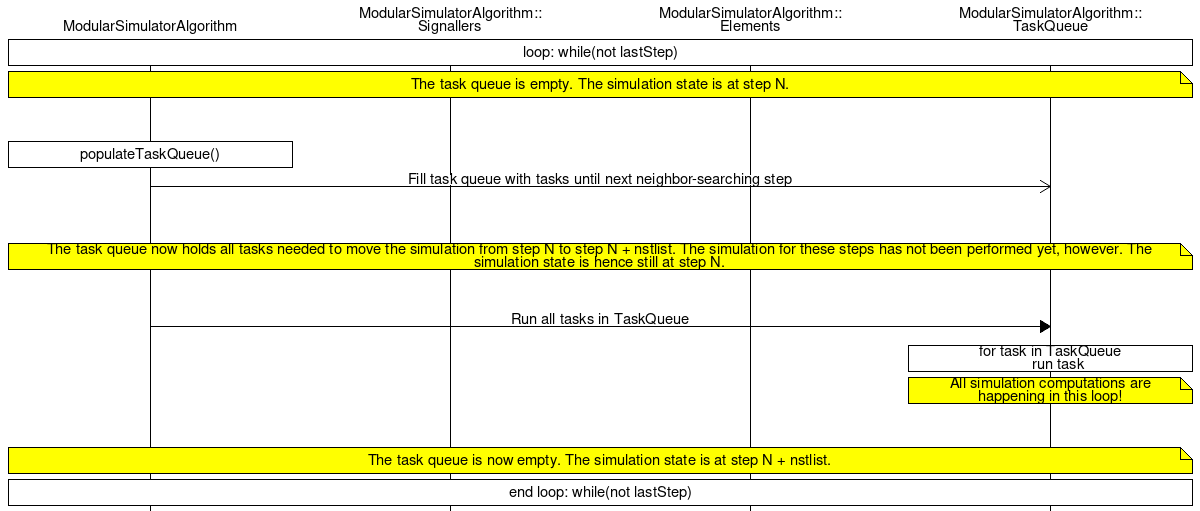
Updating the task queue involves calling all signallers and elements for every step of the scheduling period. This refills the task queue. It is important to keep in mind that the scheduling step is not necessarily identical to the current step of the simulation. Most of the time, the scheduling step is ahead, as we are pre-scheduling steps.
void ModularSimulatorAlgorithm::updateTaskQueue()
{
for (Step schedulingStep = currentStep;
schedulingStep < currentStep + schedulingPeriod;
schedulingStep++)
{
Time time = getTime(schedulingStep);
// Have signallers signal any special treatment of scheduling step
for (const auto& signaller : signallerList)
{
signaller.signal(schedulingStep, time);
}
// Query all elements whether they need to run at scheduling step
for (const auto& element : signallerList)
{
element.schedule(schedulingStep, time, registerRunFunction_);
}
}
}
In the loop preparation, the signallers and elements are created and stored in the right order. The signallers and elements can then perform any setup operations needed.
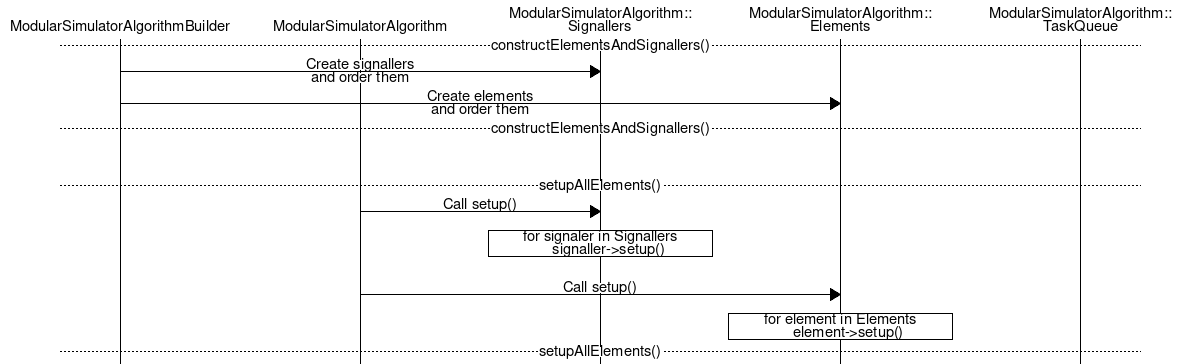
The main loop consists of two parts which are alternately run until the simulation stop criterion is met. The first part is the population of the task queue, which determines all tasks that will have to run to simulate the system for a given time period. In the current implementation, the scheduling period is set equal to the lifetime of the neighborlist. Once the tasks have been predetermined, the simulator runs them in order. This is the actual simulation computation, which can now run without any branching.
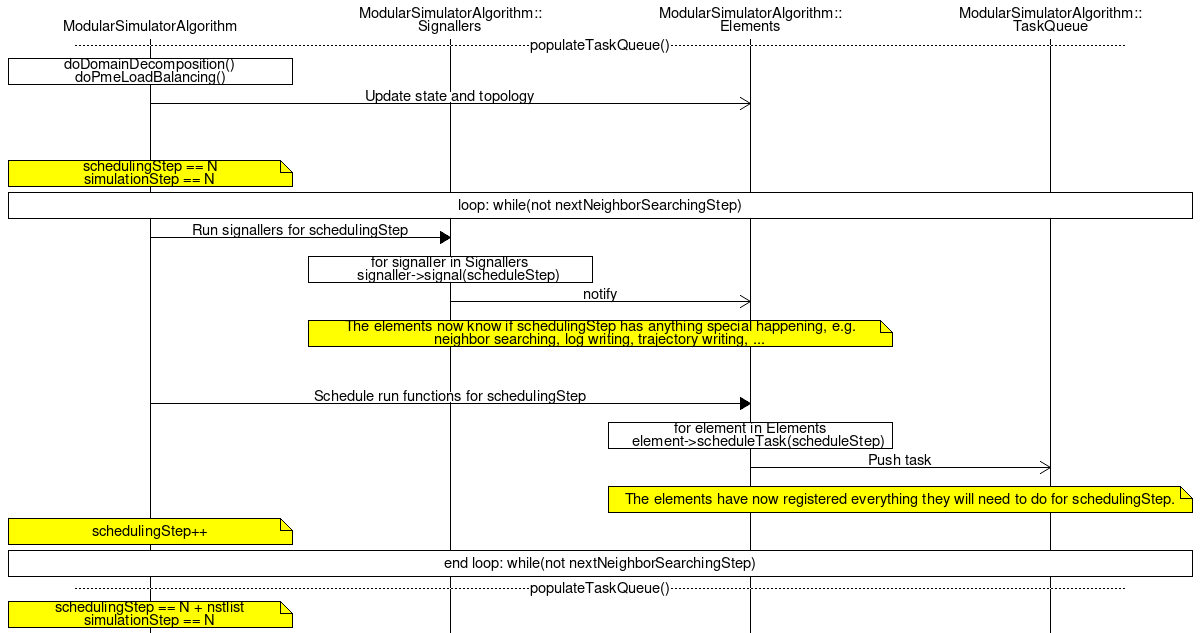
A part of the main loop, the task scheduling in populateTaskQueue() allows the elements to push tasks to the task queue. For every scheduling step, the signallers are run first to give the elements information about the upcoming scheduling step. The scheduling routine elements are then called in order, allowing the elements to register their respective tasks.
Acceptance tests which need to be fulfilled to make the modular simulator the default code path:
do_md and the new loop in Gitlab pre- and post-submit pipelinesAfter the MD bare minimum, we will want to add support for
Using the new modular simulator framework, we will then explore adding new functionality to GROMACS, including
We will also explore optimization opportunities, including
We will probably not prioritize support for (and might consider deprecating from do_md in a future GROMACS version)
The current implementation of the modular simulator consists of the following signallers and elements:
All signallers have a list of pointers to clients, objects that implement a respective interface and get notified of events the signaller is communicating.
NeighborSearchSignaller: Informs its clients whether the current step is a neighbor-searching step.LastStepSignaller: Informs its clients when the current step is the last step of the simulation.LoggingSignaller: Informs its clients whether output to the log file is written in the current step.EnergySignaller: Informs its clients about energy related special steps, namely energy calculation steps, virial calculation steps, and free energy calculation steps.TrajectorySignaller: Informs its clients if writing to trajectory (state [x/v/f] and/or energy) is planned for the current step.TrajectoryElementThe TrajectoryElement is calling its trajectory clients, passing them a valid output pointer and letting them write to trajectory. Unlike the legacy implementation, the trajectory element itself knows nothing about the data that is written to file - it is only responsible to inform clients about trajectory steps, and providing a valid file pointer to the objects that need to write to trajectory.
ComputeGlobalsElementThe ComputeGlobalsElement encapsulates the legacy calls to compute_globals. While a new approach to the global reduction operations has been discussed, it is currently not part of this effort. This element therefore aims at offering an interface to the legacy implementation which is compatible with the new simulator approach.
The element currently comes in 3 (templated) flavors: the leap-frog case, the first call during a velocity-verlet integrator, and the second call during a velocity-verlet integrator. It is the responsibility of the simulator builder to place them at the right place of the integration algorithm.
ForceElement and ShellFCElementThe ForceElement and the ShellFCElement encapsulate the legacy calls to do_force and do_shellfc, respectively. It is the responsibility of the simulator builder to place them at the right place of the integration algorithm. Moving forward, a version of these elements which would allow calling of do_force with subsets of the topology would be desirable to pave the way towards multiple time step integrators within modular simulator, allowing to integrate slower degrees of freedom at a different frequency than faster degrees of freedom.
ConstraintElementThe constraint element is implemented for the two cases of constraining both positions and velocities, and only velocities. It does not change the constraint implementation itself, but replaces the legacy constrain_coordinates and constrain_velocities calls from update.h by elements implementing the ISimulatorElement interface and using the new data management.
PropagatorThe propagator element can, through templating, cover the different propagation types used in the currently implemented MD schemes. The combination of templating, static functions, and having only the inner-most operations in the static functions allows to have performance comparable to fused update elements while keeping easily re-orderable single instructions.
Currently, the (templated) implementation covers four cases:
The propagators also allow to implement temperature and pressure coupling schemes by offering (templated) scaling of the velocities. In order to link temperature / pressure coupling objects to the propagators, the propagator objects have a tag (of strong type PropagatorTag). The temperature and pressure coupling objects can then connect to the matching propagator by comparing their target tag to the different propagators. Giving the propagators their tags and informing the temperature and pressure coupling algorithms which propagator they are connecting to is in the responsibility of the simulation algorithm builder.
CompositeSimulatorElementThe composite simulator element takes a list of elements and implements the ISimulatorElement interface, making a group of elements effectively behave as one. This simplifies building algorithms.
VRescaleThermostatThe VRescaleThermostat implements the v-rescale thermostat. It takes a callback to the propagator and updates the velocity scaling factor according to the v-rescale thermostat formalism.
ParrinelloRahmanBarostatThe ParrinelloRahmanBarostat implements the Parrinello-Rahman barostat. It integrates the Parrinello-Rahman box velocity equations, takes a callback to the propagator to update the velocity scaling factor, and scales the box and the positions of the system.
StatePropagatorData::ElementThe StatePropagatorData::Element takes part in the simulator run, as it might have to save a valid state at the right moment during the integration. Placing the StatePropagatorData correctly is for now the duty of the simulator builder - this might be automated later if we have enough meta-data of the variables (i.e., if StatePropagatorData knows at which time the variables currently are, and can decide when a valid state (full-time step of all variables) is reached. The StatePropagatorData::Element is also a client of both the trajectory signaller and writer - it will save a state for later writeout during the simulator step if it knows that trajectory writing will occur later in the step, and it knows how to write to file given a file pointer by the TrajectoryElement.
EnergyData::ElementThe EnergyData::Element takes part in the simulator run, either adding data (at energy calculation steps), or recording a non-calculation step (all other steps). It is the responsibility of the simulator builder to ensure that the EnergyData::Element is called at a point of the simulator run at which it has access to a valid energy state.
It subscribes to the trajectory signaller, the energy signaller, and the logging signaller to know when an energy calculation is needed and when a non-recording step is enough. The EnergyData element is also a subscriber to the trajectory writer element, as it is responsible to write energy data to trajectory.
FreeEnergyPerturbationData::ElementThe FreeEnergyPerturbationData::Element is a member class of FreeEnergyPerturbationData that updates the lambda values during the simulation run if lambda is non-static. It implements the checkpointing client interface to save the current state of FreeEnergyPerturbationData for restart.
StatePropagatorDataThe StatePropagatorData contains a little more than the pure statistical-physical micro state, namely the positions, velocities, forces, and box matrix, as well as a backup of the positions and box of the last time step. While it takes part in the simulator loop to be able to backup positions / boxes and save the current state if needed, it's main purpose is to offer access to its data via getter methods. All elements reading or writing to this data need a pointer to the StatePropagatorData and need to request their data explicitly. This will later simplify the understanding of data dependencies between elements.
Note that the StatePropagatorData can be converted to and from the legacy t_state object. This is useful when dealing with functionality which has not yet been adapted to use the new data approach. Of the elements currently implemented, only domain decomposition, PME load balancing, and the initial constraining are using this.
EnergyDataThe EnergyData owns the EnergyObject, and is hence responsible for saving energy data and writing it to trajectory. The EnergyData offers an interface to add virial contributions, but also allows access to the raw pointers to tensor data, the dipole vector, and the legacy energy data structures.
FreeEnergyPerturbationDataThe FreeEnergyPerturbationData holds the lambda vector and the current FEP state, offering access to its values via getter functions.
Elements that define the integration algorithm (i.e. which are added using the templated ModularSimulatorAlgorithmBuilder::add method) need to implement a getElementPointerImpl factory function. This gives them access to the data structures and some other infrastructure, but also allows elements to accept additional arguments (e.g frequency, offset, ...).
template<typename Element, typename... Args>
void ModularSimulatorAlgorithmBuilder::add(Args&&... args)
{
// Get element from factory method
auto* element = static_cast<Element*>(getElementPointer<Element>(
legacySimulatorData_, &elementAdditionHelper_, statePropagatorData_.get(),
energyData_.get(), freeEnergyPerturbationData_.get(), &globalCommunicationHelper_,
std::forward<Args>(args)...));
// Make sure returned element pointer is owned by *this
// Ensuring this makes sure we can control the life time
if (!elementExists(element))
{
throw ElementNotFoundError("Tried to append non-existing element to call list.");
}
// Register element with infrastructure
}
Note that getElementPointer<Element> will call Element::getElementPointerImpl, which needs to be implemented by the different elements.
Modular simulator encourages design localizing data as much as possible. It also offers access to generally used data structures (such as the current state or energies). To allow for generic data to be shared between elements, the simulator algorithm builder also allows to store objects with life time guaranteed to be either equal to the simulator algorithm builder or equal to the simulator algorithm object (i.e. longer than the life time of the elements).
DomDecHelper and PmeLoadBalanceHelperThese infrastructure elements are responsible for domain decomposition and PME load balancing, respectively. They encapsulate function calls which are important for performance, but outside the scope of this effort. They rely on legacy data structures for the state (both) and the topology (domdec).
The elements do not implement the ISimulatorElement interface, as the Simulator is calling them explicitly between task queue population steps. This allows elements to receive the new topology / state before deciding what functionality they need to run.
The CheckpointHelper is responsible to write checkpoints, and to offer its clients access to the data read from checkpoint.
Writing checkpoints is done just before neighbor-searching (NS) steps, or before the last step. Checkpointing occurs periodically (by default, every 15 minutes), and needs two NS steps to take effect - on the first NS step, the checkpoint helper on master rank signals to all other ranks that checkpointing is about to occur. At the next NS step, the checkpoint is written. On the last step, checkpointing happens immediately before the step (no signalling). To be able to react to last step being signalled, the CheckpointHelper also implements the ISimulatorElement interface, but only registers a function if the last step has been called.
Checkpointing happens at the top of a simulation step, which gives a straightforward re-entry point at the top of the simulator loop.
Legacy checkpointing approach: All data to be checkpointed needs to be stored in one of the following data structures:
t_state, which also holds pointers tohistory_t (history for restraints)df_history_t (history for free energy)ekinstateAwhHistoryObservableHistory, consisting ofenergyhistory_tPullHistoryedsamhistory_tswaphistory_tThese data structures are then serialized by a function having knowledge of their implementation details. One possibility to add data to the checkpoint is to expand one of the objects that is currently being checkpointed, and edit the respective do_cpt_XXX function in checkpoint.cpp which interacts with the XDR library. The alternative would be to write an entirely new data structure, changing the function signature of all checkpoint-related functions, and write a corresponding low-level routine interacting with the XDR library.
The MDModule approach: To allow for modules to write checkpoints, the legacy checkpoint was extended by a KVTree. When writing to checkpoint, this tree gets filled (via callbacks) by the single modules, and then serialized. When reading, the KVTree gets deserialized, and then distributed to the modules which can read back the data previously stored.
The MDModule checks off almost all requirements to a modularized checkpointing format. The proposed design is therefore an evolved form of this approach. Notably, two improvements include
The modular simulator checkpointing does not currently change the way that the legacy simulator is checkpointing. Some data structures involved in the legacy checkpoint did, however, get an implementation of the new approach. This is needed for ModularSimulator checkpointing, but also gives a glimpse of how implementing this for legacy data structures would look like.
The most important design part is the CheckpointData class. It exposes methods to read and write scalar values, ArrayRefs, and tensors. It also allows to create a "sub-object" of the same type CheckpointData which allows to have more complex members implement their own checkpointing routines (without having to be aware that they are a member). All methods are templated on the chosen operation, CheckpointDataOperation::Read or CheckpointDataOperation::Write, allowing clients to use the same code to read and write to checkpoint. Type traits and constness are used to catch as many errors as possible at compile time. CheckpointData uses a KV-tree to store the data internally. This is however never exposed to the client. Having this abstraction layer gives freedom to change the internal implementation in the future.
All CheckpointData objects are owned by a ReadCheckpointDataHolder or WriteCheckpointDataHolder. These holder classes own the internal KV-tree, and offer deserialize(ISerializer*) and serialize(ISerializer*) functions, respectively, which allow to read from / write to file. This separation clearly defines ownership and separates the interface aimed at file IO from the interface aimed at objects reading / writing checkpoints.
Checkpointing for modular simulator is tied in the general checkpoint facility by passing a ReadCheckpointDataHolder or WriteCheckpointDataHolder object to the legacy checkpoint read and write operations.
Distinction of data between clients: The design requires that separate clients have independent sub-CheckpointData objects identified by a unique key. This key is the only thing that needs to be unique between clients, i.e. clients are free to use any key within their sub-CheckpointData without danger to overwrite data used by other clients.
Versioning: The design relies on clients keeping their own versioning system within their sub-CheckpointData object. As the data stored by clients is opaque to the top level checkpointing facility, it has no way to know when the internals change. Only fundamental changes to the checkpointing architecture can still be tracked by a top-level checkpoint version.
Key existence: The currently uploaded design does not allow to check whether a key is present in CheckpointData. This could be introduced if needed - however, if clients write self-consistent read and write code, this should never be needed. Checking for key existence seems rather to be a lazy way to circumvent versioning, and is therefore discouraged.
Callback method: The modular simulator and MDModules don't use the exact same way of communicating with clients. The two methods could be unified if needed. The only fundamental difference is that modular simulator clients need to identify with a unique key to receive their dedicated sub-data, while MDModules all read from and write to the same KV-tree. MDModules could be adapted to that by either requiring a unique key from the modules, or by using the same CheckpointData for all modules and using a single unique key (something like "MDModules") to register that object with the global checkpoint.
Performance: One of the major differences between the new approach and the legacy checkpointing is that data gets copied into CheckpointData, while the legacy approach only took a pointer to the data and serialized it. This slightly reduces performance. Some thoughts on that:
CheckpointData object, and don't necessarily need to wait for writing to the physical medium to happen. It also simplifies moving the point at which checkpointing is performed within the integrator. One could envision clients storing their data any time during the integration step, and serializing the resulting CheckpointData after the step. This avoids the need to find a single point within the loop at which all clients need to be in a state suitable for checkpointing.ISerializer vs KV-tree: The new approach uses a KV tree internally. The KV tree is well suited to represent the design philosophy of the approach: Checkpointing offers a functionality which allows clients to write/read any data they want. This data remains opaque to the checkpointing element. Clients can read or write in any order, and in the future, maybe even simultaneously. Data written by any element should be protected from access from other elements to avoid bugs. The downside of the KV tree is that all data gets copied before getting written to file (see above).
Replacing a KV tree by a single ISerializer object which gets passed to clients would require elements to read and write sequentially in a prescribed order. With the help of InMemorySerializer, a KV-Tree could likely be emulated (with sub-objects that serialize to memory, and then a parent object that serializes this memory to file), but that doesn't present a clear advantage anymore.
TopologyHolderThe topology object owns the local topology and holds a constant reference to the global topology owned by the ISimulator.
The local topology is only infrequently changed if domain decomposition is on, and never otherwise. The topology holder therefore offers elements to register as ITopologyHolderClients. If they do so, they get a handle to the updated local topology whenever it is changed, and can rely that their handle is valid until the next update. The domain decomposition element is defined as friend class to be able to update the local topology when needed.
Some simulation techniques such as simulated annealing and simulated tempering need to be able to change the reference temperature of the simulation. The reference temperature manager allows elements to register callbacks so they are informed when the reference temperature is changed. They can then perform any action they need upon change of the reference temperature, such as updating a local value, scaling velocities, or recalculating a temperature coupling integral.
When changing temperature, the clients are also informed about which algorithm changed the temperature. This is required for compatibility to the legacy implementation - different algorithms react differently (or not at all) to reference temperature change from different sources. The current implementation does not attempt to fix these inconsistencies, but rather makes the choices in the legacy implementation very explicit, which will allow to tackle these issues more easily moving forward.
 1.8.5
1.8.5