|
Gromacs
2026.0-dev-20251119-5f0a571d
|


All Classes Namespaces Files Functions Variables Typedefs Enumerations Enumerator Friends Macros Groups Pages
|
Gromacs
2026.0-dev-20251119-5f0a571d
|
Generic GROMACS namespace.
Functionality for testing whether calls to mdrun produce the same energy and force quantities when they should do so.
Declares the integrators for energy minimization and NMA.
Convenience macro to help us avoid ifdefs each time we use sysconf.
Declarations of H5md utility functions.
Declarations of H5md data type utility routines.
Declares the topology utility functions for H5MD.
Definition of the topology utility functions for H5MD.
Declarations of H5md time data block manipulation routines.
Definitions of H5md time data block manipulation routines.
Declarations of H5md particle data block routines.
Definitions of H5md particle data block routines.
Helper functions for managing scope guards in the H5md module.
Declarations of utility functions for working with H5MD groups.
Definitions of utility functions for working with H5MD groups.
Declarations of H5md frame data set builder routines.
Declarations of H5md frame data set manipulation routines.
Definitions of H5md frame data set manipulation routines.
Declarations of H5md fixed data set class.
Definitions of H5md fixed data set class.
Declarations of error utility functions for the H5md module.
Definitions of error utility functions for the H5md module.
Declarations of H5md data set builder routines.
Declarations of H5md data set base class.
Definitions of H5md data set base class.
Declarations of utility functions for working with H5MD attributes.
Definitions of utility functions for working with H5MD attributes.
I/o interface to H5MD HDF5 files.
Namespaces | |
| compat | |
| Compatibility aliases for standard library features. | |
| test | |
| Testing utilities namespace. | |
Classes | |
| class | AnalysisDataModuleManager |
| Encapsulates handling of data modules attached to AbstractAnalysisData. More... | |
| class | AnalysisDataStorageFrame |
| Allows assigning values for a data frame in AnalysisDataStorage. More... | |
| class | AnalysisDataStorage |
| Helper class that implements storage of data. More... | |
| class | ArrayRef |
| STL-like interface to a C array of T (or part of a std container of T). More... | |
| class | AnalysisDataParallelOptions |
| Parallelization options for analysis data objects. More... | |
| class | Awh |
| Coupling of the accelerated weight histogram method (AWH) with the system. More... | |
| struct | DensityFittingModuleInfo |
| Information about the density fitting module. More... | |
| class | INNPotModel |
| NNPot Module. More... | |
| class | NNPotTopologyPreprocessor |
| Class responsible for all modifications of the topology during input pre-processing. More... | |
| class | TorchModel |
| Class responsible for loading and evaluating a TorchScript-compiled neural network model. Inherits from NNPotModel. More... | |
| class | CommandLineHelpContext |
| Context information for writing out command-line help. More... | |
| class | GlobalCommandLineHelpContext |
| Helper for passing CommandLineHelpContext into parse_common_args(). More... | |
| class | CommandLineHelpWriter |
| Writes help information for Options. More... | |
| class | ICommandLineModule |
| Module that can be run from command line using CommandLineModuleManager. More... | |
| class | CommandLineModuleManager |
| Implements a wrapper command-line interface for multiple modules. More... | |
| class | CommandLineModuleGroup |
| Handle to add content to a group added with CommandLineModuleManager::addModuleGroup(). More... | |
| class | CommandLineModuleSettings |
| Settings to pass information between a module and the general runner. More... | |
| class | ICommandLineOptionsModuleSettings |
| Settings to pass information between a CommandLineOptionsModule and generic code that runs it. More... | |
| class | ICommandLineOptionsModule |
| Module that can be run from a command line and uses gmx::Options for argument processing. More... | |
| class | CommandLineParser |
| Implements command-line parsing for Options objects. More... | |
| class | IExecutableEnvironment |
| Allows customization of the way various directories are found by CommandLineProgramContext. More... | |
| class | CommandLineProgramContext |
| Program context implementation for command line programs. More... | |
| class | TrajectoryFileOpener |
| Low level method to take care of only file opening and closing. More... | |
| class | TrajectoryFrameWriter |
| Writes coordinate frames to a sink, e.g. a trajectory file. More... | |
| class | ProcessFrameConversion |
| ProcessFrameConversion class for handling the running of several analysis steps. More... | |
| class | IFrameConverter |
| IFrameConverter interface for manipulating coordinate information. More... | |
| class | IOutputAdapter |
| OutputAdapter class for handling trajectory file flag setting and processing. More... | |
| class | OutputAdapterContainer |
| Storage for output adapters that modify the state of a t_trxframe object. More... | |
| class | OutputSelector |
| OutputSelector class controls setting which coordinates are actually written. More... | |
| class | SetAtoms |
| SetAtoms class controls availability of atoms data. More... | |
| class | SetBox |
| Allows changing box information when writing a coordinate file. More... | |
| class | SetForces |
| SetForces class allows changing writing of forces to file. More... | |
| class | SetPrecision |
| SetPrecision class allows changing file writing precision. More... | |
| class | SetStartTime |
| SetStartTime class allows changing trajectory time information. More... | |
| class | SetTimeStep |
| SetTimeStep class allows changing trajectory time information. More... | |
| class | SetVelocities |
| SetVelocities class allows changing writing of velocities to file. More... | |
| class | OutputRequirementOptionDirector |
| Container for the user input values that will be used by the builder to determine which OutputAdapters should/could/will be registered to the coordinate file writer. More... | |
| struct | OutputRequirements |
| Finalized version of requirements after processing. More... | |
| class | DomainDecompositionBuilder |
| Builds a domain decomposition management object. More... | |
| struct | ZoneCorners |
| The upper corners of a zone, used for computing which halo clusters need to be sent. More... | |
| class | FixedCapacityVector |
| Vector that behaves likes std::vector but has fixed capacity. More... | |
| class | HashedMap |
| Unordered key to value mapping. More... | |
| class | FusedGpuHaloExchange |
| NVSHMEM-based fused GPU halo exchange. More... | |
| class | GpuHaloExchange |
| Manages GPU Halo Exchange object. More... | |
| class | GpuHaloExchangeNvshmemHelper |
| Handles NVSHMEM aspects of GPU Halo exchange. More... | |
| struct | HaloMpiRequests |
| Storage for MPI request for halo MPI receive and send operations. More... | |
| class | HaloExchange |
| Handles the halo communication of coordinates and forces. More... | |
| class | LocalAtomSet |
| A local atom set collects local, global and collective indices of the home atoms on a rank. The indices of the home atoms are automatically updated during domain decomposition, thus gmx::LocalAtomSet::localIndex enables iteration over local atoms properties like coordinates or forces. TODO: add a LocalAtomSet iterator. More... | |
| class | LocalAtomSetManager |
| Hands out handles to local atom set indices and triggers index recalculation for all sets upon domain decomposition if run in parallel. More... | |
| class | LocalTopologyChecker |
| Has responsibility for checking that the local topology distributed across domains describes a total number of bonded interactions that matches the system topology. More... | |
| struct | DomdecOptions |
| Structure containing all (command line) options for the domain decomposition. More... | |
| class | EnergyAnalysisFrame |
| Class describing an energy frame, that is the all the data stored for one energy term at one time step in an energy file. More... | |
| class | EnergyTerm |
| Class describing the whole time series of an energy term. More... | |
| struct | EnergyNameUnit |
| Convenience structure for keeping energy name and unit together. More... | |
| class | IEnergyAnalysis |
| Interface class overloaded by the separate energy modules. More... | |
| class | SeparatePmeRanksPermitted |
| Class for managing usage of separate PME-only ranks. More... | |
| class | PmeForceSenderGpu |
| Manages sending forces from PME-only ranks to their PP ranks. More... | |
| class | PmeLoadBalancing |
| Object to manage PME load balancing. More... | |
| class | PmePpCommGpu |
| Manages communication related to GPU buffers between this PME rank and its PP rank. More... | |
| class | RocfftInitializer |
| Provides RAII-style initialization of rocFFT library. More... | |
| struct | RocfftPlan |
| All the persistent data for planning an executing a 3D FFT. More... | |
| struct | PlanSetupData |
| Helper struct to reduce repetitive code setting up a 3D FFT plan. More... | |
| struct | MDModulesCheckpointReadingDataOnMain |
| Provides the MDModules with the checkpointed data on the main rank. More... | |
| struct | MDModulesCheckpointReadingBroadcast |
| Provides the MDModules with the communication record to broadcast. More... | |
| struct | MDModulesWriteCheckpointData |
| Writing the MDModules data to a checkpoint file. More... | |
| class | H5md |
| Manager of an H5MD filehandle. The class is designed to read/write data according to de Buyl et al., 2014 (https://doi.org/10.1016/j.cpc.2014.01.018) and https://www.nongnu.org/h5md/h5md.html. More... | |
| class | BasicVector |
| C++ class for 3D vectors. More... | |
| class | H5mdDataSetBuilder |
| Builder class for H5md data sets. More... | |
| class | H5mdDataSetBase |
| Class which manages a HDF5 data set handle and associated data. More... | |
| class | H5mdFixedDataSet |
| Class which provides an interface for reading and writing data to data sets of fixed size. More... | |
| class | H5mdFrameDataSet |
| Class which provides an interface for reading and writing frame data to H5mdDataSet objects. More... | |
| class | H5mdScalarFrameDataSet |
| Class which provides an interface for reading and writing scalar frame data to H5mdDataSetBase objects. More... | |
| class | H5mdFrameDataSetBuilder |
| Builder class for framed H5md data sets. More... | |
| class | H5mdCloser |
| Bound closing function created by scope guard helper functions. More... | |
| class | H5mdParticleBlock |
| Class which manages trajectory data inside of a H5md particle group. More... | |
| class | H5mdParticleBlockBuilder |
Builder class for H5mdParticleBlock objects. More... | |
| class | H5mdTimeDataBlockBuilder |
Builder class to create new H5mdTimeDataBlock objects. More... | |
| class | H5mdTimeDataBlock |
Class which manages time-dependent data sets of the templated ValueType. More... | |
| class | MrcDensityMapOfFloatReader |
| Read an mrc/ccp4 file that contains float values. More... | |
| class | MrcDensityMapOfFloatFromFileReader |
| Read an mrc density map from a given file. More... | |
| class | MrcDensityMapOfFloatWriter |
| Write an mrc/ccp4 file that contains float values. More... | |
| struct | MrcDataStatistics |
| Statistics about mrc data arrays. More... | |
| struct | MrcDensitySkewData |
| Skew matrix and translation. As named in "EMDB Map Distribution Format Description Version 1.01 (c) emdatabank.org 2014". More... | |
| struct | CrystallographicLabels |
| Crystallographic labels for mrc data. More... | |
| struct | MrcDensityMapHeader |
| A container for the data in mrc density map file formats. More... | |
| class | FmmMdpOptions |
| MDP option provider that manages all FMM backends. More... | |
| class | FmmMdpValidator |
| Validates FMM-related MDP settings during preprocessing. More... | |
| class | FmmForceProviderBuilder |
| Helper class to configure and construct FMM Force Provider. More... | |
| struct | IFmmOptions |
| Interface for FMM option sets used in MDP handling. More... | |
| class | ListOfLists |
| A list of lists, optimized for performance. More... | |
| struct | GpuConfigurationCapabilities |
| Collection of GPU capabilities for this configuration. More... | |
| class | ClfftInitializer |
| Handle clFFT library init and tear down in RAII style also with mutual exclusion. More... | |
| class | DeviceStreamManager |
| Device stream and context manager. More... | |
| class | HostAllocationPolicy |
| Policy class for configuring gmx::Allocator, to manage allocations of memory that may be needed for e.g. GPU transfers. More... | |
| class | NvshmemManager |
| Duplicates the communicator and initializes NVSHMEM over it. This is a collective call for all the ranks in the given MPI comm. After NVSHMEM initialization all NVSHMEM APIs can be safely used. More... | |
| struct | OpenClTraits |
| Stub for OpenCL type traits. More... | |
| struct | OpenClTraitsBase |
| Implements common trait infrastructure for OpenCL types. More... | |
| struct | OpenClTraits< cl_context > |
| Implements traits for cl_context. More... | |
| struct | OpenClTraits< cl_command_queue > |
| Implements traits for cl_command_queue. More... | |
| struct | OpenClTraits< cl_program > |
| Implements traits for cl_program. More... | |
| struct | OpenClTraits< cl_kernel > |
| Implements traits for cl_kernel. More... | |
| class | ClHandle |
Wrapper of OpenCL type cl_type to implement RAII. More... | |
| class | CpuInfo |
| Detect CPU capabilities and basic logical processor info. More... | |
| class | HardwareTopology |
| Information about packages, cores, processing units, numa, caches. More... | |
| struct | InteractiveMolecularDynamicsModuleInfo |
| Information about the interactive molecular dynamics module. More... | |
| struct | EnumerationArray |
| Wrapper for a C-style array with size and indexing defined by an enum. Useful for declaring arrays of enum names for debug or other printing. An ArrayRef<DataType> may be constructed from an object of this type. More... | |
| class | ArrayRefWithPadding |
| Interface to a C array of T (or part of a std container of T), that includes padding that is suitable for the kinds of SIMD operations GROMACS uses. More... | |
| class | TranslateAndScale |
| Transform coordinates in three dimensions by first translating, then scaling them. More... | |
| class | AffineTransformation |
| Affine transformation of three-dimensional coordinates. More... | |
| class | DensitySimilarityMeasure |
| Measure similarity and gradient between densities. More... | |
| class | DensityFittingForce |
| Manages evaluation of density-fitting forces for particles that were spread with a kernel. More... | |
| struct | ExponentialMovingAverageState |
| Store the state of exponential moving averages. More... | |
| class | ExponentialMovingAverage |
| Evaluate the exponential moving average with bias correction. More... | |
| struct | GaussianSpreadKernelParameters |
| Parameters for density spreading kernels. More... | |
| class | GaussTransform3D |
Sums Gaussian values at three dimensional lattice coordinates. The Gaussian is defined as 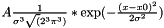 . More... . More... | |
| class | BasicMatrix3x3 |
| Three-by-three matrix of ElementType. More... | |
| class | MultiDimArray |
| Multidimensional array that manages its own memory. More... | |
| class | PaddedVector |
| PaddedVector is a container of elements in contiguous storage that allocates extra memory for safe SIMD-style loads for operations used in GROMACS. More... | |
| class | CheckpointHandler |
| Class handling the checkpoint signal. More... | |
| class | Constraints |
| Handles constraints. More... | |
| struct | AtomPair |
| A pair of atoms indexes. More... | |
| class | MDAtoms |
| Contains a C-style t_mdatoms while managing some of its memory with C++ vectors with allocators. More... | |
| class | ResetHandler |
| Class handling the reset of counters. More... | |
| class | SettleData |
| Data for executing SETTLE constraining. More... | |
| struct | shakedata |
| Working data for the SHAKE algorithm. More... | |
| class | SimulationSignal |
| POD-style object used by mdrun ranks to set and receive signals within and between simulations. More... | |
| class | SimulationSignaller |
| Object used by mdrun ranks to signal to each other at this step. More... | |
| class | StopHandler |
| Class handling the stop signal. More... | |
| class | StopConditionSignal |
| Class setting the stop signal based on gmx_get_stop_condition() More... | |
| class | StopConditionTime |
| Class setting the stop signal based on maximal run time. More... | |
| class | StopHandlerBuilder |
| Class preparing the creation of a StopHandler. More... | |
| class | Update |
| Contains data for update phase. More... | |
| class | UpdateGroups |
| Owns the update grouping and related data. More... | |
| class | Range |
| Defines a range of integer numbers and accompanying operations. More... | |
| class | UpdateGroupsCog |
| Class for managing and computing centers of geometry of update groups. More... | |
| class | VirtualSitesHandler |
| Class that handles construction of vsites and spreading of vsite forces. More... | |
| class | WholeMoleculeTransform |
| This class manages a coordinate buffer with molecules not split over periodic boundary conditions for use in force calculations which require whole molecules. More... | |
| class | BinaryInformationSettings |
| Settings for printBinaryInformation(). More... | |
| class | LegacyMdrunOptions |
| This class provides the same command-line option functionality to both CLI and API sessions. More... | |
| class | MDModules |
| Manages the collection of all modules used for mdrun. More... | |
| class | MembedHolder |
| Membed SimulatorBuilder parameter type. More... | |
| class | Mdrunner |
| Runner object for supporting setup and execution of mdrun. More... | |
| class | MdrunnerBuilder |
| Build a gmx::Mdrunner. More... | |
| class | SimulationContext |
| Simulation environment and configuration. More... | |
| struct | SimulatorConfig |
| Simulation configuation settings. More... | |
| struct | SimulatorStateData |
| Data for a specific simulation state. More... | |
| class | SimulatorEnv |
| Collection of environmental information for a simulation. More... | |
| class | Profiling |
| Collection of profiling information. More... | |
| class | ConstraintsParam |
| Collection of constraint parameters. More... | |
| class | LegacyInput |
| Collection of legacy input information. More... | |
| class | InteractiveMD |
| SimulatorBuilder parameter type for InteractiveMD. More... | |
| class | IonSwapping |
| Parameter type for IonSwapping SimulatorBuilder component. More... | |
| class | TopologyData |
| Collection of handles to topology information. More... | |
| class | BoxDeformationHandle |
| Handle to information about the box. More... | |
| class | SimulatorBuilder |
| Class preparing the creation of Simulator objects. More... | |
| class | MDModulesNotifier |
| Organizes notifications about an event of interest to modules. More... | |
| struct | BuildMDModulesNotifier< CurrentCallParameter, CallParameter...> |
| Template specialization to assemble MDModulesNotifier. More... | |
| struct | MDModulesAtomsRedistributedSignal |
| Notification that atoms may have been redistributed. More... | |
| struct | MDModulesPairlistConstructedSignal |
| Notification that the atom pair list has be (re)constructed. More... | |
| struct | MDModulesEnergyOutputToDensityFittingRequestChecker |
| Check if module outputs energy to a specific field. More... | |
| struct | MDModulesEnergyOutputToQMMMRequestChecker |
| Check if QMMM module outputs energy to a specific field. More... | |
| struct | MDModulesEnergyOutputToNNPotRequestChecker |
| Check if NNPot module outputs energy to a specific field. More... | |
| struct | MDModulesDirectProvider |
| Indicates whether an MD module is a direct (short-range coulomb interactions) provider. More... | |
| class | EnergyCalculationFrequencyErrors |
| Collect errors for the energy calculation frequency. More... | |
| struct | SimulationTimeStep |
| Provides the simulation time step in ps. More... | |
| struct | CoordinatesAndBoxPreprocessed |
| Provides coordinates and simulation box. More... | |
| struct | MdRunInputFilename |
| Mdrun input filename. More... | |
| struct | EdrOutputFilename |
| Energy trajectory output filename from Mdrun. More... | |
| struct | QMInputFileName |
| Notification for QM program input filename provided by user as command-line argument for grompp. More... | |
| struct | PlumedInputFilename |
| Notification for the optional plumed input filename provided by user as command-line argument for mdrun. More... | |
| struct | EnsembleTemperature |
| Provides the constant ensemble temperature. More... | |
| struct | MdModulesCoulombTypeInfo |
| Provides Coulomb interaction type info to MD modules. More... | |
| struct | MDModulesNotifiers |
| Group of notifers to organize that MDModules can receive callbacks they subscribe to. More... | |
| class | PlainPairlistRanges |
| Gathers pairlist range requests from different MDModules. More... | |
| class | accessor_basic |
| The most basic memory access model for mdspan. More... | |
| class | extents |
| Multidimensional extents with static and dynamic dimensions. More... | |
| class | layout_right |
| Right-aligned array layout indexer. Carries the mapping class performing the translation from multidimensional index to one-dimensional number. More... | |
| class | basic_mdspan |
| Multidimensional array indexing and memory access with flexible mapping and access model. More... | |
| class | CheckpointData |
| } More... | |
| struct | IsSerializableEnum |
| { More... | |
| class | ReadCheckpointDataHolder |
| Holder for read checkpoint data. More... | |
| class | WriteCheckpointDataHolder |
| Holder for write checkpoint data. More... | |
| class | ForceBuffersView |
| A view of the force buffer. More... | |
| class | ForceBuffers |
| Object that holds the force buffers. More... | |
| class | ForceWithShiftForces |
| Container for force and virial for algorithms that compute shift forces for virial calculation. More... | |
| class | ForceWithVirial |
| Container for force and virial for algorithms that provide their own virial tensor contribution. More... | |
| class | ForceOutputs |
| Force and virial output buffers for use in force computation. More... | |
| class | ForceProviderInput |
| Helper struct that bundles data for passing it over to the force providers. More... | |
| class | ForceProviderOutput |
| Helper struct bundling the output data of a force provider. More... | |
| class | IForceProvider |
| Interface for a component that provides forces during MD. More... | |
| class | ForceProviders |
| Evaluates forces from a collection of gmx::IForceProvider. More... | |
| class | IMDModule |
| Extension module for GROMACS simulations. More... | |
| class | IMDOutputProvider |
| Interface for handling additional output files during a simulation. More... | |
| class | IMdpOptionProvider |
| Interface for handling mdp/tpr input to a mdrun module. More... | |
| struct | MtsLevel |
| Setting for a single level for multiple time step integration. More... | |
| struct | GromppMtsOpts |
| Struct for passing the MTS mdp options to setupMtsLevels() More... | |
| class | ObservablesReducerBuilder |
| Builder for ObservablesReducer. More... | |
| class | ObservablesReducer |
| Manage reduction of observables for registered subscribers. More... | |
| class | StepWorkload |
| Describes work done on this domain by the current rank that may change per-step. More... | |
| class | DomainLifetimeWorkload |
| Describes work done on this domain on every step of its lifetime, but which might change after the next domain partitioning. More... | |
| class | SimulationWorkload |
| Manage what computation is required during the simulation. More... | |
| class | ModularSimulator |
| The modular simulator. More... | |
| class | ElementNotFoundError |
| Exception class signalling that a requested element was not found. More... | |
| class | MissingElementConnectionError |
| Exception class signalling that elements were not connected properly. More... | |
| class | SimulationAlgorithmSetupError |
| Exception class signalling that the ModularSimulatorAlgorithm was set up in an incompatible way. More... | |
| class | CheckpointError |
| Exception class signalling an error in reading or writing modular checkpoints. More... | |
| class | EnergyAccumulator |
| Base energy accumulator class, only specializations are used. More... | |
| class | AtomPairlist |
| A plain atom pair list, used only for perturbed non-bonded interactions. More... | |
| struct | BenchmarkSystem |
| Description of the system used for benchmarking. More... | |
| struct | EnergyFunctionProperties |
| Set of boolean constants mimicking preprocessor macros. More... | |
| struct | GridDimensions |
| The physical dimensions of a grid. More... | |
| struct | PlainPairlist |
| A plain pairlist that can contain both normal and excluded pairs. More... | |
| struct | nonbonded_verlet_t |
| Top-level non-bonded data structure for the Verlet-type cut-off scheme. More... | |
| struct | gmx_cache_protect_t |
| Cache-line protection buffer. More... | |
| struct | nbnxn_cj_t |
| This is the actual cluster-pair list j-entry. More... | |
| class | JClusterList |
| Simple j-cluster list. More... | |
| struct | nbnxn_sci_t |
| Grouped pair-list i-unit. More... | |
| struct | nbnxn_im_ei_t |
| Interaction data for a j-group for one warp. More... | |
| struct | nbnxn_cj_packed_t |
| Packed j-cluster list element. More... | |
| class | PackedJClusterList |
| Packed j-cluster list. More... | |
| struct | nbnxn_excl_t |
| Struct for storing the atom-pair interaction bits for a cluster pair in a GPU pairlist. More... | |
| struct | NbnxnPairlistCpu |
| Cluster pairlist type for use on CPUs. More... | |
| class | PairlistSets |
| Contains sets of pairlists. More... | |
| struct | NbnxmPairlistCpuWork |
| Working data for the actual i-supercell during pair search. More... | |
| class | nbnxn_cycle_t |
| Local cycle count struct for profiling. More... | |
| struct | PairsearchWork |
| Thread-local work struct, contains working data for Grid. More... | |
| class | PairSearch |
| Main pair-search struct, contains the grid(s), not the pair-list(s) More... | |
| class | CoulombCalculator |
| Base Coulomb calculator class, only specializations are used. More... | |
| class | CoulombCalculator< KernelCoulombType::RF > |
| Specialized calculator for RF. More... | |
| class | CoulombCalculator< KernelCoulombType::EwaldAnalytical > |
| Specialized calculator for Ewald using an analytic approximation. More... | |
| class | CoulombCalculator< KernelCoulombType::EwaldTabulated > |
| Specialized calculator for Ewald using tabulated functions. More... | |
| class | DiagonalMasker |
| Base Coulomb calculator class, only specializations are used. More... | |
| class | DiagonalMasker< nR, kernelLayout, KernelLayoutClusterRatio::JSizeEqualsISize > |
| Specialized masker for JSizeEqualsISize. More... | |
| class | DiagonalMasker< nR, kernelLayout, KernelLayoutClusterRatio::JSizeIsDoubleISize > |
| Specialized masker for JSizeIsDoubleISize. More... | |
| class | DiagonalMasker< nR, kernelLayout, KernelLayoutClusterRatio::JSizeIsHalfISize > |
| Specialized masker for JSizeIsHalfISize. More... | |
| class | EnergyAccumulator< useEnergyGroups, false > |
| Specialized energy accumulator class for no energy calculation. More... | |
| class | EnergyAccumulator< false, true > |
| Specialized energy accumulator class for energy accumulation without energy groups. More... | |
| class | EnergyAccumulator< true, true > |
| Specialized energy accumulator class for energy accumulation with energy groups. More... | |
| class | EnergyGroupsPerCluster |
| Holds energy group indices for use in EnergyAccumulator<true, true> More... | |
| class | LennardJonesCalculator |
| Base LJ calculator class, only specializations are used. More... | |
| class | LennardJonesCalculator< false, InteractionModifiers::PotShift > |
| Specialized calculator for LJ with potential shift and no energy calculation. More... | |
| class | LennardJonesCalculator< true, InteractionModifiers::PotShift > |
| Specialized calculator for LJ with potential shift and energy calculation. More... | |
| class | LennardJonesCalculator< calculateEnergies, InteractionModifiers::ForceSwitch > |
| Specialized calculator for LJ with force switch. More... | |
| class | LennardJonesCalculator< calculateEnergies, InteractionModifiers::PotSwitch > |
| Specialized calculator for LJ with potential switch. More... | |
| class | NbnxmKernel |
| Class name for NBNXM kernel. More... | |
| class | TextTableFormatter |
| Formats rows of a table for text output. More... | |
| class | HelpManager |
| Helper for providing interactive online help. More... | |
| class | AbstractSimpleHelpTopic |
| Abstract base class for help topics that have simple text and no subtopics. More... | |
| class | AbstractCompositeHelpTopic |
| Abstract base class for help topics that have simple text and subtopics. More... | |
| class | SimpleHelpTopic |
| Template for simple implementation of AbstractSimpleHelpTopic. More... | |
| class | CompositeHelpTopic |
| Template for simple implementation of AbstractCompositeHelpTopic. More... | |
| class | HelpLinks |
| Hyperlink data for writing out help. More... | |
| class | HelpWriterContext |
| Context information for writing out help. More... | |
| class | IHelpTopic |
| Provides a single online help topic. More... | |
| class | AbstractOptionStorage |
| Abstract base class for converting, validating, and storing option values. More... | |
| class | AbstractOptionSection |
| Base class for specifying option section properties. More... | |
| class | AbstractOptionSectionHandle |
| Base class for handles to option sections. More... | |
| class | OptionsBehaviorCollection |
| Container for IOptionsBehavior objects. More... | |
| class | OptionManagerContainer |
| Container to keep managers added with Options::addManager() and pass them to options. More... | |
| class | OptionsAssigner |
| Decorator class for assigning values to Options. More... | |
| class | OptionSection |
| Declares a simple option section. More... | |
| class | OptionSectionHandle |
| Allows adding options to an OptionSection. More... | |
| class | OptionStorageTemplate |
| Templated base class for constructing option value storage classes. More... | |
| class | OptionStorageTemplateSimple |
| Simplified option storage template for options that have one-to-one value conversion. More... | |
| class | OptionsVisitor |
| Pure interface for visiting options in a Options object. More... | |
| class | OptionsTypeVisitor |
| Abstract base class for visiting options of a particular type. More... | |
| class | OptionsIterator |
| Decorator class for visiting options in a Options object. More... | |
| class | OptionsModifyingVisitor |
| Pure interface for visiting options in a Options object, allowing modifications. More... | |
| class | OptionsModifyingTypeVisitor |
| Abstract base class for visiting options of a particular type, allowing modifications. More... | |
| class | OptionsModifyingIterator |
| Decorator class for visiting options in a Options object, allowing changes. More... | |
| class | RepeatingOptionSectionHandle |
| Allows adding options to an RepeatingOptionSection. More... | |
| class | RepeatingOptionSection |
| Declares an option section that creates a structure for each instance. More... | |
| class | OptionValueConverterSimple |
| Helper for converting from Any to a given type. More... | |
| class | PullCoordExpressionParser |
| Class with a mathematical expression and parser. More... | |
| class | ExponentialDistribution |
| Exponential distribution. More... | |
| class | GammaDistribution |
| Gamma distribution. More... | |
| class | NormalDistribution |
| Normal distribution. More... | |
| class | TabulatedNormalDistribution |
| Tabulated normal random distribution. More... | |
| class | ThreeFry2x64General |
| General implementation class for ThreeFry counter-based random engines. More... | |
| class | ThreeFry2x64 |
| ThreeFry2x64 random engine with 20 iteractions. More... | |
| class | ThreeFry2x64Fast |
| ThreeFry2x64 random engine with 13 iteractions. More... | |
| class | UniformIntDistribution |
| Uniform integer distribution. More... | |
| class | UniformRealDistribution |
| Uniform real distribution. More... | |
| class | RestraintManager |
| Manage the Restraint potentials available for Molecular Dynamics. More... | |
| class | RestraintMDModule |
| MDModule wrapper for Restraint implementations. More... | |
| class | Site |
| Abstraction for a restraint interaction site. More... | |
| class | SelectionFileOption |
| Specifies a special option that provides selections from a file. More... | |
| class | SelectionFileOptionInfo |
| Wrapper class for accessing and modifying selection file option information. More... | |
| class | ISerializer |
| Interface for types that convert standard data types into a form suitable for storage or transfer. More... | |
| class | Simd4Double |
| SIMD4 double type. More... | |
| class | Simd4DBool |
| SIMD4 variable type to use for logical comparisons on doubles. More... | |
| class | Simd4Float |
| SIMD4 float type. More... | |
| class | Simd4FBool |
| SIMD4 variable type to use for logical comparisons on floats. More... | |
| class | SimdDouble |
| Double SIMD variable. Available if GMX_SIMD_HAVE_DOUBLE is 1. More... | |
| class | SimdDInt32 |
| Integer SIMD variable type to use for conversions to/from double. More... | |
| class | SimdDBool |
| Boolean type for double SIMD data. More... | |
| class | SimdDIBool |
| Boolean type for integer datatypes corresponding to double SIMD. More... | |
| class | SimdFloat |
| Float SIMD variable. Available if GMX_SIMD_HAVE_FLOAT is 1. More... | |
| class | SimdFInt32 |
| Integer SIMD variable type to use for conversions to/from float. More... | |
| class | SimdFBool |
| Boolean type for float SIMD data. More... | |
| class | SimdFIBool |
| Boolean type for integer datatypes corresponding to float SIMD. More... | |
| struct | SimdFloatTag |
| Tag type to select to load SimdFloat with simdLoad(U) More... | |
| struct | SimdDoubleTag |
| Tag type to select to load SimdDouble with simdLoad(U) More... | |
| struct | SimdFInt32Tag |
| Tag type to select to load SimdFInt32 with simdLoad(U) More... | |
| struct | SimdDInt32Tag |
| Tag type to select to load SimdDInt32 with simdLoad(U) More... | |
| struct | AlignedArray< float, N > |
| Identical to std::array with GMX_SIMD_FLOAT_WIDTH alignment. Should not be deleted through base pointer (destructor is non-virtual). More... | |
| struct | AlignedArray< double, N > |
| Identical to std::array with GMX_SIMD_DOUBLE_WIDTH alignment. Should not be deleted through base pointer (destructor is non-virtual). More... | |
| class | SimdSetZeroProxy |
| Proxy object to enable setZero() for SIMD and real types. More... | |
| class | CubicSplineTable |
| Cubic spline interpolation table. More... | |
| class | QuadraticSplineTable |
| Quadratic spline interpolation table. More... | |
| struct | AnalyticalSplineTableInput |
| Specification for analytical table function (name, function, derivative) More... | |
| struct | NumericalSplineTableInput |
| Specification for vector table function (name, function, derivative, spacing) More... | |
| struct | DevelopmentFeatureFlags |
| Structure that holds boolean flags corresponding to the development features present enabled through environment variables. More... | |
| struct | GpuTaskMapping |
| Specifies the GPU deviceID_ available for task_ to use. More... | |
| class | GpuTaskAssignmentsBuilder |
| Builder for the GpuTaskAssignments for all ranks on this node. More... | |
| class | GpuTaskAssignments |
| Contains the GPU task assignment for all ranks on this physical node. More... | |
| class | ConvertTprInfo |
| Declares gmx convert-tpr. More... | |
| struct | ExclusionBlock |
| Describes exclusions for a single atom. More... | |
| class | UnionFinder |
| Union-find data structure for keeping track of disjoint sets. More... | |
| class | MappedUnionFinder |
| Extension of UnionFind that supports non-consecutive integer indices as items. More... | |
| class | AlignedAllocationPolicy |
| Policy class for configuring gmx::Allocator, to manage allocations of aligned memory for SIMD code. More... | |
| class | PageAlignedAllocationPolicy |
| Policy class for configuring gmx::Allocator, to manage allocations of page-aligned memory that can be locked for asynchronous transfer to GPU devices. More... | |
| class | Allocator |
| Policy-based memory allocator. More... | |
| class | Any |
| Represents a dynamically typed value of an arbitrary type - deprecated. More... | |
| struct | BoolType |
| A clone of a bool as a workaround on the template specialization of std::vector<bool> that is incompatible with ArrayRef. More... | |
| class | DataFileOptions |
| Search parameters for DataFileFinder. More... | |
| struct | DataFileInfo |
| Information about a data file found by DataFileFinder::enumerateFiles(). More... | |
| class | DataFileFinder |
| Searches data files from a set of paths. More... | |
| class | DefaultInitializationAllocator |
| Allocator adaptor that interposes construct() calls to convert value initialization into default initialization. More... | |
| class | DirectoryEnumerator |
| Lists files in a directory. More... | |
| class | IFileInputRedirector |
| Allows overriding file existence checks from code that supports it. More... | |
| class | IFileOutputRedirector |
Allows capturing stdout and file output from code that supports it. More... | |
| class | StandardInputStream |
Text input stream implementation for reading from stdin. More... | |
| class | TextInputFile |
| Text input stream implementation for reading from a file. More... | |
| class | TextOutputFile |
| Text output stream implementation for writing to a file. More... | |
| class | KeyValueTreePath |
| Identifies an entry in a key-value tree. More... | |
| class | KeyValueTreeBuilder |
| Root builder for creating trees that have an object at the root. More... | |
| class | KeyValueTreeValueBuilder |
| Builder for KeyValueTreeValue objects. More... | |
| class | KeyValueTreeUniformArrayBuilder |
Builder for KeyValueTreeArray objects where all elements are of type T. More... | |
| class | KeyValueTreeObjectArrayBuilder |
| Builder for KeyValueTreeArray objects where all elements are KeyValueTreeObject objects. More... | |
| class | KeyValueTreeObjectBuilder |
| Builder for KeyValueTreeObject objects. More... | |
| class | IKeyValueTreeTransformRules |
| Interface to declare rules for transforming key-value trees. More... | |
| class | KeyValueTreeTransformRulesScoped |
| Helper object returned from IKeyValueTreeTransformRules::scopedTransform(). More... | |
| class | KeyValueTreeTransformRuleBuilder |
| Provides methods to specify one transformation rule. More... | |
| class | ILogTarget |
| Target where log output can be written. More... | |
| class | LogEntryWriter |
| Helper class for creating log entries with GMX_LOG. More... | |
| class | LogLevelHelper |
| Represents a single logging level. More... | |
| class | MDLogger |
| Declares a logging interface. More... | |
| class | LoggerBuilder |
| Initializes loggers. More... | |
| class | LoggerOwner |
| Manages memory for a logger built with LoggerBuilder. More... | |
| class | MessageStringCollector |
| Helper class for collecting message strings, optionally with context. More... | |
| class | MessageStringContext |
| Convenience class for creating a message context. More... | |
| class | PhysicalNodeCommunicator |
| Holds a communicator for the physical node of this rank. More... | |
| class | StringCompare |
| Compare object for std::string STL containers and algorithms that supports run-time decision on how to compare. More... | |
| class | StringOutputStream |
| Text output stream implementation for writing to an in-memory string. More... | |
| class | StringInputStream |
| Helper class to convert static string data to a stream. More... | |
| class | StringToEnumValueConverter |
A class to convert a string to an enum value of type EnumType. More... | |
| class | TextReader |
| Reads text from a TextInputStream. More... | |
| class | TextInputStream |
| Interface for reading text. More... | |
| class | TextOutputStream |
| Interface for writing text. More... | |
| class | ScopedIndenter |
| Helper class to increase the indentation of a TextWriter for the lifetime of this object. More... | |
| class | TextWriter |
| Writes text into a TextOutputStream. More... | |
| struct | isIntegralConstant |
| Is true if type is a std::integral_constant. More... | |
| class | MpiComm |
| MPI communicator with optimized reduction functionality. More... | |
| struct | no_delete |
| Deleter for std::shared_ptr that does nothing. More... | |
| class | NonbondedBenchmarkInfo |
| Declares gmx nonbonded-bench. More... | |
| class | AbstractAnalysisData |
| Abstract base class for all objects that provide data. More... | |
| class | AnalysisData |
| Parallelizable data container for raw data. More... | |
| class | AnalysisDataHandle |
| Handle for inserting data into AnalysisData. More... | |
| class | AbstractAnalysisArrayData |
| Abstract base class for data objects that present in-memory data. More... | |
| class | AnalysisArrayData |
| Simple in-memory data array. More... | |
| class | AnalysisDataValue |
| Value type for representing a single value in analysis data objects. More... | |
| class | AnalysisDataFrameHeader |
| Value type for storing frame-level information for analysis data. More... | |
| class | AnalysisDataPointSetRef |
| Value type wrapper for non-mutable access to a set of data column values. More... | |
| class | AnalysisDataFrameRef |
| Value type wrapper for non-mutable access to a data frame. More... | |
| class | IAnalysisDataModule |
| Interface for a module that gets notified whenever data is added. More... | |
| class | AnalysisDataModuleSerial |
| Convenience base class for serial analysis data modules. More... | |
| class | AnalysisDataModuleParallel |
| Convenience base class for parallel analysis data modules. More... | |
| class | AnalysisDataAverageModule |
| Data module for independently averaging each column in input data. More... | |
| class | AnalysisDataFrameAverageModule |
| Data module for averaging of columns for each frame. More... | |
| class | AnalysisDataDisplacementModule |
| Data module for calculating displacements. More... | |
| class | AnalysisHistogramSettingsInitializer |
| Provides "named parameter" idiom for constructing histograms. More... | |
| class | AnalysisHistogramSettings |
| Contains parameters that specify histogram bin locations. More... | |
| class | AbstractAverageHistogram |
| Base class for representing histograms averaged over frames. More... | |
| class | AnalysisDataSimpleHistogramModule |
| Data module for per-frame histograms. More... | |
| class | AnalysisDataWeightedHistogramModule |
| Data module for per-frame weighted histograms. More... | |
| class | AnalysisDataBinAverageModule |
| Data module for bin averages. More... | |
| class | AnalysisDataLifetimeModule |
| Data module for computing lifetime histograms for columns in input data. More... | |
| class | AnalysisDataPlotSettings |
| Common settings for data plots. More... | |
| class | AbstractPlotModule |
| Abstract data module for writing data into a file. More... | |
| class | AnalysisDataPlotModule |
| Plotting module for straightforward plotting of data. More... | |
| class | AnalysisDataVectorPlotModule |
| Plotting module specifically for data consisting of vectors. More... | |
| struct | StaticLog2 |
| Evaluate log2(n) for integer n statically at compile time. More... | |
| struct | StaticLog2< 1 > |
| Specialization of StaticLog2<n> for n==1. More... | |
| struct | StaticLog2< 0 > |
| Specialization of StaticLog2<n> for n==0. More... | |
| class | AbstractOption |
| Abstract base class for specifying option properties. More... | |
| class | OptionTemplate |
| Templated base class for constructing concrete option settings classes. More... | |
| class | OptionInfo |
| Gives information and allows modifications to an option after creation. More... | |
| class | BooleanOption |
| Specifies an option that provides boolean values. More... | |
| class | IntegerOption |
| Specifies an option that provides 32-bit integer values. More... | |
| class | UnsignedIntegerOption |
| Specifies an option that provides unsigned 32-bit integer values. More... | |
| class | Int64Option |
| Specifies an option that provides 64-bit integer values. More... | |
| class | UnsignedInt64Option |
| Specifies an option that provides 64-bit unsigned integer values. More... | |
| class | DoubleOption |
| Specifies an option that provides floating-point (double) values. More... | |
| class | FloatOption |
| Specifies an option that provides floating-point (float) values. More... | |
| class | StringOption |
| Specifies an option that provides string values. More... | |
| class | EnumOption |
Specifies an option that accepts an EnumerationArray of string values and writes the selected index into an enum variable. More... | |
| class | LegacyEnumOption |
Specifies an option that accepts enumerated string values and writes the selected index into an enum variable. More... | |
| class | BooleanOptionInfo |
| Wrapper class for accessing boolean option information. More... | |
| class | IntegerOptionInfo |
| Wrapper class for accessing 32-bit integer option information. More... | |
| class | UnsignedIntegerOptionInfo |
| Wrapper class for accessing unsigned 32-bit integer option information. More... | |
| class | Int64OptionInfo |
| Wrapper class for accessing 64-bit integer option information. More... | |
| class | UnsignedInt64OptionInfo |
| Wrapper class for accessing 64-bit unsigned integer option information. More... | |
| class | DoubleOptionInfo |
| Wrapper class for accessing floating-point option information. More... | |
| class | FloatOptionInfo |
| Wrapper class for accessing floating-point option information. More... | |
| class | StringOptionInfo |
| Wrapper class for accessing string option information. More... | |
| class | EnumOptionInfo |
| Wrapper class for accessing enum option information. More... | |
| class | FileNameOption |
| Specifies an option that provides file names. More... | |
| class | FileNameOptionInfo |
| Wrapper class for accessing file name option information. More... | |
| class | FileNameOptionManager |
| Handles interaction of file name options with global options. More... | |
| class | IOptionsBehavior |
| Interface to provide extension points for options parsing. More... | |
| class | IOptionsContainer |
| Interface for adding input options. More... | |
| class | IOptionsContainerWithSections |
| Interface for adding input options with sections. More... | |
| class | IOptionManager |
| Base class for option managers. More... | |
| class | Options |
| Collection of options. More... | |
| class | TimeUnitManager |
| Provides common functionality for time unit conversions. More... | |
| class | TimeUnitBehavior |
| Options behavior to add a time unit option. More... | |
| class | PotentialPointData |
| Structure to hold the results of IRestraintPotential::evaluate(). More... | |
| class | IRestraintPotential |
| Interface for Restraint potentials. More... | |
| class | AnalysisNeighborhoodPositions |
| Input positions for neighborhood searching. More... | |
| class | AnalysisNeighborhood |
| Neighborhood searching for analysis tools. More... | |
| class | AnalysisNeighborhoodPair |
| Value type to represent a pair of positions found in neighborhood searching. More... | |
| class | AnalysisNeighborhoodSearch |
| Initialized neighborhood search with a fixed set of reference positions. More... | |
| class | AnalysisNeighborhoodPairSearch |
| Initialized neighborhood pair search with a fixed set of positions. More... | |
| class | Selection |
| Provides access to a single selection. More... | |
| class | SelectionPosition |
| Provides access to information about a single selected position. More... | |
| class | SelectionCollection |
| Collection of selections. More... | |
| struct | SelectionTopologyProperties |
| Describes topology properties required for selection evaluation. More... | |
| class | SelectionOption |
| Specifies an option that provides selection(s). More... | |
| class | SelectionOptionInfo |
| Wrapper class for accessing and modifying selection option information. More... | |
| class | ITopologyProvider |
| Provides topology information to SelectionOptionBehavior. More... | |
| class | SelectionOptionBehavior |
| Options behavior to allow using SelectionOptions. More... | |
| class | SelectionOptionManager |
| Handles interaction of selection options with other options and user input. More... | |
| class | RangePartitioning |
| Division of a range of indices into consecutive blocks. More... | |
| class | TrajectoryAnalysisModuleData |
| Base class for thread-local data storage during trajectory analysis. More... | |
| class | TrajectoryAnalysisModule |
| Base class for trajectory analysis modules. More... | |
| class | TrajectoryAnalysisSettings |
| Trajectory analysis module configuration object. More... | |
| class | TrajectoryAnalysisCommandLineRunner |
| Runner for command-line trajectory analysis tools. More... | |
| class | TopologyInformation |
| Topology information available to a trajectory analysis module. More... | |
| class | EnumerationIterator |
| Allows iterating sequential enumerators. More... | |
| class | EnumerationWrapper |
| Allows constructing iterators for looping over sequential enumerators. More... | |
| class | EnumClassSuitsEnumerationArray |
| Helper class to determine whether a template type that is an enum class has a Count field. More... | |
| class | ExceptionInfo |
| Stores additional context information for exceptions. More... | |
| class | ExceptionInitializer |
| Provides information for Gromacs exception constructors. More... | |
| class | GromacsException |
| Base class for all exception objects in Gromacs. More... | |
| class | FileIOError |
| Exception class for file I/O errors. More... | |
| class | UserInputError |
| Exception class for user input errors. More... | |
| class | InvalidInputError |
| Exception class for situations where user input cannot be parsed/understood. More... | |
| class | InconsistentInputError |
| Exception class for situations where user input is inconsistent. More... | |
| class | ToleranceError |
| Exception class when a specified tolerance cannot be achieved. More... | |
| class | SimulationInstabilityError |
| Exception class for simulation instabilities. More... | |
| class | InternalError |
| Exception class for internal errors. More... | |
| class | APIError |
| Exception class for incorrect use of an API. More... | |
| class | RangeError |
| Exception class for out-of-range values or indices. More... | |
| class | NotImplementedError |
| Exception class for use of an unimplemented feature. More... | |
| class | ParallelConsistencyError |
| Exception class for use when ensuring that MPI ranks to throw in a coordinated fashion. More... | |
| class | ModularSimulatorError |
| Exception class for modular simulator. More... | |
| class | MDModuleSetupError |
| Exception class for MD module setup/initialization failures. More... | |
| class | FlagsTemplate |
| Template class for typesafe handling of combination of flags. More... | |
| struct | InstallationPrefixInfo |
| Provides information about installation prefix (see IProgramContext::installationPrefix()). More... | |
| class | IProgramContext |
| Provides context information about the program that is calling the library. More... | |
| class | StringFormatter |
| Function object that wraps a call to formatString() that expects a single conversion argument, for use with algorithms. More... | |
| class | IdentityFormatter |
Function object to implement the same interface as StringFormatter to use with strings that should not be formatted further. More... | |
| class | EqualCaseInsensitive |
Function object for comparisons with equalCaseInsensitive. More... | |
| class | TextLineWrapperSettings |
| Stores settings for line wrapping. More... | |
| class | TextLineWrapper |
| Wraps lines to a predefined length. More... | |
| struct | CompileTimeStringJoin |
| Combines string literals at compile time to final string. More... | |
Typedefs | |
| typedef double | awh_dvec [c_biasMaxNumDim] |
| A real vector in AWH coordinate space. | |
| typedef int | awh_ivec [c_biasMaxNumDim] |
| An integer vector in AWH coordinate space. | |
| using | PairlistEntry = std::pair< std::pair< int, int >, int > |
| typedef int | force_env_t |
| Type for CP2K force environment handle. | |
|
typedef std::unique_ptr < ICommandLineModule > | CommandLineModulePointer |
| Smart pointer type for managing a ICommandLineModule. | |
|
typedef std::map< std::string, CommandLineModulePointer > | CommandLineModuleMap |
| Container type for mapping module names to module objects. | |
|
typedef std::unique_ptr < CommandLineModuleGroupData > | CommandLineModuleGroupDataPointer |
| Smart pointer type for managing a CommandLineModuleGroup. | |
|
typedef std::vector < CommandLineModuleGroupDataPointer > | CommandLineModuleGroupList |
| Container type for keeping a list of module groups. | |
|
typedef std::unique_ptr < ICommandLineOptionsModule > | ICommandLineOptionsModulePointer |
| Smart pointer to manage an ICommandLineOptionsModule. | |
|
typedef std::unique_ptr < IExecutableEnvironment > | ExecutableEnvironmentPointer |
| Shorthand for a smart pointer to IExecutableEnvironment. | |
| using | TrajectoryFrameWriterPointer = std::unique_ptr< TrajectoryFrameWriter > |
| Smart pointer to manage the TrajectoryFrameWriter object. | |
| using | ProcessFrameConversionPointer = std::unique_ptr< ProcessFrameConversion > |
| Smart pointer to manage the analyse object. | |
| using | FrameConverterPointer = std::unique_ptr< IFrameConverter > |
| Typedef to have direct access to the individual FrameConverter modules. | |
| using | OutputAdapterPointer = std::unique_ptr< IOutputAdapter > |
| Smart pointer to manage the frame adapter object. | |
| using | OutputSelectorPointer = std::unique_ptr< OutputSelector > |
| Smart pointer to manage the object. | |
| using | SetAtomsPointer = std::unique_ptr< SetAtoms > |
| Smart pointer to manage the object. | |
| using | SetBoxPointer = std::unique_ptr< SetBox > |
| Smart pointer to manage the object. | |
| using | SetForcesPointer = std::unique_ptr< SetForces > |
| Smart pointer to manage the object. | |
| using | SetPrecisionPointer = std::unique_ptr< SetPrecision > |
| Smart pointer to manage the outputselector object. | |
| using | SetStartTimePointer = std::unique_ptr< SetStartTime > |
| Smart pointer to manage the object. | |
| using | SetTimeStepPointer = std::unique_ptr< SetTimeStep > |
| Smart pointer to manage the object. | |
| using | SetVelocitiesPointer = std::unique_ptr< SetVelocities > |
| Smart pointer to manage the object. | |
| using | EnergyAnalysisFrameIterator = std::vector< EnergyAnalysisFrame >::const_iterator |
| Typedef for looping over EnergyFrame. | |
| using | IEnergyAnalysisPointer = std::unique_ptr< IEnergyAnalysis > |
| Pointer to the EnergyAnalysisModule classes. | |
|
typedef struct gmx::CacheLineAlignedFlag | CacheLineAlignedFlag |
| using | hid_t = int64_t |
| using | DataSetDims = std::vector< hsize_t > |
| Dimensions of a HDF5 data set. More... | |
| using | H5mdCloseType = herr_t(*)(hid_t) |
| Function signature for HDF5 closing functions (H5Gclose, etc.) | |
| using | H5mdGuard = sg::detail::scope_guard< H5mdCloser > |
| Alias for scope guards used in the H5md module. | |
| using | IndexMap = std::unordered_map< int32_t, int32_t > |
| Map the global indices of the selection to the local indices within the selection. | |
| using | BondPairs = std::vector< std::pair< int64_t, int64_t >> |
| List of bond representations as pairs of atom indices. | |
| template<class T > | |
| using | HostAllocator = Allocator< T, HostAllocationPolicy > |
| Memory allocator that uses HostAllocationPolicy. More... | |
| template<class T > | |
| using | HostVector = std::vector< T, HostAllocator< T >> |
| Convenience alias for std::vector that uses HostAllocator. | |
| template<class T > | |
| using | PaddedHostVector = PaddedVector< T, HostAllocator< T >> |
| Convenience alias for PaddedVector that uses HostAllocator. | |
| template<typename T > | |
| using | AlignedVector = std::vector< T, AlignedAllocator< T >> |
| Convenience type for vector with aligned memory. | |
| using | mode = sycl::access_mode |
| using | Matrix3x3 = BasicMatrix3x3< real > |
| Three-by-three real number matrix. More... | |
|
typedef std::array < SimulationSignal, eglsNR > | SimulationSignals |
| Convenience typedef for the group of signals used. | |
| using | VirialHandling = VirtualSitesHandler::VirialHandling |
| VirialHandling is often used outside VirtualSitesHandler class members. | |
|
typedef std::array < std::vector< int > , numFtypes > | VsitePbc |
| Type for storing PBC atom information for all vsite types in the system. | |
| using | SimulatorFunctionType ) = void( |
| Function type for simulator code. | |
| using | LogFilePtr = std::unique_ptr< t_fileio, functor_wrapper< t_fileio, closeLogFile >> |
| Simple guard pointer See unique_cptr for details. | |
| using | dynamicExtents2D = extents< dynamic_extent, dynamic_extent > |
| Convenience type for often-used two dimensional extents. | |
| using | dynamicExtents3D = extents< dynamic_extent, dynamic_extent, dynamic_extent > |
| Convenience type for often-used three dimensional extents. | |
| template<class T , ptrdiff_t... Indices> | |
| using | mdspan = basic_mdspan< T, extents< Indices...>, layout_right, accessor_basic< T >> |
| basic_mdspan with wrapped indices, basic_accessor policiy and right-aligned memory layout. | |
| using | ReadCheckpointData = CheckpointData< CheckpointDataOperation::Read > |
| Convenience shortcut for reading checkpoint data. | |
| using | WriteCheckpointData = CheckpointData< CheckpointDataOperation::Write > |
| Convenience shortcut for writing checkpoint data. | |
| using | Step = int64_t |
| Step number. | |
| typedef std::function< void()> | CheckBondedInteractionsCallback |
| The function type allowing to request a check of the number of bonded interactions. | |
| using | EnergyContribution = std::function< real(Step, Time)> |
| Function type for elements contributing energy. | |
| using | Time = double |
| Simulation time. | |
| typedef std::function< void()> | SimulatorRunFunction |
| The function type that can be scheduled to be run during the simulator run. | |
| typedef std::function< void(SimulatorRunFunction)> | RegisterRunFunction |
| The function type that allows to register run functions. | |
|
typedef std::function< void(Step, Time, const RegisterRunFunction &)> | SchedulingFunction |
| The function type scheduling run functions for a step / time using a RegisterRunFunction reference. | |
|
typedef std::function< void(Step, Time)> | SignallerCallback |
| The function type that can be registered to signallers for callback. | |
|
typedef std::function< void(gmx_mdoutf *, Step, Time, bool, bool)> | ITrajectoryWriterCallback |
| Function type for trajectory writing clients. | |
| typedef std::function< void(Step)> | PropagatorCallback |
| Generic callback to the propagator. | |
| typedef std::function< void()> | DomDecCallback |
| Callback used by the DomDecHelper object to inform clients about system re-partitioning. | |
| using | ReferenceTemperatureCallback = std::function< void(ArrayRef< const real >, ReferenceTemperatureChangeAlgorithm algorithm)> |
| Callback updating the reference temperature. | |
| typedef void(* | KernelFunction )(const AtomPairlist &nlist, const ArrayRefWithPadding< const RVec > &coords, const int ntype, const interaction_const_t &interactionParameters, ArrayRef< const RVec > shiftvec, ArrayRef< const real > nbfp, ArrayRef< const real > nbfp_grid, ArrayRef< const real > chargeA, ArrayRef< const real > chargeB, ArrayRef< const int > typeA, ArrayRef< const int > typeB, const bool computeForeignLambda, const StepWorkload *stepWork, ArrayRef< const real > lambda, t_nrnb *gmx_restrict nrnb, ArrayRefWithPadding< RVec > threadForceBuffer, rvec *threadForceShiftBuffer, ArrayRef< real > threadVCoul, ArrayRef< real > threadVVdw, ArrayRef< real > threadDvdl) |
| using | GpuPairlistByLocality = EnumerationArray< InteractionLocality, std::unique_ptr< GpuPairlist >> |
| using | GpuFeplistByLocality = EnumerationArray< InteractionLocality, std::unique_ptr< GpuFeplist >> |
|
typedef struct gmx::cl_nbparam_params | cl_nbparam_params_t |
| typedef SimdReal | SimdBitMask |
| Define SimdBitMask as a real SIMD register. | |
| using | FCiFloat3 = Float3 |
|
typedef std::unique_ptr < AbstractCompositeHelpTopic > | CompositeHelpTopicPointer |
| Smart pointer type to manage a AbstractCompositeHelpTopic object. | |
|
typedef std::unique_ptr < IHelpTopic > | HelpTopicPointer |
| Smart pointer type to manage a IHelpTopic object. | |
|
typedef std::shared_ptr < IOptionsBehavior > | OptionsBehaviorPointer |
| Smart pointer for behaviors stored in OptionsBehaviorCollection. | |
| typedef std::random_device | RandomDevice |
| Random device. More... | |
| typedef ThreeFry2x64Fast | DefaultRandomEngine |
| Default fast and accurate random engine in Gromacs. More... | |
|
typedef std::list < SelectionParserValue > | SelectionParserValueList |
| Container for a list of SelectionParserValue objects. | |
|
typedef std::unique_ptr < SelectionParserValueList > | SelectionParserValueListPointer |
| Smart pointer type for managing a SelectionParserValueList. | |
|
typedef std::list < SelectionParserParameter > | SelectionParserParameterList |
| Container for a list of SelectionParserParameter objects. | |
|
typedef std::unique_ptr < SelectionParserParameterList > | SelectionParserParameterListPointer |
| Smart pointer type for managing a SelectionParserParameterList. | |
|
typedef std::unique_ptr < internal::SelectionData > | SelectionDataPointer |
| Smart pointer for managing an internal selection data object. | |
|
typedef std::vector < SelectionDataPointer > | SelectionDataList |
| Container for storing a list of selections internally. | |
|
typedef std::shared_ptr < SelectionTreeElement > | SelectionTreeElementPointer |
| Smart pointer type for selection tree element pointers. | |
| using | GpuTasksOnRanks = std::vector< std::vector< GpuTask >> |
| Container of compute tasks suitable to run on a GPU e.g. on each rank of a node. | |
| using | GpuTaskAssignment = std::vector< GpuTaskMapping > |
| Container of GPU tasks on a rank, specifying the task type and GPU device ID, e.g. potentially ready for consumption by the modules on that rank. | |
| template<class T > | |
| using | AlignedAllocator = Allocator< T, AlignedAllocationPolicy > |
| Aligned memory allocator. More... | |
| template<class T > | |
| using | PageAlignedAllocator = Allocator< T, PageAlignedAllocationPolicy > |
| PageAligned memory allocator. More... | |
| template<typename T > | |
| using | FastVector = std::vector< T, DefaultInitializationAllocator< T >> |
| Convenience type for vector that avoids initialization at resize() | |
| using | MPI_Comm_ptr = gmx::unique_cptr< MPI_Comm, MPI_Comm_free_wrapper > |
| Make a smart pointer for MPI communicators. | |
|
typedef std::shared_ptr < TextInputStream > | TextInputStreamPointer |
| Shorthand for a smart pointer to a TextInputStream. | |
|
typedef std::shared_ptr < TextOutputStream > | TextOutputStreamPointer |
| Shorthand for a smart pointer to a TextOutputStream. | |
|
typedef std::shared_ptr < IAnalysisDataModule > | AnalysisDataModulePointer |
| Smart pointer for managing a generic analysis data module. | |
|
typedef ArrayRef< const AnalysisDataValue > | AnalysisDataValuesRef |
| Shorthand for reference to an array of data values. | |
|
typedef std::shared_ptr < AnalysisDataAverageModule > | AnalysisDataAverageModulePointer |
| Smart pointer to manage an AnalysisDataAverageModule object. | |
|
typedef std::shared_ptr < AnalysisDataFrameAverageModule > | AnalysisDataFrameAverageModulePointer |
| Smart pointer to manage an AnalysisDataFrameAverageModule object. | |
|
typedef std::shared_ptr < AnalysisDataDisplacementModule > | AnalysisDataDisplacementModulePointer |
| Smart pointer to manage an AnalysisDataDisplacementModule object. | |
|
typedef std::unique_ptr < AbstractAverageHistogram > | AverageHistogramPointer |
| Smart pointer to manage an AbstractAverageHistogram object. | |
|
typedef std::shared_ptr < AnalysisDataSimpleHistogramModule > | AnalysisDataSimpleHistogramModulePointer |
| Smart pointer to manage an AnalysisDataSimpleHistogramModule object. | |
|
typedef std::shared_ptr < AnalysisDataWeightedHistogramModule > | AnalysisDataWeightedHistogramModulePointer |
| Smart pointer to manage an AnalysisDataWeightedHistogramModule object. | |
|
typedef std::shared_ptr < AnalysisDataBinAverageModule > | AnalysisDataBinAverageModulePointer |
| Smart pointer to manage an AnalysisDataBinAverageModule object. | |
|
typedef std::shared_ptr < AnalysisDataLifetimeModule > | AnalysisDataLifetimeModulePointer |
| Smart pointer to manage an AnalysisDataLifetimeModule object. | |
|
typedef std::shared_ptr < AnalysisDataPlotModule > | AnalysisDataPlotModulePointer |
| Smart pointer to manage an AnalysisDataPlotModule object. | |
|
typedef std::shared_ptr < AnalysisDataVectorPlotModule > | AnalysisDataVectorPlotModulePointer |
| Smart pointer to manage an AnalysisDataVectorPlotModule object. | |
| typedef FloatOption | RealOption |
| Typedef for either DoubleOption or FloatOption, depending on precision. More... | |
| typedef FloatOptionInfo | RealOptionInfo |
| Typedef for either DoubleOptionInfo or FloatOptionInfo, depending on precision. More... | |
| typedef FlagsTemplate< OptionFlag > | OptionFlags |
| Holds a combination of OptionFlag values. | |
| using | Vector = ::gmx::RVec |
| Provide a vector type name with a more stable interface than RVec and a more stable implementation than vec3<>. More... | |
| typedef std::vector< Selection > | SelectionList |
| Container of selections used in public selection interfaces. | |
| using | BoxMatrix = std::array< std::array< real, DIM >, DIM > |
| A 3x3 matrix data type useful for simulation boxes. More... | |
|
typedef std::unique_ptr < TrajectoryAnalysisModuleData > | TrajectoryAnalysisModuleDataPointer |
| Smart pointer to manage a TrajectoryAnalysisModuleData object. | |
|
typedef std::unique_ptr < TrajectoryAnalysisModule > | TrajectoryAnalysisModulePointer |
| Smart pointer to manage a TrajectoryAnalysisModule. | |
| using | Index = std::ptrdiff_t |
| Integer type for indexing into arrays or vectors. More... | |
|
typedef ExceptionInfo< struct ExceptionInfoErrno_, int > | ExceptionInfoErrno |
Stores errno value that triggered the exception. | |
|
typedef ExceptionInfo< struct ExceptionInfoApiFunc_, const char * > | ExceptionInfoApiFunction |
Stores the function name that returned the errno in ExceptionInfoErrno. | |
|
typedef ExceptionInfo< struct ExceptionInfoLocation_, ThrowLocation > | ExceptionInfoLocation |
| Stores the location where the exception was thrown. | |
| using | FilePtr = std::unique_ptr< FILE, functor_wrapper< FILE, fclose_wrapper >> |
| Simple guard pointer which calls fclose. See unique_cptr for details. | |
| template<typename T , void D = sfree_wrapper> | |
| using | unique_cptr = std::unique_ptr< T, functor_wrapper< T, D >> |
| unique_ptr which takes function pointer (has to return void) as template argument | |
| typedef unique_cptr< void > | sfree_guard |
| Simple guard which calls sfree. See unique_cptr for details. | |
| typedef BasicVector< real > | RVec |
Shorthand for C++ rvec-equivalent type. | |
| typedef BasicVector< double > | DVec |
Shorthand for C++ dvec-equivalent type. | |
| typedef BasicVector< int > | IVec |
Shorthand for C++ ivec-equivalent type. | |
| using | ClContext = ClHandle< cl_context > |
| Convenience declarations. | |
| using | ClCommandQueue = ClHandle< cl_command_queue > |
| using | ClProgram = ClHandle< cl_program > |
| using | ClKernel = ClHandle< cl_kernel > |
Enumerations | |
| enum | AwhOutputEntryType { AwhOutputEntryType::MetaData, AwhOutputEntryType::CoordValue, AwhOutputEntryType::Pmf, AwhOutputEntryType::Bias, AwhOutputEntryType::Visits, AwhOutputEntryType::Weights, AwhOutputEntryType::Target, AwhOutputEntryType::SharedForceCorrelationVolume, AwhOutputEntryType::SharedFrictionTensor } |
| Enum with the AWH variables to write. More... | |
| enum | AwhOutputMetaData { AwhOutputMetaData::NumBlock, AwhOutputMetaData::TargetError, AwhOutputMetaData::ScaledSampleWeight, AwhOutputMetaData::Count } |
| Enum with the types of metadata to write. More... | |
| enum | Normalization { Normalization::None, Normalization::Coordinate, Normalization::FreeEnergy, Normalization::Distribution } |
| Enum with different ways of normalizing the output. More... | |
| enum | DensityFittingAmplitudeMethod : int { DensityFittingAmplitudeMethod::Unity, DensityFittingAmplitudeMethod::Mass, DensityFittingAmplitudeMethod::Charge, Count } |
| The methods that determine how amplitudes are spread on a grid in density guided simulations. More... | |
| enum | NNPotEmbedding { NNPotEmbedding::Mechanical, NNPotEmbedding::ElectrostaticModel, Count } |
| Enum to specify embedding scheme used for NNP/MM interaction. More... | |
| enum | QMMMQMMethod { QMMMQMMethod::PBE, QMMMQMMethod::BLYP, QMMMQMMethod::INPUT, Count } |
| Enumerator for supported QM methods Also could be INPUT which means external input file provided with the name determined by QMMMParameters::qminputfilename_. More... | |
| enum | CoordinateFileFlags : unsigned long { CoordinateFileFlags::Base = 1 << 0, CoordinateFileFlags::RequireForceOutput = 1 << 1, CoordinateFileFlags::RequireVelocityOutput = 1 << 2, CoordinateFileFlags::RequireAtomConnections = 1 << 3, CoordinateFileFlags::RequireAtomInformation = 1 << 4, CoordinateFileFlags::RequireChangedOutputPrecision = 1 << 5, CoordinateFileFlags::RequireNewFrameStartTime = 1 << 6, CoordinateFileFlags::RequireNewFrameTimeStep = 1 << 7, CoordinateFileFlags::RequireNewBox = 1 << 8, CoordinateFileFlags::RequireCoordinateSelection = 1 << 9, CoordinateFileFlags::Count } |
| The enums here define the flags specifying the requirements of different outputadapter modules. More... | |
| enum | ChangeSettingType : int { PreservedIfPresent, Always, Never, Count } |
| Enum class for setting basic flags in a t_trxframe. | |
| enum | ChangeAtomsType { PreservedIfPresent, AlwaysFromStructure, Never, Always, Count } |
| Enum class for t_atoms settings. | |
| enum | ChangeFrameInfoType { PreservedIfPresent, Always, Count } |
| Enum class for setting fields new or not. | |
| enum | ChangeFrameTimeType { PreservedIfPresent, StartTime, TimeStep, Both, Count } |
| Enum class for setting frame time from user input. | |
| enum | FrameConverterFlags : unsigned long { FrameConverterFlags::NoGuarantee = 1 << 0, FrameConverterFlags::MoleculesAreWhole = 1 << 1, FrameConverterFlags::NoPBCJumps = 1 << 2, FrameConverterFlags::MoleculeCOMInBox = 1 << 3, FrameConverterFlags::ResidueCOMInBox = 1 << 4, FrameConverterFlags::AtomsInBox = 1 << 5, FrameConverterFlags::UnitCellIsRectangular = 1 << 6, FrameConverterFlags::UnitCellIsTriclinic = 1 << 7, FrameConverterFlags::UnitCellIsCompact = 1 << 8, FrameConverterFlags::SystemIsCenteredInBox = 1 << 9, FrameConverterFlags::FitToReferenceRotTrans = 1 << 10, FrameConverterFlags::FitToReferenceRotTransXY = 1 << 11, FrameConverterFlags::FitToReferenceTranslation = 1 << 12, FrameConverterFlags::FitToReferenceTranslationXY = 1 << 13, FrameConverterFlags::FitToReferenceProgressive = 1 << 14, FrameConverterFlags::NewSystemCenter = 1 << 15, FrameConverterFlags::Count } |
| The enums here define the guarantees provided by frameconverters concerning the modifications they provide. More... | |
| enum | HaloMpiTag { HaloMpiTag::X, HaloMpiTag::F, HaloMpiTag::ZoneCorners, GridCounts, HaloMpiTag::GridColumns, HaloMpiTag::GridDimensions, HaloMpiTag::AtomIndices } |
| enum | HaloType { Coordinates, Forces } |
| Whether the halo exchange is of coordinates or forces. | |
| enum | DdRankOrder { DdRankOrder::select, DdRankOrder::interleave, DdRankOrder::pp_pme, DdRankOrder::cartesian, DdRankOrder::Count } |
| The options for the domain decomposition MPI task ordering. More... | |
| enum | DlbOption { DlbOption::select, DlbOption::turnOnWhenUseful, DlbOption::no, DlbOption::yes, DlbOption::Count } |
| The options for the dynamic load balancing. More... | |
| enum | DDBondedChecking : bool { DDBondedChecking::ExcludeZeroLimit = false, DDBondedChecking::All = true } |
| Options for checking bonded interactions. More... | |
| enum | DirectionX : int { Up = 0, Down, Center, Count } |
| Direction of neighbouring rank in X-dimension relative to current rank. Used in GPU implementation of PME halo exchange. | |
| enum | DirectionY : int { Left = 0, Right, Center, Count } |
| Direction of neighbouring rank in Y-dimension relative to current rank. Used in GPU implementation of PME halo exchange. | |
| enum | PmeLoadBalancingLimit : int { No, Box, DD, PmeGrid, MaxScaling, Count } |
| Enumeration whose values describe the effect limiting the load balancing. | |
| enum | FftBackend { FftBackend::Cufft, FftBackend::OclVkfft, FftBackend::Ocl, FftBackend::CuFFTMp, FftBackend::HeFFTe_CUDA, FftBackend::HeFFTe_Sycl_OneMkl, FftBackend::HeFFTe_Sycl_Rocfft, FftBackend::HeFFTe_Sycl_cuFFT, FftBackend::HeFFTe_HIP, FftBackend::SyclMkl, FftBackend::SyclOneMath, FftBackend::SyclRocfft, FftBackend::SyclVkfft, FftBackend::SyclBbfft, FftBackend::Sycl, FftBackend::HipVkfft, FftBackend::HipRocfft, Count } |
| enum | FftDirection : int { RealToComplex, ComplexToReal, Count } |
| Model the kinds of 3D FFT implemented. | |
| enum | H5mdFileMode : char { Read = 'r', H5mdFileMode::Write = 'w', H5mdFileMode::Append = 'a' } |
| enum | H5mdCompression : int { H5mdCompression::Uncompressed, H5mdCompression::LosslessNoShuffle, H5mdCompression::LosslessShuffle } |
| Data set compression options. More... | |
| enum | SpaceGroup : int32_t { SpaceGroup::P1 = 1 } |
| Space group in three dimensions. More... | |
| enum | MrcDataMode : int32_t { MrcDataMode::uInt8 = 0, MrcDataMode::int16 = 1, MrcDataMode::float32 = 2, MrcDataMode::complexInt32 = 3, MrcDataMode::complexFloat64 = 4 } |
| The type of density data stored in an mrc file. As named in "EMDB Map Distribution Format Description Version 1.01 (c) emdatabank.org 2014" Modes 0-4 are defined by the standard. NOTE only mode 2 is currently implemented and used. More... | |
| enum | YesNoType { Yes, No, Count, Default = Yes } |
| Enum class for boolean that should be true by default. | |
| enum | FmmDirectProvider { FmmDirectProvider::Gromacs, FmmDirectProvider::Fmm, Count } |
| Enumeration of possible direct interaction providers. More... | |
| enum | ActiveFmmBackend { ActiveFmmBackend::Inactive, ActiveFmmBackend::ExaFmm, ActiveFmmBackend::FMSolvr, Count } |
| Indicates which FMM backend is active based on MDP configuration. More... | |
| enum | ExaFmmTreeType { Uniform, Adaptive, Count } |
| Tree type options for ExaFMM. | |
| enum | DeviceStreamType : int { DeviceStreamType::NonBondedLocal, DeviceStreamType::NonBondedNonLocal, DeviceStreamType::Pme, DeviceStreamType::PmePpTransfer, DeviceStreamType::UpdateAndConstraints, DeviceStreamType::Count } |
| Class enum to describe the different logical streams used for GPU work. More... | |
| enum | PinningPolicy : int { CannotBePinned, PinnedIfSupported } |
| Helper enum for pinning policy of the allocation of HostAllocationPolicy. More... | |
| enum | Architecture { Architecture::Unknown, Architecture::X86, Architecture::Arm, Architecture::PowerPC, Architecture::RiscV32, Architecture::RiscV64, Architecture::Loongarch64 } |
| Enum for GROMACS CPU hardware detection support. More... | |
| enum | SimdType { SimdType::None, SimdType::Reference, SimdType::Generic, SimdType::X86_Sse2, SimdType::X86_Sse4_1, SimdType::X86_Avx128Fma, SimdType::X86_Avx, SimdType::X86_Avx2, SimdType::X86_Avx2_128, SimdType::X86_Avx512, SimdType::Arm_NeonAsimd, SimdType::Arm_Sve, SimdType::Ibm_Vsx } |
| Enumerated options for SIMD architectures. More... | |
| enum | IMDMessageType : int { IMDMessageType::Disconnect, IMDMessageType::Energies, IMDMessageType::FCoords, IMDMessageType::Go, IMDMessageType::Handshake, IMDMessageType::Kill, IMDMessageType::Mdcomm, IMDMessageType::Pause, IMDMessageType::TRate, IMDMessageType::IOerror, IMDMessageType::Count } |
| Enum for types of IMD messages. More... | |
| enum | DensitySimilarityMeasureMethod : int { DensitySimilarityMeasureMethod::innerProduct, DensitySimilarityMeasureMethod::relativeEntropy, DensitySimilarityMeasureMethod::crossCorrelation, Count } |
| The methods that determine how two densities are compared to one another. More... | |
| enum | CheckpointSignal { noSignal = 0, doCheckpoint = 1 } |
| Checkpoint signals. More... | |
| enum | ConstraintVariable : int { Positions, Velocities, Derivative, Deriv_FlexCon, Force, ForceDispl } |
| Describes supported flavours of constrained updates. | |
| enum | FlexibleConstraintTreatment { FlexibleConstraintTreatment::Include, FlexibleConstraintTreatment::Exclude } |
| Tells make_at2con how to treat flexible constraints. More... | |
| enum | NumTempScaleValues { NumTempScaleValues::None = 0, NumTempScaleValues::Single = 1, NumTempScaleValues::Multiple = 2, NumTempScaleValues::Count = 3 } |
| Sets the number of different temperature coupling values. More... | |
| enum | GraphState : int { GraphState::Invalid, GraphState::Recording, GraphState::Recorded, GraphState::Instantiated, GraphState::Count } |
| State of graph. More... | |
| enum | ResetSignal { noSignal = 0, doResetCounters = 1 } |
| Reset signals. More... | |
| enum | StopSignal : int { noSignal = 0, stopAtNextNSStep = 1, stopImmediately = -1 } |
| Stop signals. More... | |
| enum | IncompatibilityReasons { FlexibleConstraint, IncompatibleVsite, VsiteConstructingAtomsSplit, ConstrainedAtomOrder, NoCentralConstraintAtom, Count } |
| Reasons why the system can be incompatible with update groups. | |
| enum | VSiteCalculatePosition { Yes, No } |
| Whether we're calculating the virtual site position. | |
| enum | VSiteCalculateVelocity { Yes, No } |
| Whether we're calculating the virtual site velocity. | |
| enum | PbcMode { PbcMode::all, PbcMode::none } |
| PBC modes for vsite construction and spreading. More... | |
| enum | VSiteOperation { VSiteOperation::Positions, VSiteOperation::Velocities, VSiteOperation::PositionsAndVelocities, VSiteOperation::Count } |
| Whether we calculate vsite positions, velocities, or both. More... | |
| enum | VirtualSiteVirialHandling : int { VirtualSiteVirialHandling::None, VirtualSiteVirialHandling::Pbc, VirtualSiteVirialHandling::NonLinear } |
| Tells how to handle virial contributions due to virtual sites. More... | |
| enum | StartingBehavior : int { StartingBehavior::RestartWithAppending, StartingBehavior::RestartWithoutAppending, StartingBehavior::NewSimulation, StartingBehavior::Count } |
| Enumeration for describing how mdrun is (re)starting. More... | |
| enum | : std::ptrdiff_t { dynamic_extent = -1 } |
| Define constant that signals dynamic extent. | |
| enum | AwhTargetType : int { Constant, Cutoff, Boltzmann, LocalBoltzmann, Count, Default = Constant } |
| Target distribution enum. | |
| enum | AwhHistogramGrowthType : int { ExponentialLinear, Linear, Count, Default = ExponentialLinear } |
| Weight histogram growth enum. | |
| enum | AwhPotentialType : int { Convolved, Umbrella, Count, Default = Convolved } |
| AWH potential type enum. | |
| enum | AwhCoordinateProviderType : int { Pull, FreeEnergyLambda, Count, Default = Pull } |
| AWH bias reaction coordinate provider. | |
| enum | CheckpointDataOperation { Read, Write, Count } |
| The operations on CheckpointData. More... | |
| enum | AtomLocality : int { AtomLocality::Local = 0, AtomLocality::NonLocal = 1, AtomLocality::All = 2, AtomLocality::Count = 3 } |
| Atom locality indicator: local, non-local, all. More... | |
| enum | InteractionLocality : int { InteractionLocality::Local = 0, InteractionLocality::NonLocal = 1, InteractionLocality::Count = 2 } |
| Interaction locality indicator: local, non-local, all. More... | |
| enum | AppendingBehavior { AppendingBehavior::Auto, AppendingBehavior::Appending, AppendingBehavior::NoAppending } |
| Enumeration for mdrun appending behavior. More... | |
| enum | MtsForceGroups : int { MtsForceGroups::LongrangeNonbonded, MtsForceGroups::Nonbonded, MtsForceGroups::Pair, MtsForceGroups::Dihedral, MtsForceGroups::Angle, MtsForceGroups::Pull, MtsForceGroups::Awh, MtsForceGroups::Count } |
| Force group available for selection for multiple time step integration. More... | |
| enum | ReductionRequirement : int { ReductionRequirement::Soon, ReductionRequirement::Eventually } |
| Control whether reduction is required soon. More... | |
| enum | ObservablesReducerStatus : int { ObservablesReducerStatus::ReadyToReduce, ObservablesReducerStatus::AlreadyReducedThisStep } |
| Report whether the reduction has happened this step. More... | |
| enum | ComputeGlobalsAlgorithm { LeapFrog, VelocityVerlet } |
| The different global reduction schemes we know about. | |
| enum | EnergySignallerEvent { EnergyCalculationStep, VirialCalculationStep, FreeEnergyCalculationStep } |
| The energy events signalled by the EnergySignaller. | |
| enum | TrajectoryEvent { StateWritingStep, EnergyWritingStep } |
| The trajectory writing events. | |
| enum | ModularSimulatorBuilderState { AcceptingClientRegistrations, NotAcceptingClientRegistrations } |
| Enum allowing builders to store whether they can accept client registrations. | |
| enum | ReportPreviousStepConservedEnergy { Yes, No, Count } |
| Enum describing whether an element is reporting conserved energy from the previous step. | |
| enum | ScheduleOnInitStep { ScheduleOnInitStep::Yes, ScheduleOnInitStep::No, ScheduleOnInitStep::Count } |
| Whether the element does schedule on the initial step. More... | |
| enum | NhcUsage { NhcUsage::System, NhcUsage::Barostat, NhcUsage::Count } |
| The usages of Nose-Hoover chains. More... | |
| enum | ScaleVelocities { PreStepOnly, PreStepAndPostStep } |
| Which velocities the thermostat scales. | |
| enum | IntegrationStage { IntegrationStage::PositionsOnly, IntegrationStage::VelocitiesOnly, IntegrationStage::LeapFrog, IntegrationStage::VelocityVerletPositionsAndVelocities, IntegrationStage::ScaleVelocities, IntegrationStage::ScalePositions, IntegrationStage::Count } |
| The different integration types we know about. More... | |
| enum | NumPositionScalingValues { NumPositionScalingValues::None, NumPositionScalingValues::Single, NumPositionScalingValues::Multiple, NumPositionScalingValues::Count } |
| Sets the number of different position scaling values. More... | |
| enum | NumVelocityScalingValues { NumVelocityScalingValues::None, NumVelocityScalingValues::Single, NumVelocityScalingValues::Multiple, Count } |
| Sets the number of different velocity scaling values. More... | |
| enum | ParrinelloRahmanVelocityScaling { ParrinelloRahmanVelocityScaling::No, ParrinelloRahmanVelocityScaling::Diagonal, ParrinelloRahmanVelocityScaling::Anisotropic, Count } |
| Describes the properties of the Parrinello-Rahman pressure scaling matrix. More... | |
| enum | ReferenceTemperatureChangeAlgorithm |
| enum | EnergySignallerVirialMode { EnergySignallerVirialMode::Off, EnergySignallerVirialMode::OnStep, EnergySignallerVirialMode::OnStepAndNext, EnergySignallerVirialMode::Count } |
| When we calculate virial. More... | |
| enum | UseFullStepKE { Yes, No, Count } |
| Enum describing whether the thermostat is using full or half step kinetic energy. | |
| enum | { nbatXYZ, nbatXYZQ, nbatX4, nbatX8 } |
| enum | LJCombinationRule : int { LJCombinationRule::Geometric, LJCombinationRule::LorentzBerthelot, LJCombinationRule::None, LJCombinationRule::Count } |
| LJ combination rules. More... | |
| enum | NbnxmBenchMarkKernels : int { SimdAuto, SimdNo, Simd4XM, Simd2XMM, Count } |
| Enum for selecting the SIMD kernel type for benchmarks. | |
| enum | NbnxmBenchMarkCombRule : int { RuleGeom, RuleLB, RuleNone, Count } |
| Enum for selecting the combination rule for kernel benchmarks. | |
| enum | NbnxmBenchMarkCoulomb : int { Pme, ReactionField, Count } |
| Enum for selecting coulomb type for kernel benchmarks. | |
| enum | NbnxmBenchMarkInteractionModifiers : int { PotShift, PotSwitch, ForceSwitch, Count } |
| enum | ClusterDistanceKernelType : int { ClusterDistanceKernelType::CpuPlainC_4x4, ClusterDistanceKernelType::CpuSimd_4xM, ClusterDistanceKernelType::CpuSimd_2xMM, ClusterDistanceKernelType::Gpu, ClusterDistanceKernelType::CpuPlainC_1x1 } |
| The types of kernel for calculating the distance between pairs of atom clusters. More... | |
| enum | LJKernelType { LJKernelType::Cutoff, LJKernelType::ForceSwitch, LJKernelType::PotentialSwitch, LJKernelType::Ewald } |
| The free-energy kernel Lennard-Jones functional shape. More... | |
| enum | { vdwktLJCUT_COMBGEOM, vdwktLJCUT_COMBLB, vdwktLJCUT_COMBNONE, vdwktLJFORCESWITCH, vdwktLJPOTSWITCH, vdwktLJEWALDCOMBGEOM, vdwktLJEWALDCOMBLB, vdwktNR = vdwktLJEWALDCOMBLB, vdwktNR_ref } |
| Kinds of Van der Waals treatments in NBNxM SIMD kernels. More... | |
| enum | { enbvClearFNo, enbvClearFYes } |
| Flag to tell the nonbonded kernels whether to clear the force output buffers. | |
| enum | ElecType : int { ElecType::Cut, ElecType::RF, ElecType::EwaldTab, ElecType::EwaldTabTwin, ElecType::EwaldAna, ElecType::EwaldAnaTwin, ElecType::None, ElecType::Fmm, ElecType::Count } |
| Nbnxm electrostatic GPU kernel flavors. More... | |
| enum | VdwType : int { VdwType::Cut, VdwType::CutCombGeom, VdwType::CutCombLB, VdwType::FSwitch, VdwType::PSwitch, VdwType::EwaldGeom, VdwType::EwaldLB, VdwType::Count } |
| Nbnxm VdW GPU kernel flavors. More... | |
| enum | NbnxmKernelType : int { NotSet = 0, Cpu4x4_PlainC, Cpu4xN_Simd_4xN, Cpu4xN_Simd_2xNN, Gpu8x8x8, Cpu8x8x8_PlainC, Cpu1x1_PlainC, Count } |
| Nonbonded NxN kernel types: plain C, CPU SIMD, GPU, GPU emulation. | |
| enum | EwaldExclusionType : int { NotSet = 0, Table, Analytical, DecidedByGpuModule } |
| Ewald exclusion types. | |
| enum | PairlistType : int { Simple4x2, Simple4x4, Simple4x8, Hierarchical8x8x8, Simple1x1, Count } |
| The available pair list types. | |
| enum | CoulombKernelType : int { ReactionField, Table, TableTwin, Ewald, EwaldTwin, None, Fmm, Count } |
| Kinds of electrostatic treatments in SIMD Verlet kernels. | |
| enum | NonbondedResource : int { Cpu, Gpu, EmulateGpu } |
| Resources that can be used to execute non-bonded kernels on. | |
| enum | { enbsCCgrid, enbsCCsearch, enbsCCcombine, enbsCCnr } |
| Local cycle count enum for profiling different parts of search. | |
| enum | KernelCoulombType { KernelCoulombType::RF, KernelCoulombType::EwaldAnalytical, KernelCoulombType::EwaldTabulated, KernelCoulombType::None } |
| List of type of Nbnxm kernel coulomb type implementations. More... | |
| enum | ILJInteractions { ILJInteractions::All, ILJInteractions::Half, ILJInteractions::None } |
| The fraction of i-particles for which LJ interactions need to be computed. More... | |
| enum | HelpOutputFormat { eHelpOutputFormat_Console, eHelpOutputFormat_Rst, eHelpOutputFormat_Other, eHelpOutputFormat_NR } |
| Output format for help writing. More... | |
| enum | COMShiftType : int { Residue, Molecule, Count } |
| How COM shifting should be applied. | |
| enum | CenteringType : int { Triclinic, Rectangular, Zero, Count } |
| Helper enum class to define centering types. | |
| enum | UnitCellType : int { Triclinic, Rectangular, Compact, Count } |
| Helper enum class to define Unit cell representation types. | |
| enum | RandomDomain { RandomDomain::Other = 0x00000000, RandomDomain::MaxwellVelocities = 0x00001000, RandomDomain::TestParticleInsertion = 0x00002000, RandomDomain::UpdateCoordinates = 0x00003000, RandomDomain::UpdateConstraints = 0x00004000, RandomDomain::Thermostat = 0x00005000, RandomDomain::Barostat = 0x00006000, RandomDomain::ReplicaExchange = 0x00007000, RandomDomain::ExpandedEnsemble = 0x00008000, RandomDomain::AwhBiasing = 0x00009000 } |
| Enumerated values for fixed part of random seed (domain) More... | |
| enum | EndianSwapBehavior : int { EndianSwapBehavior::DoNotSwap, EndianSwapBehavior::Swap, EndianSwapBehavior::SwapIfHostIsBigEndian, EndianSwapBehavior::SwapIfHostIsLittleEndian, EndianSwapBehavior::Count } |
| Specify endian swapping behavoir. More... | |
| enum | TaskTarget : int { Auto, Cpu, Gpu } |
| Record where a compute task is targetted. | |
| enum | EmulateGpuNonbonded : bool { EmulateGpuNonbonded::No, EmulateGpuNonbonded::Yes } |
| Help pass GPU-emulation parameters with type safety. More... | |
| enum | GpuTask : int { GpuTask::Nonbonded, GpuTask::Pme, GpuTask::Count } |
| Types of compute tasks that can be run on a GPU. More... | |
| enum | Isotope { H, D, He, Li, Be, B, C, N, O, F, Ne, Na, Mg, Al, Si, P, S, Cl, Ar, K, Ca, Sc, Ti, V, Cr, Mn, Fe, Co, Ni, Cu, Zn, Ga, Ge, As, Se, Br, Kr, Rb, Sr, Y, Zr, Nb, Mo, Tc, Ru, Rh, Pd, Ag, Cd, In, Sn, Sb, Te, I, Xe, Cs, Ba, La, Ce, Pr, Nd, Pm, Sm, Eu, Gd, Tb, Dy, Ho, Er, Tm, Yb, Lu, Hf, Ta, W, Re, Os, Ir, Pt, Au, Hg, Tl, Pb, Bi, Po, At, Rn, Fr, Ra, Ac, Th, Pa, U, Np, Pu, Am, Cm, Bk, Cf, Es, Fm, Md, No, Lr, Rf, Db, Sg, Bh, Hs, Mt, Count } |
| isotopes | |
| enum | ErrorCode { eeOK, eeOutOfMemory, eeFileNotFound, eeFileIO, eeInvalidInput, eeInconsistentInput, eeTolerance, eeInstability, eeNotImplemented, eeInvalidValue, eeInvalidCall, eeInternalError, eeAPIError, eeRange, eeParallelConsistency, eeModularSimulator, eeMDModuleSetup, eeUnknownError } |
| Possible error return codes from Gromacs functions. More... | |
| enum | GpuAwareMpiStatus : int { GpuAwareMpiStatus::NotSupported = 0, GpuAwareMpiStatus::Forced, GpuAwareMpiStatus::Supported, GpuAwareMpiStatus::Count } |
| Enum describing GPU-aware support in underlying MPI library. More... | |
| enum | StringCompareType { StringCompareType::Exact, StringCompareType::CaseInsensitive, StringCompareType::CaseAndDashInsensitive } |
| Specifies how strings should be compared in various contexts. More... | |
| enum | StripStrings : int { StripStrings::No, StripStrings::Yes } |
| Enum class for whether StringToEnumValueConverter will strip strings of leading and trailing whitespace before comparison. More... | |
| enum | TimeUnit : int { Femtoseconds, Picoseconds, Nanoseconds, Microseconds, Milliseconds, Seconds, Count, Default = Picoseconds } |
| Time values for TimeUnitManager and legacy oenv module. | |
| enum | OptionFileType : int { Topology, RunInput, Trajectory, Energy, PDB, AtomIndex, Plot, GenericData, Csv, QMInput, Count } |
| Purpose of file(s) provided through an option. | |
| enum | OptionFlag : uint64_t { efOption_Set = 1 << 0, efOption_HasDefaultValue = 1 << 1, efOption_ExplicitDefaultValue = 1 << 2, efOption_ClearOnNextSet = 1 << 3, efOption_Required = 1 << 4, efOption_MultipleTimes = 1 << 5, efOption_Hidden = 1 << 6, efOption_Vector = 1 << 8, efOption_DefaultValueIfSetExists = 1 << 11, efOption_NoDefaultValue = 1 << 9, efOption_DontCheckMinimumCount = 1 << 10 } |
| Flags for options. More... | |
Functions | |||
| static bool | anyDimUsesProvider (const AwhBiasParams &awhBiasParams, const AwhCoordinateProviderType awhCoordProvider) | ||
| Checks whether any dimension uses the given coordinate provider type. More... | |||
| static bool | anyDimUsesProvider (const AwhParams &awhParams, const AwhCoordinateProviderType awhCoordProvider) | ||
| Checks whether any dimension uses the given coordinate provider type. More... | |||
| static bool | anyBiasIsScaledByMetric (const AwhParams &awhParams) | ||
| Checks whether any bias scales the target distribution based on the AWH friction metric. More... | |||
| std::unique_ptr< Awh > | prepareAwhModule (FILE *fplog, const t_inputrec &inputRecord, t_state *stateGlobal, const MpiComm &mpiComm, const gmx_multisim_t *multiSimRecord, bool startingFromCheckpoint, bool usingShellParticles, const std::string &biasInitFilename, pull_t *pull_work) | ||
| Makes an Awh and prepares to use it if the user input requests that. More... | |||
| static int64_t | countSamples (ArrayRef< const PointState > pointState) | ||
| Count the total number of samples / sample weight over all grid points. More... | |||
| static void | ensureStateAndRunConsistency (const BiasParams ¶ms, const BiasState &state) | ||
| Check if the state (loaded from checkpoint) and the run are consistent. More... | |||
| double | getDeviationFromPointAlongGridAxis (const BiasGrid &grid, int dimIndex, int pointIndex, double value) | ||
| Get the deviation along one dimension from the given value to a point in the grid. More... | |||
| double | getDeviationFromPointAlongGridAxis (const BiasGrid &grid, int dimIndex, int pointIndex1, int pointIndex2) | ||
| Get the deviation from one point to another along one dimension in the grid. More... | |||
| bool | pointsAlongLambdaAxis (const BiasGrid &grid, int pointIndex1, int pointIndex2) | ||
| Checks whether two points are along a free energy lambda state axis. More... | |||
| bool | pointsHaveDifferentLambda (const BiasGrid &grid, int pointIndex1, int pointIndex2) | ||
| Checks whether two points are different in the free energy lambda state dimension (if any). More... | |||
| void | linearArrayIndexToMultiDim (int indexLinear, int ndim, const awh_ivec numPointsDim, awh_ivec indexMulti) | ||
| Convert a linear array index to a multidimensional one. More... | |||
| void | linearGridindexToMultiDim (const BiasGrid &grid, int indexLinear, awh_ivec indexMulti) | ||
| Convert a linear grid point index to a multidimensional one. More... | |||
| int | multiDimArrayIndexToLinear (const awh_ivec indexMulti, int numDim, const awh_ivec numPointsDim) | ||
| Convert multidimensional array index to a linear one. More... | |||
| int | multiDimGridIndexToLinear (const BiasGrid &grid, const awh_ivec indexMulti) | ||
| Convert a multidimensional grid point index to a linear one. More... | |||
| bool | advancePointInSubgrid (const BiasGrid &grid, const awh_ivec subgridOrigin, const awh_ivec subgridNpoints, int *gridPointIndex) | ||
| Find the next grid point in the sub-part of the grid given a starting point. More... | |||
| static int | pointDistanceAlongAxis (const GridAxis &axis, double x, double x0) | ||
| Returns the point distance between from value x to value x0 along the given axis. More... | |||
| static bool | valueIsInGrid (const awh_dvec value, ArrayRef< const GridAxis > axis) | ||
| Query if a value is in range of the grid. More... | |||
| static int | getNearestIndexInGrid (const awh_dvec value, ArrayRef< const GridAxis > axis) | ||
| Map a value to the nearest point in the grid. More... | |||
| void | mapGridToDataGrid (std::vector< int > *gridpointToDatapoint, const MultiDimArray< std::vector< double >, dynamicExtents2D > &data, int numDataPoints, const std::string &dataFilename, const BiasGrid &grid, const std::string &correctFormatMessage) | ||
| Maps each point in the grid to a point in the data grid. More... | |||
| template<typename T > | |||
| void | sumOverSimulations (ArrayRef< T > data, MPI_Comm multiSimComm, const bool broadcastWithinSimulation, const MpiComm &mpiComm) | ||
| Sum an array over all simulations on main ranks or all ranks of each simulation. More... | |||
| bool | haveBiasSharingWithinSimulation (const AwhParams &awhParams) | ||
| Returns if any bias is sharing within a simulation. More... | |||
| void | biasesAreCompatibleForSharingBetweenSimulations (const AwhParams &awhParams, ArrayRef< const size_t > pointSize, const BiasSharing &biasSharing) | ||
| Checks whether biases are compatible for sharing between simulations, throws when not. More... | |||
| static void | normalizeFreeEnergyAndPmfSum (std::vector< PointState > *pointState) | ||
| Normalizes the free energy and PMF sum. More... | |||
| static int | countTrailingZeroRows (const MultiDimArray< std::vector< double >, dynamicExtents2D > &data, int numRows, int numColumns) | ||
| Count trailing data rows containing only zeros. More... | |||
| static void | readUserPmfAndTargetDistribution (ArrayRef< const DimParams > dimParams, const BiasGrid &grid, const std::string &filename, int numBias, int biasIndex, std::vector< PointState > *pointState) | ||
| Initializes the PMF and target with data read from an input table. More... | |||
| static void | normalizeBlock (AwhEnergyBlock *block, const Bias &bias) | ||
| Normalizes block data for output. More... | |||
| void | initCorrelationGridHistory (CorrelationGridHistory *correlationGridHistory, int numCorrelationTensors, int tensorSize, int blockDataListSize) | ||
| Initialize correlation grid history, sets all sizes. More... | |||
| CorrelationGridHistory | initCorrelationGridHistoryFromState (const CorrelationGrid &corrGrid) | ||
| Allocate a correlation grid history with the same structure as the given correlation grid. More... | |||
| void | updateCorrelationGridHistory (CorrelationGridHistory *corrGridHist, const CorrelationGrid &corrGrid) | ||
| Update the correlation grid history for checkpointing. More... | |||
| void | restoreCorrelationGridStateFromHistory (const CorrelationGridHistory &corrGridHist, CorrelationGrid *corrGrid) | ||
| Restores the correlation grid state from the correlation grid history. More... | |||
| double | getSqrtDeterminant (gmx::ArrayRef< const double > correlationIntegral) | ||
| Returns the volume element of the correlation metric. More... | |||
| const char * | enumValueToString (AwhTargetType enumValue) | ||
| String for target distribution. | |||
| const char * | enumValueToString (AwhHistogramGrowthType enumValue) | ||
| String for weight histogram growth. | |||
| const char * | enumValueToString (AwhPotentialType enumValue) | ||
| String for AWH potential type. | |||
| const char * | enumValueToString (AwhCoordinateProviderType enumValue) | ||
| String for AWH bias reaction coordinate provider. | |||
| static double | get_pull_coord_period (const t_pull_coord &pullCoordParams, const t_pbc &pbc, const real intervalLength) | ||
| Gets the period of a pull coordinate. More... | |||
| static bool | intervalIsInPeriodicInterval (double origin, double end, double period) | ||
| Checks if the given interval is defined in the correct periodic interval. More... | |||
| static bool | valueIsInInterval (double origin, double end, double period, double value) | ||
| Checks if a value is within an interval. More... | |||
| static void | checkInputConsistencyInterval (const AwhParams &awhParams, WarningHandler *wi) | ||
| Check if the starting configuration is consistent with the given interval. More... | |||
| static void | setStateDependentAwhPullDimParams (AwhDimParams *dimParams, const int biasIndex, const int dimIndex, const pull_params_t &pull_params, pull_t *pull_work, const t_pbc &pbc, const tensor &compressibility, WarningHandler *wi) | ||
| Sets AWH parameters, for one AWH pull dimension. More... | |||
| void | setStateDependentAwhParams (AwhParams *awhParams, const pull_params_t &pull_params, pull_t *pull_work, const matrix box, PbcType pbcType, const tensor &compressibility, const t_inputrec &inputrec, real initLambda, const gmx_mtop_t &mtop, WarningHandler *wi) | ||
| Sets AWH parameters that need state parameters such as the box vectors. More... | |||
| void | checkAwhParams (const AwhParams &awhParams, const t_inputrec &inputrec, WarningHandler *wi) | ||
| Check the AWH parameters. More... | |||
| bool | awhHasFepLambdaDimension (const AwhParams &awhParams) | ||
| Returns true when AWH has a bias with a free energy lambda state dimension. | |||
| std::string | colvarsDescription () | ||
| Returns information for describing the colvars support. | |||
| bool | operator== (const DensityFittingParameters &lhs, const DensityFittingParameters &rhs) | ||
| Check if two structs holding density fitting parameters are equal. More... | |||
| bool | operator!= (const DensityFittingParameters &lhs, const DensityFittingParameters &rhs) | ||
| Check if two structs holding density fitting parameters are not equal. More... | |||
| std::string | torchDescription () | ||
| Returns information for describing the Torch support. | |||
| static void | centerAtomPositions (ArrayRef< RVec > nnPos, ArrayRef< RVec > mmPos, const matrix &box, const PbcType &pbcType) | ||
| atomNumbers_ (params_.numAtoms_,-1) | |||
| inputToLocalIndex_ (params_.numAtoms_,-1) | |||
| logger_ (logger) | |||
| mpiComm_ (mpiComm) | |||
| static std::string | recordToString (std::tuple< at::DataPtr, size_t > data) | ||
| static void | loadModelExtensions (const std::string &ext_libs, const MDLogger &logger) | ||
| load custom extensions used to compile the TorchScript model from extra_files | |||
|
static std::tuple< std::string, std::optional< int > > | getMdrunActiveDevice () | ||
| static torch::Device | determineDevice (const MDLogger &logger, const MpiComm &mpiComm) | ||
| Determine which device to use depending on GMX_NN_DEVICE environment variable. More... | |||
| std::string | plumedDescription () | ||
| Returns information for describing the PLUMED support. | |||
| std::string | qmmmDescription () | ||
| Returns information for describing the CP2K QM/MM support. | |||
| RVec | computeQMBoxVec (const RVec &a, const RVec &b, const RVec &c, real h, real minNorm, real maxNorm) | ||
| Transforms vector a such as distance from it to the plane defined by vectors b and c will be h minimum length will be milL and maximum length maxL. More... | |||
| CommandLineProgramContext & | initForCommandLine (int *argc, char ***argv) | ||
| Initializes the GROMACS library for command-line use. More... | |||
| void | finalizeForCommandLine () | ||
| Deinitializes the GROMACS library after initForCommandLine(). More... | |||
| int | processExceptionAtExitForCommandLine (const std::exception &ex) | ||
| Handles an exception and deinitializes after initForCommandLine. More... | |||
| int | runCommandLineModule (int argc, char *argv[], ICommandLineModule *module) | ||
| Implements a main() method that runs a single module. More... | |||
| int | runCommandLineModule (int argc, char *argv[], const char *name, const char *description, std::function< std::unique_ptr< ICommandLineOptionsModule >()> factory) | ||
| Implements a main() method that runs a single module. More... | |||
| void | writeCommandLineHelpCMain (const CommandLineHelpContext &context, const char *name, int(*mainFunction)(int argc, char *argv[])) | ||
| Helper to implement ICommandLineModule::writeHelp() with a C-like main() function that calls parse_common_args(). More... | |||
| static int | getFileType (const std::string &filename) | ||
Get the internal file type from the filename. More... | |||
| static unsigned long | getSupportedOutputAdapters (int filetype) | ||
| Get the flag representing the requirements for a given file output. More... | |||
| static OutputAdapterContainer | addOutputAdapters (const OutputRequirements &requirements, AtomsDataPtr atoms, const Selection &sel, unsigned long abilities) | ||
| Creates a new container object with the user requested IOutputAdapter derived methods attached to it. More... | |||
| std::unique_ptr < TrajectoryFrameWriter > | createTrajectoryFrameWriter (const gmx_mtop_t *top, const Selection &sel, const std::string &filename, AtomsDataPtr atoms, OutputRequirements requirements) | ||
| Factory function for TrajectoryFrameWriter. More... | |||
| static void | deepCopy_t_trxframe (const t_trxframe &input, t_trxframe *copy, RVec *xvec, RVec *vvec, RVec *fvec, int *indexvec) | ||
Create a deep copy of a t_trxframe input into copy. More... | |||
| static t_trxstatus * | openTNG (const std::string &name, const Selection &sel, const gmx_mtop_t *mtop) | ||
| Method to open TNG file. More... | |||
| unsigned long | convertFlag (CoordinateFileFlags flag) | ||
| Conversion of flag to its corresponding unsigned long value. | |||
| unsigned long | convertFlag (FrameConverterFlags flag) | ||
| Conversion of flag to its corresponding unsigned long value. | |||
| static void | adjustAtomInformation (t_atoms *atoms, t_atoms *selectionAtoms, const Selection &sel) | ||
| Modify atoms information in coordinate frame to fit output selection. More... | |||
| static CommSetup | split_communicator (const MDLogger &mdlog, const MpiComm &mpiCommSimulation, const DdRankOrder ddRankOrder, const bool gmx_unused reorder, const DDRankSetup &ddRankSetup) | ||
| static CommSetup | makeGroupCommunicators (const MDLogger &mdlog, const DDSettings &ddSettings, const DdRankOrder ddRankOrder, const DDRankSetup &ddRankSetup, const MpiComm &mpiCommSimulation) | ||
| Makes the PP communicator and the PME communicator, when needed. More... | |||
| static void | setupGroupCommunication (const MDLogger &mdlog, const DDSettings &ddSettings, ArrayRef< const int > pmeRanks, const int numAtomsInSystem, gmx_domdec_t *dd) | ||
| For PP ranks, sets or makes the communicator. More... | |||
| static std::vector< real > | get_slb_frac (const gmx::MDLogger &mdlog, const char *dir, int nc, const char *size_string) | ||
| HaloPlan | computeHaloPlan (const gmx_domdec_comm_t &comm, int dimIndex, int pulse, MPI_Comm mpiCommMySim, int sendRankX, int recvRankX) | ||
| template<bool usePbc> | |||
| static auto | packSendBufKernel (Float3 *__restrict__ gm_dataPacked, const Float3 *__restrict__ gm_data, const int *__restrict__ gm_map, int mapSize, Float3 coordinateShift) | ||
| template<bool accumulate> | |||
| static auto | unpackRecvBufKernel (Float3 *__restrict__ gm_data, const Float3 *__restrict__ gm_dataPacked, const int *__restrict__ gm_map, int mapSize) | ||
| unpack non-local force data buffer on the GPU using pre-populated "map" containing index information. More... | |||
| template<bool usePbc, class... Args> | |||
| static void | launchPackSendBufKernel (const DeviceStream &deviceStream, int xSendSize, Args &&...args) | ||
| template<bool accumulateForces, class... Args> | |||
| static void | launchUnpackRecvBufKernel (const DeviceStream &deviceStream, int fRecvSize, Args &&...args) | ||
| static void | flagInteractionsForType (const InteractionFunction ftype, const InteractionList &il, const reverse_ilist_t &ril, const Range< int > &atomRange, const int numAtomsPerMolecule, ArrayRef< const int > globalAtomIndices, ArrayRef< int > isAssigned) | ||
| Checks whether interactions have been assigned for one function type. More... | |||
| static std::string | printMissingInteractionsMolblock (const MpiComm &mpiComm, const gmx_domdec_t &dd, const gmx_reverse_top_t &rt, const char *moltypename, const reverse_ilist_t &ril, const Range< int > &atomRange, const int numAtomsPerMolecule, const int numMolecules, const InteractionDefinitions &idef) | ||
| Help print error output when interactions are missing in a molblock. More... | |||
| static void | printMissingInteractionsAtoms (const MDLogger &mdlog, const MpiComm &mpiComm, const gmx_domdec_t &dd, const gmx_mtop_t &mtop, const InteractionDefinitions &idef) | ||
| Help print error output when interactions are missing. | |||
| static void | dd_print_missing_interactions (const MDLogger &mdlog, const MpiComm &mpiComm, const gmx_domdec_t &dd, const int numBondedInteractionsOverAllDomains, const int expectedNumGlobalBondedInteractions, const gmx_mtop_t &top_global, const gmx_localtop_t &top_local, ArrayRef< const RVec > x, const matrix box) | ||
| Print error output when interactions are missing. | |||
| static int | computeExpectedNumGlobalBondedInteractions (const gmx_mtop_t &mtop, const DDBondedChecking ddBondedChecking, const bool useUpdateGroups) | ||
| Compute the total bonded interaction count. More... | |||
| void | mdAlgorithmsSetupAtomData (const gmx_domdec_t *dd, const t_inputrec &inputrec, const gmx_mtop_t &top_global, gmx_localtop_t *top, t_forcerec *fr, ForceBuffers *force, MDAtoms *mdAtoms, Constraints *constr, VirtualSitesHandler *vsite, gmx_shellfc_t *shellfc) | ||
| Sets atom data for several MD algorithms. More... | |||
| void | make_local_shells (const gmx_domdec_t *dd, const t_mdatoms &md, gmx_shellfc_t *shfc) | ||
| Gets the local shell with domain decomposition. More... | |||
| bool | check_grid_jump (int64_t step, const gmx_domdec_t *dd, real cutoff, const gmx_ddbox_t *ddbox, bool bFatal) | ||
| Check whether the DD grid has moved too far for correctness. | |||
| void | print_dd_statistics (gmx_domdec_t *dd, const t_inputrec &inputrec, FILE *fplog) | ||
| Print statistics for domain decomposition communication. | |||
| void | dd_partition_system (FILE *fplog, const gmx::MDLogger &mdlog, int64_t step, gmx_domdec_t *dd, bool bMainState, t_state *state_global, const gmx_mtop_t &top_global, const t_inputrec &inputrec, const MDModulesNotifiers &mdModulesNotifiers, gmx::ImdSession *imdSession, pull_t *pull_work, t_state *state_local, gmx::ForceBuffers *f, gmx::MDAtoms *mdAtoms, gmx_localtop_t *top_local, t_forcerec *fr, gmx::VirtualSitesHandler *vsite, gmx::Constraints *constr, t_nrnb *nrnb, gmx_wallcycle *wcycle, bool bVerbose) | ||
| TODO Remove fplog when group scheme and charge groups are gone. More... | |||
| static const char * | enumValueToString (PmeLoadBalancingLimit enumValue) | ||
Descriptive strings for PmeLoadBalancingLimit enumValue. | |||
| bool | pmeTuningIsSupported (CoulombInteractionType coulombInteractionType, bool reproducibilityRequested, const SimulationWorkload &simulationWork) | ||
| Returns whether PME tuning is supported. | |||
| static Cutoffs | getCutoffs (const t_inputrec &ir, const matrix box, const interaction_const_t &ic, const nonbonded_verlet_t &nbv) | ||
| Computes and returns initially set cutoffs and box. | |||
| static int | numPmeGridPoints (const pme_setup_t &setup) | ||
| Return product of the number of PME grid points in each dimension. | |||
| static void | printGrid (FILE *fp_err, const MDLogger &mdlog, const char *pre, const char *desc, const pme_setup_t &set, double cycles) | ||
| Print the PME grid. | |||
| static void | printLoadBalLimited (FILE *fp_err, const MDLogger &mdlog, int64_t step, const PmeLoadBalancingLimit limited, const pme_setup_t &setup) | ||
| Print descriptive string about what limits PME load balancing. | |||
| static void | applySetup (pme_setup_t *setup, gmx_pme_t *pmedataOfSetup0, const t_inputrec &ir, interaction_const_t *ic, nonbonded_verlet_t *nbv, gmx_domdec_t *dd) | ||
Updates all the mdrun machinery for setup, setup->pmedata might be updated. | |||
| static bool | processCycles (FILE *fp_err, const MDLogger &mdlog, const double cycles, const int64_t step, const bool isInLastStage, pme_setup_t *set) | ||
Checks the cycles and adds them to *set. More... | |||
| static void | printLoadBalSetup (const MDLogger &mdlog, const char *name, const pme_setup_t &setup) | ||
| Print one load-balancing setting. | |||
| static void | printLoadBalSettings (const PmeLoadBalancingLimit limited, const bool currentSetupIsLastSetup, const pme_setup_t ¤tSetup, const pme_setup_t &originalSetup, const bool useGpuForNonbondeds, const MDLogger &mdlog) | ||
| Print all load-balancing settings. | |||
| std::string | cpuFftDescription () | ||
| Construct a string that describes the library that provides CPU FFT support to this build. More... | |||
| std::string | gpuFftDescription () | ||
| Construct a string that describes the library that provides GPU FFT support to this build. More... | |||
| std::string | multiGpuFftDescription () | ||
| Construct a string that describes the library (if any) that provides multi-GPU FFT support to this build. More... | |||
| static void | handleCufftError (cufftResult_t status, const char *msg) | ||
| makePlan ("complex-to-real", rocfft_transform_type_real_inverse, PlanSetupData{rocfft_array_type_hermitian_interleaved, makeComplexStrides(complexGridSizePadded), computeTotalSize(complexGridSizePadded)}, PlanSetupData{rocfft_array_type_real, makeRealStrides(realGridSizePadded), computeTotalSize(realGridSizePadded)}, std::vector< size_t >{size_t(realGridSize[ZZ]), size_t(realGridSize[YY]), size_t(realGridSize[XX])})} | |||
| realGrid_ | pmeStream_ (pmeStream) | ||
| static void | handleClfftError (clfftStatus status, const char *msg) | ||
| Throws the exception on clFFT error. | |||
| makePlan ("complex-to-real", rocfft_transform_type_real_inverse, PlanSetupData{rocfft_array_type_hermitian_interleaved, makeComplexStrides(complexGridSizePadded), computeTotalSize(complexGridSizePadded)}, PlanSetupData{rocfft_array_type_real, makeRealStrides(realGridSizePadded), computeTotalSize(realGridSizePadded)}, std::vector< size_t >{size_t(realGridSize[ZZ]), size_t(realGridSize[YY]), size_t(realGridSize[XX])}, pmeStream) | |||
| realGrid_ * | realGrid ()),{GMX_RELEASE_ASSERT(performOutOfPlaceFFT,"Only out-of-place FFT is implemented" | ||
| GMX_RELEASE_ASSERT (allocateRealGrid==false,"Grids need to be pre-allocated") | |||
| GMX_RELEASE_ASSERT (gridSizesInXForEachRank.size()==1 &&gridSizesInYForEachRank.size()==1,"FFT decomposition not implemented with the SYCL rocFFT backend") | |||
| template<typename NativeQueue > | |||
| static void | launchVkFft (const DeviceBuffer< float > &realGrid, const DeviceBuffer< float > &complexGrid, NativeQueue queue, gmx_fft_direction fftDirection, VkFFTApplication *application, VkFFTLaunchParams *launchParams) | ||
| void | handleRocFftError (rocfft_status result, const std::string &msg) | ||
| Helper for consistent error handling. | |||
| void | handleRocFftError (rocfft_status result, const std::string &direction, const std::string &msg) | ||
| Helper for consistent error handling. | |||
| std::array< size_t, DIM > | makeRealStrides (ivec realGridSizePadded) | ||
| Compute the stride through the real 1D array. | |||
| std::array< size_t, DIM > | makeComplexStrides (ivec complexGridSizePadded) | ||
| Compute the stride through the complex 1D array. | |||
| size_t | computeTotalSize (ivec gridSize) | ||
| Compute total grid size. | |||
| template<typename ValueType > | |||
| void | readKvtCheckpointValue (compat::not_null< ValueType * > value, std::string_view name, std::string_view identifier, const KeyValueTreeObject &kvt) | ||
| Read to a key-value-tree value used for checkpointing. More... | |||
| template void | readKvtCheckpointValue (compat::not_null< std::int64_t * > value, std::string_view name, std::string_view identifier, const KeyValueTreeObject &kvt) | ||
| Read to a key-value-tree value used for checkpointing. More... | |||
| template void | readKvtCheckpointValue (compat::not_null< real * > value, std::string_view name, std::string_view identifier, const KeyValueTreeObject &kvt) | ||
| Read to a key-value-tree value used for checkpointing. More... | |||
| template<typename ValueType > | |||
| void | writeKvtCheckpointValue (const ValueType &value, std::string_view name, std::string_view identifier, KeyValueTreeObjectBuilder kvtBuilder) | ||
| Write to a key-value-tree used for checkpointing. More... | |||
| template void | writeKvtCheckpointValue (const std::int64_t &value, std::string_view name, std::string_view identifier, KeyValueTreeObjectBuilder kvtBuilder) | ||
| Write to a key-value-tree used for checkpointing. More... | |||
| template void | writeKvtCheckpointValue (const real &value, std::string_view name, std::string_view identifier, KeyValueTreeObjectBuilder kvtBuilder) | ||
| Write to a key-value-tree used for checkpointing. More... | |||
| void | setStringAttributeByBuffer (const hid_t container, const char *attributeName, const size_t numberOfStrings, const int maxStrLength, ArrayRef< const char > buffer) | ||
| Low-level utility function to write a string-vector attribute via a character buffer. More... | |||
| template<typename ValueType > | |||
| std::optional< ValueType > | getAttribute (const hid_t container, const char *attributeName) | ||
| Read an attribute of a given data type. More... | |||
| template<> | |||
| std::optional< std::string > | getAttribute< std::string > (const hid_t container, const char *attributeName) | ||
| Read an attribute of a given data type. More... | |||
| template<typename ValueType > | |||
| std::optional< std::vector < ValueType > > | getAttributeVector (const hid_t container, const char *attributeName) | ||
| Read a vector-like attribute of a given data type. More... | |||
| template<> | |||
| std::optional< std::vector < std::string > > | getAttributeVector< std::string > (const hid_t container, const char *attributeName) | ||
| Read a vector-like attribute of a given data type. More... | |||
| template<typename ValueType > | |||
| void | setAttribute (const hid_t container, const char *attributeName, const ValueType &value) | ||
| Write a scalar attribute of a given data type. More... | |||
| void | setAttribute (const hid_t container, const char *attributeName, const char *value) | ||
| Write a scalar attribute of a given data type. More... | |||
| void | setAttribute (const hid_t container, const char *attributeName, const std::string &value) | ||
| Write a scalar attribute of a given data type. More... | |||
| template<typename ValueType > | |||
| void | setAttributeVector (const hid_t container, const char *attributeName, ArrayRef< const ValueType > value) | ||
| Write a vector-like attribute of a given data type. More... | |||
| void | setAttributeVector (hid_t container, const char *attributeName, ArrayRef< const std::string > values) | ||
| Write a vector-like attribute of strings. More... | |||
| void | setAttributeVector (hid_t container, const char *attributeName, ArrayRef< const char *const > values) | ||
| Write a vector-like attribute of C-strings. More... | |||
| template<typename Iterator > | |||
| std::vector< char > | setAttributeStringVector (const hid_t container, const char *attributeName, std::vector< char > &&buffer, Iterator begin, Iterator end) | ||
| Write a vector-like string attribute via iterators String data type is treated specially because of the HDF5 requirements for contiguous memory storage for fixed-size strings. A reusable character buffer is needed to avoid frequent memory allocations for multiple writing of different string attributes. More... | |||
| static hsize_t | getNumDims (const hid_t dataSetHandle) | ||
| void | printHdf5ErrorsDebug () | ||
| Helper function for printing debug statements. More... | |||
| void | throwUponH5mdError (const bool errorExists, const std::string &message) | ||
| void | throwUponInvalidHid (const hid_t id, const std::string &message) | ||
| Throw a gmx::FileIOError if the HDF5 ID is invalid (H5Iis_valid <= 0). More... | |||
| template<typename ValueType > | |||
| static DataSetDims | primitiveDimsToValueTypeDims (const DataSetDims &dims) | ||
| Return the dimensions of the templated ValueType for the primitive type data set dimensions. | |||
| static hsize_t | numValuesInDataSet (const DataSetDims &dims) | ||
Return the number of values in a data set with templated type dimensions dims. | |||
| static void | readVariableSizeStringsFromDataSet (const hid_t dataSet, const hid_t nativeDataType, ArrayRef< std::string > stringValues) | ||
| static void | writeFixedSizeStringsToDataSet (const hid_t dataSet, const hid_t dataType, ArrayRef< const std::string > stringsToWrite) | ||
| static void | writeVariableSizeStringsToDataSet (const hid_t dataSet, const hid_t dataType, ArrayRef< const std::string > stringsToWrite) | ||
| static DataSetDims | getFullDims (const DataSetDims &dataSetDims) | ||
| static hsize_t | getNumValues (const DataSetDims &dims) | ||
| hid_t | createGroup (const hid_t container, const char *name) | ||
| Create an H5MD group, and intermediate groups if they do not exist. More... | |||
| hid_t | openGroup (const hid_t container, const char *name) | ||
| Open an existing HDF5 group. More... | |||
| hid_t | openOrCreateGroup (const hid_t container, const char *name) | ||
| Open an existing HDF5 group or create it if it did not exist already. More... | |||
| std::pair< hid_t, H5mdGuard > | makeH5mdGuard (hid_t object, H5mdCloseType unboundCloser) | ||
| Helper function for guarding an HDF5 object with a closing function (H5Gclose, etc.). More... | |||
| std::pair< hid_t, H5mdGuard > | makeH5mdGroupGuard (hid_t object) | ||
| Helper function for guarding an HDF5 group with H5Gclose. More... | |||
| std::pair< hid_t, H5mdGuard > | makeH5mdDataSetGuard (hid_t object) | ||
| Helper function for guarding an HDF5 data set with H5Dclose. More... | |||
| std::pair< hid_t, H5mdGuard > | makeH5mdDataSpaceGuard (hid_t object) | ||
| Helper function for guarding an HDF5 data space with H5Sclose. More... | |||
| std::pair< hid_t, H5mdGuard > | makeH5mdPropertyListGuard (hid_t object) | ||
| Helper function for guarding an HDF5 property list with H5Pclose. More... | |||
| std::pair< hid_t, H5mdGuard > | makeH5mdAttributeGuard (hid_t object) | ||
| Helper function for guarding an HDF5 attribute with H5Aclose. More... | |||
| std::pair< hid_t, H5mdGuard > | makeH5mdTypeGuard (hid_t object) | ||
| Helper function for guarding an HDF5 type with H5Tclose. More... | |||
| IndexMap | mapSelectionToInternalIndices (const ArrayRef< const int32_t > &selectedIndices) | ||
| Map the selected atoms to local internal indices. More... | |||
| void | writeAtomicProperties (AtomRange &atomRange, const hid_t baseContainer, const std::optional< IndexMap > &selectedAtomsIndexMap=std::nullopt) | ||
| Write atomic properties to the H5MD file. More... | |||
| void | writeResidueInfo (AtomRange &atomRange, const hid_t baseContainer, const std::optional< IndexMap > &selectedAtomsIndexMap=std::nullopt) | ||
| Write residue and sequence information to the H5MD file. More... | |||
| void | writeBonds (const gmx_mtop_t &topology, const hid_t baseContainer, const std::optional< IndexMap > &selectedAtomsIndexMap=std::nullopt) | ||
| Write the covalent connectivity to the H5MD file. More... | |||
| void | writeDisulfideBonds (const gmx_mtop_t &topology, const hid_t baseContainer, const std::optional< IndexMap > &selectedAtomsIndexMap=std::nullopt) | ||
| Write the additional annotation of disulfide bonds to the H5MD file. More... | |||
| void | labelInternalTopologyVersion (const hid_t baseContainer) | ||
| Label the version of the internal topology module. More... | |||
| void | labelTopologyName (const hid_t baseContainer, const char *topName) | ||
| Label the name of the simulation system. More... | |||
| void | writeMoleculeTypes (const hid_t baseContainer, const ArrayRef< const gmx_moltype_t > moltypes) | ||
Write a set of molecule type blocks in moltypes to the HDF5 container baseContainer. More... | |||
| void | writeMoleculeBlocks (const hid_t baseContainer, const ArrayRef< const gmx_molblock_t > molBlocks) | ||
| Write the molecule block information to the HDF5 container of GROMACS internal topology. More... | |||
| template<typename ValueType > | |||
| hid_t | hdf5DataTypeFor () noexcept | ||
| Return a handle to a native HDF5 type corresponding to the templated value type. More... | |||
| template<> | |||
| hid_t | hdf5DataTypeFor< int32_t > () noexcept | ||
| Return a handle to a native HDF5 type corresponding to the templated value type. More... | |||
| template<> | |||
| hid_t | hdf5DataTypeFor< int64_t > () noexcept | ||
| Return a handle to a native HDF5 type corresponding to the templated value type. More... | |||
| template<> | |||
| hid_t | hdf5DataTypeFor< float > () noexcept | ||
| Return a handle to a native HDF5 type corresponding to the templated value type. More... | |||
| template<> | |||
| hid_t | hdf5DataTypeFor< double > () noexcept | ||
| Return a handle to a native HDF5 type corresponding to the templated value type. More... | |||
| template<> | |||
| hid_t | hdf5DataTypeFor< uint32_t > () noexcept | ||
| Return a handle to a native HDF5 type corresponding to the templated value type. More... | |||
| template<> | |||
| hid_t | hdf5DataTypeFor< uint64_t > () noexcept | ||
| Return a handle to a native HDF5 type corresponding to the templated value type. More... | |||
| hid_t | hdf5DataTypeForFixedSizeString (const hsize_t maxStringLength) | ||
| Return a handle to a HDF5 data type for fixed-size strings. More... | |||
| hid_t | hdf5DataTypeForVariableSizeString () | ||
| Return a handle to a HDF5 data type for variable-size strings. | |||
| template<typename ValueType > | |||
| bool | valueTypeIsDataType (const hid_t dataType) noexcept | ||
| Return true if the template value type matches the HDF5 data type. More... | |||
| template<> | |||
| bool | valueTypeIsDataType< char * > (const hid_t dataType) noexcept | ||
| Return true if the template value type matches the HDF5 data type. More... | |||
| template<> | |||
| bool | valueTypeIsDataType< const char * > (const hid_t dataType) noexcept | ||
| Return true if the template value type matches the HDF5 data type. More... | |||
| template<> | |||
| bool | valueTypeIsDataType< std::string > (const hid_t dataType) noexcept | ||
| Return true if the template value type matches the HDF5 data type. More... | |||
| template<typename ValueType > | |||
| bool | valueTypeIsDataType (const hid_t dataType, const ArrayRef< const ValueType > gmx_unused valueBuffer) noexcept | ||
| Return true if the template value type matches the HDF5 data type. More... | |||
| bool | objectExists (const hid_t container, const char *name) noexcept | ||
Return whether object name exists in the given HDF5 container. More... | |||
| bool | handleIsValid (const hid_t handle) noexcept | ||
Return whether HDF5 handle is valid. More... | |||
| std::optional< std::string > | getHandlePath (const hid_t handle) | ||
Return the full name (HDF-path) of an HDF5 handle. More... | |||
| std::optional< std::string > | getHandleBaseName (const hid_t handle) | ||
Return the base name (last component of the HDF-path) of an HDF5 handle. More... | |||
| template<typename Iterator , typename Callback > | |||
| std::pair< size_t, size_t > | estimateBufferSize (Iterator begin, Iterator end, Callback cStringFromIterator) | ||
| Iterate over a list of objects and calculate the maximum string length via a callback function. More... | |||
| template<typename Iterator , typename Callback > | |||
| std::vector< char > | packBufferViaIterator (Iterator begin, Iterator end, std::vector< char > &&packingBuffer, const size_t maxStrLength, Callback cStringFromIterator) | ||
| Pack a string buffer from a range of iterators and a callback function. More... | |||
| size_t | numberOfExpectedDataItems (const MrcDensityMapHeader &header) | ||
| Return the number of density data items that are expected to follow this header. More... | |||
| TranslateAndScale | getCoordinateTransformationToLattice (const MrcDensityMapHeader &header) | ||
| Extract the transformation into lattice coordinates. More... | |||
| dynamicExtents3D | getDynamicExtents3D (const MrcDensityMapHeader &header) | ||
| Extract the extents of the density data. More... | |||
| bool | mrcHeaderIsSane (const MrcDensityMapHeader &header) | ||
| Checks if the values in the header are sane. More... | |||
| void | serializeMrcDensityMapHeader (ISerializer *serializer, const MrcDensityMapHeader &mrcHeader) | ||
| Serializes an MrcDensityMapHeader from a given serializer. More... | |||
| MrcDensityMapHeader | deserializeMrcDensityMapHeader (ISerializer *serializer) | ||
| Deserializes an MrcDensityMapHeader from a given serializer. More... | |||
| const char * | enumValueToString (YesNoType enumValue) | ||
Strings for YesNoType. | |||
| std::string | tngDescription () | ||
| Returns information for describing the TNG support. | |||
| std::string | fmmBackendName (ActiveFmmBackend backend) | ||
| Returns the string name for a given FMM backend. More... | |||
| std::string | fmmDirectProviderName (FmmDirectProvider directProvider) | ||
| Returns the string name for a given FMM direct provider. More... | |||
| std::string | exaFmmTreeTypeName (ExaFmmTreeType treeType) | ||
| Returns the string name for a given ExaFmm Tree Type. More... | |||
| static real | smallestAtomMass (const gmx_mtop_t &mtop) | ||
| void | repartitionAtomMasses (gmx_mtop_t *mtop, bool useFep, real massFactor, WarningHandler *wi) | ||
Scales the smallest masses in the system by up to massFactor. More... | |||
|
std::unordered_map < std::string, std::string > | gpuDescriptions () | ||
| Returns information for describing the GPU support. | |||
| template<typename Queue , typename CommandGroupFunc > | |||
| static void | syclSubmitWithoutEvent (Queue &&queue, CommandGroupFunc &&cgf) | ||
| Helper function to submit a SYCL operation without returning an event. More... | |||
| template<typename CommandGroupFunc > | |||
| static void | syclEnqueueCustomOp (sycl::handler &cgh, CommandGroupFunc &&cgf) | ||
| Helper function to add a custom operation to the SYCL handler. More... | |||
| template<typename T > | |||
| static Float3 * | asGenericFloat3Pointer (T *in) | ||
Reinterpret-cast any pointer in to Float3, checking the type compatibility. | |||
| template<typename T > | |||
| static const Float3 * | asGenericFloat3Pointer (const T *in) | ||
Reinterpret-cast any const pointer in to Float3, checking the type compatibility. | |||
| template<typename C > | |||
| static Float3 * | asGenericFloat3Pointer (C &in) | ||
Reinterpret-cast any container in to Float3, checking the type compatibility. | |||
| template<typename C > | |||
| static const Float3 * | asGenericFloat3Pointer (const C &in) | ||
Reinterpret-cast any const container in to Float3, checking the type compatibility. | |||
| std::string | getDeviceErrorString (const hipError_t deviceError) | ||
| Add the API information on the specific error to the error message. More... | |||
| void | checkDeviceError (const hipError_t deviceError, const std::string_view errorMessage) | ||
| Check if API returned an error and throw an exception with information on it. More... | |||
| void | ensureNoPendingDeviceError (const std::string_view errorMessage) | ||
| Helper function to ensure no pending error silently disrupts error handling. More... | |||
| template<typename PinnableVector > | |||
| void | changePinningPolicy (PinnableVector *v, PinningPolicy pinningPolicy) | ||
| Helper function for changing the pinning policy of a pinnable vector. More... | |||
| void | doDeviceTransfers (const DeviceContext &deviceContext, ArrayRef< const char > input, ArrayRef< char > output) | ||
| Helper function for GPU test code to be platform agnostic. More... | |||
| bool | cpuIsX86Nehalem (const CpuInfo &cpuInfo) | ||
| Return true if the CPU is an Intel x86 Nehalem. More... | |||
| bool | cpuIsAmdZen1 (const CpuInfo &cpuInfo) | ||
| Return true if the CPU is a first generation AMD Zen (produced by AMD or Hygon) More... | |||
| bool | cpuIsNeoverseV2 (const CpuInfo &cpuInfo) | ||
| Return true if the CPU has Neoverse V2 cores (including Grace and Graviton 4) More... | |||
| static DeviceDetectionResult | detectAllDeviceInformation (const PhysicalNodeCommunicator &physicalNodeComm) | ||
| Detect GPUs when that makes sense to attempt. More... | |||
| static void | gmx_collect_hardware_mpi (const gmx::CpuInfo &cpuInfo, const PhysicalNodeCommunicator &physicalNodeComm, gmx_hw_info_t *hardwareInfo, [[maybe_unused]] MPI_Comm world) | ||
Reduce the locally collected hardwareInfo over MPI ranks. | |||
| std::unique_ptr< gmx_hw_info_t > | gmx_detect_hardware (const PhysicalNodeCommunicator &physicalNodeComm, MPI_Comm libraryCommWorld) | ||
| Run detection and make correct and consistent hardware information available on all ranks. More... | |||
| void | logHardwareDetectionWarnings (const gmx::MDLogger &mdlog, const gmx_hw_info_t &hardwareInformation) | ||
| Issue warnings to mdlog that were decided during detection. More... | |||
| static bool | runningOnCompatibleOSForAmd () | ||
| Return true if executing on compatible OS for AMD OpenCL. More... | |||
| static bool | runningOnCompatibleHWForNvidia (const DeviceInformation &deviceInfo) | ||
| Return true if executing on compatible GPU for NVIDIA OpenCL. More... | |||
| static FixedCapacityVector < int, 12 > | fillSupportedSubGroupSizes (const cl_device_id devId, const DeviceVendor deviceVendor) | ||
| Return the list of sub-group sizes supported by the device. More... | |||
| static bool | runningOnCompatibleHWForAmd (const DeviceInformation &deviceInfo) | ||
| Return true if executing on compatible GPU for AMD OpenCL. More... | |||
| static DeviceStatus | isDeviceFunctional (const DeviceInformation &deviceInfo) | ||
Checks that device deviceInfo is compatible with GROMACS. More... | |||
| std::string | makeOpenClInternalErrorString (const char *message, cl_int status) | ||
| Make an error string following an OpenCL API call. More... | |||
| static bool | isDeviceFunctional (const DeviceInformation &deviceInfo, std::string *errorMessage) | ||
Checks that device deviceInfo is sane (ie can run a kernel). More... | |||
| static DeviceStatus | checkGpu (size_t deviceId, const DeviceInformation &deviceInfo) | ||
Check whether the ocl_gpu_device is suitable for use by mdrun. More... | |||
| std::string | hwlocDescription () | ||
| Returns information for describing the hwloc support. | |||
| int | identifyAvx512FmaUnits () | ||
| Test whether machine has dual AVX512 FMA units. More... | |||
| static const std::string & | simdString (SimdType s) | ||
| SimdType | simdSuggested (const CpuInfo &c) | ||
| Return the SIMD type that would fit this hardware best. | |||
| static SimdType | simdCompiled () | ||
| bool | simdCheck (const CpuInfo &cpuInfo, SimdType wanted, FILE *log, bool warnToStdErr) | ||
| Check if binary was compiled with the provided SIMD type. More... | |||
| std::string | simdDescription () | ||
| Return a string describing the SIMD support. | |||
| static const char * | enumValueToString (IMDMessageType enumValue) | ||
| Names of the IMDType for error messages. | |||
| static void | fill_header (IMDHeader *header, IMDMessageType type, int32_t length) | ||
| Fills the header with message and the length argument. | |||
| static void | swap_header (IMDHeader *header) | ||
| Swaps the endianess of the header. | |||
| static int32_t | imd_read_multiple (IMDSocket *socket, char *datptr, int32_t toread) | ||
| Reads multiple bytes from socket. | |||
| static int32_t | imd_write_multiple (IMDSocket *socket, const char *datptr, int32_t towrite) | ||
| Writes multiple bytes to socket in analogy to imd_read_multiple. | |||
| static int | imd_handshake (IMDSocket *socket) | ||
| Handshake with IMD client. | |||
| static int | imd_send_energies (IMDSocket *socket, const IMDEnergyBlock *energies, char *buffer) | ||
| Send energies using the energy block and the send buffer. | |||
| static IMDMessageType | imd_recv_header (IMDSocket *socket, int32_t *length) | ||
| Receive IMD header from socket, sets the length and returns the IMD message. | |||
| static bool | imd_recv_mdcomm (IMDSocket *socket, int32_t nforces, int32_t *forcendx, float *forces) | ||
| Receive force indices and forces. More... | |||
| void | write_IMDgroup_to_file (bool bIMD, t_inputrec *ir, const t_state *state, const gmx_mtop_t &sys, int nfile, const t_filenm fnm[]) | ||
| Writes out the group of atoms selected for interactive manipulation. More... | |||
| static int | imd_send_rvecs (IMDSocket *socket, int nat, rvec *x, char *buffer) | ||
| Send positions from rvec. More... | |||
| static bool | rvecs_differ (const rvec v1, const rvec v2) | ||
| Returns true if any component of the two rvecs differs. | |||
| static void | shift_positions (const matrix box, rvec x[], const ivec is, int nr) | ||
| Copied and modified from groupcoord.c shift_positions_group(). | |||
| static void | imd_check_integrator_parallel (const t_inputrec *ir, const MpiComm &mpiComm) | ||
| Check for non-working integrator / parallel options. | |||
| std::unique_ptr< ImdSession > | makeImdSession (const t_inputrec *ir, const MpiComm &mpiComm, const gmx_domdec_t *dd, gmx_wallcycle *wcycle, gmx_enerdata_t *enerd, const gmx_multisim_t *ms, const gmx_mtop_t &top_global, const MDLogger &mdlog, gmx::ArrayRef< const gmx::RVec > coords, int nfile, const t_filenm fnm[], const gmx_output_env_t *oenv, const ImdOptions &options, StartingBehavior startingBehavior) | ||
| Makes and returns an initialized IMD session, which may be inactive. More... | |||
| int | imdsock_winsockinit () | ||
| Define a function to initialize winsock. | |||
| static void | print_IMD_error (const char *file, int line, char *msg) | ||
| Print a nice error message on UNIX systems, using errno.h. | |||
| IMDSocket * | imdsock_create () | ||
| Create an IMD main socket. More... | |||
| void | imd_sleep (unsigned int seconds) | ||
| Portability wrapper around sleep function. | |||
| int | imdsock_bind (IMDSocket *sock, int port) | ||
| Bind the IMD socket to address and port. More... | |||
| int | imd_sock_listen (IMDSocket *sock) | ||
| Set socket to listening state. More... | |||
| IMDSocket * | imdsock_accept (IMDSocket *sock) | ||
| Accept incoming connection and redirect to client socket. More... | |||
| int | imdsock_getport (IMDSocket *sock, int *port) | ||
| Get the port number used for IMD connection. More... | |||
| int | imd_htonl (int src) | ||
| Portability wrapper around system htonl function. | |||
| int | imd_ntohl (int src) | ||
| Portability wrapper around system ntohl function. | |||
| int | imdsock_write (IMDSocket *sock, const char *buffer, int length) | ||
| Write to socket. More... | |||
| int | imdsock_read (IMDSocket *sock, char *buffer, int length) | ||
| Read from socket. More... | |||
| void | imdsock_shutdown (IMDSocket *sock) | ||
| Shutdown the socket. More... | |||
| int | imdsock_destroy (IMDSocket *sock) | ||
| Close the socket and free the sock struct memory. More... | |||
| int | imdsock_tryread (IMDSocket *sock, int timeoutsec, int timeoutusec) | ||
| Try to read from the socket. More... | |||
| std::string | blasDescription () | ||
| Returns information for describing the BLAS libary. | |||
| std::string | lapackDescription () | ||
| Returns information for describing the LAPACK libary. | |||
| bool | buildSupportsListedForcesGpu (std::string *error) | ||
| Checks whether the GROMACS build allows to compute bonded interactions on a GPU. More... | |||
| bool | inputSupportsListedForcesGpu (const t_inputrec &ir, const gmx_mtop_t &mtop, std::string *error) | ||
| Checks whether the input system allows to compute bonded interactions on a GPU. More... | |||
| static bool | someInteractionsCanRunOnGpu (const InteractionLists &ilists) | ||
| Returns whether there are any interactions in ilists suitable for a GPU. | |||
| static bool | bondedInteractionsCanRunOnGpu (const gmx_mtop_t &mtop) | ||
| Returns whether there are any bonded interactions in the global topology suitable for a GPU. | |||
| static int | chooseSubGroupSizeForDevice (const DeviceInformation &deviceInfo) | ||
| static bool | fTypeHasPerturbedEntries (const InteractionDefinitions &idef, int fType) | ||
Return whether function type fType in idef has perturbed interactions. | |||
| static void | convertIlistToNbnxnOrder (const InteractionList &src, HostInteractionList *dest, int numAtomsPerInteraction, ArrayRef< const int > nbnxnAtomOrder) | ||
Converts src with atom indices in state order to dest in nbnxn order. | |||
| static int | roundUpToFactor (const int input, const int factor) | ||
Returns input rounded up to the closest multiple of factor. | |||
| template<bool calcVir, bool calcEner> | |||
| __launch_bounds__ (c_threadsBondedPerBlock) __global__ void bonded_kernel_gpu(BondedGpuKernelParameters kernelParams | |||
| if | constexpr (calcVir) | ||
| for (int j=0;j< numFTypesOnGpu;j++) | |||
| if (threadComputedPotential) | |||
| template<bool calcVir, bool calcEner> | |||
| auto | bondedKernel (sycl::handler &cgh, const BondedGpuKernelParameters &kernelParams, const DeviceBuffer< t_iatom > gm_iatoms_[numFTypesOnGpu], float *__restrict__ gm_vTot, const t_iparams *__restrict__ gm_forceParams_, const sycl::float4 *__restrict__ gm_xq_in_, Float3 *__restrict__ gm_f_, Float3 *__restrict__ gm_fShift_) | ||
| static void | PrintTo (const RVec &value, std::ostream *os) | ||
Print an RVec to os. | |||
| static void | PrintTo (const PaddedVector< RVec > &vector, std::ostream *os) | ||
Print a padded vector of RVec to os. | |||
| void | normalizeSumPositiveValuesToUnity (ArrayRef< float > data) | ||
| Divide all values of a view by a constant so that the sum of all its positive values is one. More... | |||
| void | exponentialMovingAverageStateAsKeyValueTree (KeyValueTreeObjectBuilder builder, const ExponentialMovingAverageState &state) | ||
| Convert the exponential moving average state as key-value-tree object. | |||
| ExponentialMovingAverageState | exponentialMovingAverageStateFromKeyValueTree (const KeyValueTreeObject &object) | ||
| Sets the exponential moving average state from a key-value-tree object. More... | |||
| unsigned int | log2I (std::uint32_t x) | ||
| Compute floor of logarithm to base 2, 32 bit unsigned argument. More... | |||
| unsigned int | log2I (std::uint64_t x) | ||
| Compute floor of logarithm to base 2, 64 bit unsigned argument. More... | |||
| unsigned int | log2I (std::int32_t x) | ||
| Compute floor of logarithm to base 2, 32 bit signed argument. More... | |||
| unsigned int | log2I (std::int64_t x) | ||
| Compute floor of logarithm to base 2, 64 bit signed argument. More... | |||
| std::int64_t | greatestCommonDivisor (std::int64_t p, std::int64_t q) | ||
| Find greatest common divisor of two numbers. More... | |||
| double | erfinv (double x) | ||
| Inverse error function, double precision. More... | |||
| float | erfinv (float x) | ||
| Inverse error function, single precision. More... | |||
| IntegerBox | spreadRangeWithinLattice (const IVec ¢er, dynamicExtents3D extent, IVec range) | ||
| Construct a box that holds all indices that are not more than a given range remote from center coordinates and still within a given lattice extent. More... | |||
| static void | assertMatrixIsBoxMatrix (const Matrix3x3 gmx_used_in_debug &m) | ||
Assert that the matrix m describes a simulation box. More... | |||
| static void | assertMatrixIsBoxMatrix (const matrix gmx_used_in_debug m) | ||
Assert that the matrix m describes a simulation box. More... | |||
| static void | multiplyVectorByTransposeOfBoxMatrix (const Matrix3x3 &m, const rvec v, rvec result) | ||
Multiply vector v by the transpose of the box matrix m, relying on the fact that the upper triangle of the matrix is zero. | |||
| static RVec | multiplyVectorByTransposeOfBoxMatrix (const Matrix3x3 &m, const RVec &v) | ||
Multiply vector v by the transpose of the box matrix m, relying on the fact that the upper triangle of the matrix is zero. | |||
| static Matrix3x3 | multiplyBoxMatrices (const Matrix3x3 &a, const Matrix3x3 &b) | ||
| Multiply box matrices, relying on the fact that their upper triangle is zero. | |||
| static Matrix3x3 | multiplyBoxMatrices (const Matrix3x3 &a, const matrix b) | ||
| Multiply box matrices, relying on the fact that their upper triangle is zero. | |||
| static Matrix3x3 | invertBoxMatrix (const Matrix3x3 &src) | ||
| Invert a simulation-box matrix. More... | |||
| static void | invertBoxMatrix (const matrix src, matrix dest) | ||
Invert a simulation-box matrix in src, return in dest. More... | |||
| void | invertMatrix (const matrix src, matrix dest) | ||
Invert a general 3x3 matrix in src, return in dest. More... | |||
| template<typename ElementType > | |||
| BasicMatrix3x3< ElementType > | operator* (const ElementType scalar, const BasicMatrix3x3< ElementType > &other) | ||
Return the product of multiplying the 3x3 matrix other by the scalar. | |||
| template<typename ElementType > | |||
| BasicVector< ElementType > | diagonal (const BasicMatrix3x3< ElementType > &matrix) | ||
Return a vector that is the diagonal of the 3x3 matrix. | |||
| template<typename ElementType > | |||
| BasicMatrix3x3< ElementType > | transpose (BasicMatrix3x3< ElementType > matrix) | ||
Returns the transposition of matrix. | |||
| template<typename ElementType > | |||
| constexpr ElementType | determinant (BasicMatrix3x3< ElementType > matrix) | ||
Returns the determinant of matrix. | |||
| template<typename ElementType > | |||
| constexpr ElementType | trace (BasicMatrix3x3< ElementType > matrix) | ||
Returns the trace of matrix. | |||
| template<typename ElementType > | |||
| BasicMatrix3x3< ElementType > | inner (const BasicMatrix3x3< ElementType > &a, const BasicMatrix3x3< ElementType > &b) | ||
Return the inner product of multiplication of two 3x3 matrices a and b. | |||
| template<typename ElementType > | |||
| BasicMatrix3x3< ElementType > | diagonalMatrix (const ElementType value) | ||
| Create a diagonal matrix of ElementType. More... | |||
| template<typename ElementType > | |||
| BasicMatrix3x3< ElementType > | identityMatrix () | ||
| Create an identity matrix of ElementType. More... | |||
| static Matrix3x3 | createMatrix3x3FromLegacyMatrix (const matrix legacyMatrix) | ||
| Create new matrix type from legacy type. | |||
| static void | fillLegacyMatrix (Matrix3x3 newMatrix, matrix legacyMatrix) | ||
| Fill existing legacy matrix from new matrix type. | |||
| template<class TContainer , class Extents > | |||
| constexpr MultiDimArray < TContainer, Extents > ::const_iterator | begin (const MultiDimArray< TContainer, Extents > &multiDimArray) | ||
| Free MultiDimArray begin function addressing its contiguous memory. | |||
| template<class TContainer , class Extents > | |||
| constexpr MultiDimArray < TContainer, Extents > ::iterator | begin (MultiDimArray< TContainer, Extents > &multiDimArray) | ||
| Free MultiDimArray begin function addressing its contiguous memory. | |||
| template<class TContainer , class Extents > | |||
| constexpr MultiDimArray < TContainer, Extents > ::const_iterator | end (const MultiDimArray< TContainer, Extents > &multiDimArray) | ||
| Free MultiDimArray end function addressing its contiguous memory. | |||
| template<class TContainer , class Extents > | |||
| constexpr MultiDimArray < TContainer, Extents > ::iterator | end (MultiDimArray< TContainer, Extents > &multiDimArray) | ||
| Free MultiDimArray end function addressing its contiguous memory. | |||
| template<class TContainer , class Extents > | |||
| void | swap (MultiDimArray< TContainer, Extents > &a, MultiDimArray< TContainer, Extents > &b) noexcept | ||
| Swap function. | |||
| OptimisationResult | nelderMead (const std::function< real(ArrayRef< const real >)> &functionToMinimize, ArrayRef< const real > initialGuess, real minimumRelativeSimplexLength=1e-8, int maxSteps=10'000) | ||
| Derivative-free downhill simplex optimisation. More... | |||
| std::unique_ptr< BoxDeformation > | buildBoxDeformation (const Matrix3x3 &initialBox, DDRole ddRole, NumRanks numRanks, MPI_Comm communicator, const t_inputrec &inputrec) | ||
| Factory function for box deformation module. More... | |||
| void | setBoxDeformationFlowMatrix (const matrix boxDeformationVelocity, const matrix box, matrix flowMatrix) | ||
| Set a matrix for computing the flow velocity at coordinates. More... | |||
| static CheckpointSignal | convertToCheckpointSignal (signed char sig) | ||
| Convert signed char (as used by SimulationSignal) to CheckpointSignal enum. More... | |||
| static void | clear_constraint_quantity_nonlocal (const gmx_domdec_t &dd, ArrayRef< RVec > q) | ||
| Clears constraint quantities for atoms in nonlocal region. | |||
| void | too_many_constraint_warnings (ConstraintAlgorithm eConstrAlg, int warncount) | ||
| Generate a fatal error because of too many LINCS/SETTLE warnings. | |||
| static void | write_constr_pdb (const char *fn, const char *title, const gmx_mtop_t &mtop, int start, int homenr, const MpiComm &mpiComm, const gmx_domdec_t *dd, ArrayRef< const RVec > x, const matrix box) | ||
| Writes out coordinates. | |||
| static void | dump_confs (FILE *log, int64_t step, const gmx_mtop_t &mtop, int start, int homenr, const MpiComm &mpiComm, const gmx_domdec_t *dd, ArrayRef< const RVec > x, ArrayRef< const RVec > xprime, const matrix box) | ||
| Writes out domain contents to help diagnose crashes. | |||
| FlexibleConstraintTreatment | flexibleConstraintTreatment (bool haveDynamicsIntegrator) | ||
| Returns the flexible constraint treatment depending on whether the integrator is dynamic. | |||
| static ListOfLists< int > | makeAtomsToConstraintsList (int numAtoms, const gmx::EnumerationArray< InteractionFunction, InteractionList > &ilists, ArrayRef< const t_iparams > iparams, FlexibleConstraintTreatment flexibleConstraintTreatment) | ||
| Returns a block struct to go from atoms to constraints. More... | |||
| ListOfLists< int > | make_at2con (int numAtoms, const gmx::EnumerationArray< InteractionFunction, InteractionList > &ilist, ArrayRef< const t_iparams > iparams, FlexibleConstraintTreatment flexibleConstraintTreatment) | ||
| Returns a ListOfLists object to go from atoms to constraints. More... | |||
| ListOfLists< int > | make_at2con (const gmx_moltype_t &moltype, gmx::ArrayRef< const t_iparams > iparams, FlexibleConstraintTreatment flexibleConstraintTreatment) | ||
| Returns a ListOfLists object to go from atoms to constraints. More... | |||
| static std::vector< int > | make_at2settle (int natoms, const InteractionList &ilist) | ||
| Returns the index of the settle to which each atom belongs. | |||
| static std::vector < ListOfLists< int > > | makeAtomToConstraintMappings (const gmx_mtop_t &mtop, FlexibleConstraintTreatment flexibleConstraintTreatment) | ||
| Makes a per-moleculetype container of mappings from atom indices to constraint indices. More... | |||
| bool | hasTriangleConstraints (const gmx_mtop_t &mtop, FlexibleConstraintTreatment flexibleConstraintTreatment) | ||
| Returns True if there is at least one triangular constraint. | |||
| void | do_constrain_first (FILE *log, gmx::Constraints *constr, const t_inputrec &inputrec, int numHomeAtoms, ArrayRefWithPadding< RVec > x, ArrayRefWithPadding< RVec > v, const matrix box, real lambda) | ||
| Constrain the initial coordinates and velocities. | |||
| void | constrain_velocities (gmx::Constraints *constr, bool computeRmsd, int64_t step, t_state *state, real *dhdlambda, bool computeVirial, tensor constraintsVirial) | ||
| Constrain the velocities only. More... | |||
| void | constrain_coordinates (gmx::Constraints *constr, bool computeRmsd, int64_t step, t_state *state, ArrayRefWithPadding< RVec > xp, real *dhdlambda, bool computeVirial, tensor constraintsVirial) | ||
| Constrain the coordinates. More... | |||
| static bool | isConstraintFlexible (ArrayRef< const t_iparams > iparams, int iparamsIndex) | ||
Returns whether constraint with parameter iparamsIndex is a flexible constraint. | |||
| const int * | constr_iatomptr (gmx::ArrayRef< const int > iatom_constr, gmx::ArrayRef< const int > iatom_constrnc, int con) | ||
| Returns the constraint iatoms for a constraint number con which comes from a list where InteractionFunction::Constraints and InteractionFunction::ConstraintsNoCoupling constraints are concatenated. | |||
| static void | constr_recur (const ListOfLists< int > &at2con, const InteractionLists &ilist, gmx::ArrayRef< const t_iparams > iparams, gmx_bool bTopB, int at, int depth, int nc, ArrayRef< int > path, real r0, real r1, real *r2max, int *count) | ||
| Recursing function to help find all adjacent constraints. | |||
| static real | constr_r_max_moltype (const gmx_moltype_t *molt, gmx::ArrayRef< const t_iparams > iparams, const t_inputrec *ir) | ||
| Find the interaction radius needed for constraints for this molecule type. | |||
| real | constr_r_max (const MDLogger &mdlog, const gmx_mtop_t *mtop, const t_inputrec *ir) | ||
| Returns an estimate of the maximum distance between atoms required for LINCS. | |||
| real | calculateAcceptanceWeight (LambdaWeightCalculation calculationMode, real lambdaEnergyDifference) | ||
| Calculates the acceptance weight for a lambda state transition. More... | |||
| void | do_force (FILE *log, const t_commrec *cr, const t_inputrec &inputrec, const MDModulesNotifiers &mdModulesNotifiers, Awh *awh, gmx_enfrot *enforcedRotation, ImdSession *imdSession, pull_t *pull_work, int64_t step, t_nrnb *nrnb, gmx_wallcycle *wcycle, const gmx_localtop_t *top, const matrix box, ArrayRefWithPadding< RVec > coordinates, ArrayRef< RVec > velocities, const history_t *hist, ForceBuffersView *force, tensor vir_force, const t_mdatoms *mdatoms, gmx_enerdata_t *enerd, ArrayRef< const real > lambda, t_forcerec *fr, const MdrunScheduleWorkload &runScheduleWork, VirtualSitesHandler *vsite, rvec mu_tot, double t, gmx_edsam *ed, CpuPpLongRangeNonbondeds *longRangeNonbondeds, const DDBalanceRegionHandler &ddBalanceRegionHandler) | ||
| gmx::EnumerationArray < FreeEnergyPerturbationCouplingType, real > | currentLambdas (int64_t step, const t_lambda &fepvals, int currentLambdaState) | ||
| Evaluate the current lambdas. More... | |||
| void | launchForceReductionKernel (int numAtoms, int atomStart, bool addRvecForce, bool accumulate, const DeviceBuffer< Float3 > d_nbnxmForceToAdd, const DeviceBuffer< Float3 > d_rvecForceToAdd, DeviceBuffer< Float3 > d_baseForce, DeviceBuffer< int > d_cell, const DeviceStream &deviceStream, DeviceBuffer< uint64_t > d_forcesReadyNvshmemFlags, const uint64_t forcesReadyNvshmemFlagsCounter) | ||
| Backend-specific function to launch GPU Force Reduction kernel. More... | |||
| template<bool addRvecForce, bool accumulateForce> | |||
| static auto | reduceKernel (const Float3 *__restrict__ gm_nbnxmForce, const Float3 *__restrict__ gm_rvecForceToAdd, Float3 *__restrict__ gm_forceTotal, const int *__restrict__ gm_cell, const int atomStart) | ||
| Function returning the force reduction kernel lambda. | |||
| template<bool addRvecForce, bool accumulateForce> | |||
| static void | launchReductionKernel_ (const int numAtoms, const int atomStart, const DeviceBuffer< Float3 > &d_nbnxmForce, const DeviceBuffer< Float3 > &d_rvecForceToAdd, DeviceBuffer< Float3 > &d_forceTotal, const DeviceBuffer< int > &d_cell, const DeviceStream &deviceStream) | ||
| Force reduction SYCL kernel launch code. | |||
| NumTempScaleValues | getTempScalingType (bool doTemperatureScaling, int numTempScaleValues) | ||
Convert doTemperatureScaling and numTempScaleValues to NumTempScaleValues. | |||
| void | launchLeapFrogKernel (int numAtoms, DeviceBuffer< Float3 > d_x, DeviceBuffer< Float3 > d_x0, DeviceBuffer< Float3 > d_v, DeviceBuffer< Float3 > d_f, DeviceBuffer< float > d_inverseMasses, float dt, bool doTemperatureScaling, int numTempScaleValues, DeviceBuffer< unsigned short > d_tempScaleGroups, DeviceBuffer< float > d_lambdas, ParrinelloRahmanVelocityScaling parrinelloRahmanVelocityScaling, Float3 prVelocityScalingMatrixDiagonal, const DeviceStream &deviceStream) | ||
| Backend-specific function to launch GPU Leap Frog kernel. More... | |||
| template<NumTempScaleValues numTempScaleValues, ParrinelloRahmanVelocityScaling parrinelloRahmanVelocityScaling> | |||
| auto | leapFrogKernel (Float3 *__restrict__ gm_x, Float3 *__restrict__ gm_x0, Float3 *__restrict__ gm_v, const Float3 *__restrict__ gm_f, const float *__restrict__ gm_inverseMasses, float dt, const float *__restrict__ gm_lambdas, const unsigned short *__restrict__ gm_tempScaleGroups, Float3 prVelocityScalingMatrixDiagonal) | ||
| Main kernel for the Leap-Frog integrator. More... | |||
| template<NumTempScaleValues numTempScaleValues, ParrinelloRahmanVelocityScaling parrinelloRahmanVelocityScaling, class... Args> | |||
| static void | launchLeapFrogKernel (const DeviceStream &deviceStream, int numAtoms, Args &&...args) | ||
| Leap Frog SYCL kernel launch code. | |||
| template<class... Args> | |||
| static void | launchLeapFrogKernel (NumTempScaleValues tempScalingType, ParrinelloRahmanVelocityScaling parrinelloRahmanVelocityScaling, Args &&...args) | ||
| Select templated kernel and launch it. | |||
| real | lincs_rmsd (const Lincs *lincsd) | ||
| Return the RMSD of the constraint. | |||
| static void | lincs_matrix_expand (const Lincs &lincsd, const Task &li_task, gmx::ArrayRef< const real > blcc, gmx::ArrayRef< real > rhs1, gmx::ArrayRef< real > rhs2, gmx::ArrayRef< real > sol) | ||
| Do a set of nrec LINCS matrix multiplications. More... | |||
| static void | lincs_update_atoms_noind (int ncons, gmx::ArrayRef< const AtomPair > atoms, real preFactor, gmx::ArrayRef< const real > fac, gmx::ArrayRef< const gmx::RVec > r, gmx::ArrayRef< const real > invmass, rvec *x) | ||
| Update atomic coordinates when an index is not required. | |||
| static void | lincs_update_atoms_ind (gmx::ArrayRef< const int > ind, gmx::ArrayRef< const AtomPair > atoms, real preFactor, gmx::ArrayRef< const real > fac, gmx::ArrayRef< const gmx::RVec > r, gmx::ArrayRef< const real > invmass, rvec *x) | ||
| Update atomic coordinates when an index is required. | |||
| static void | lincs_update_atoms (Lincs *li, int th, real preFactor, gmx::ArrayRef< const real > fac, gmx::ArrayRef< const gmx::RVec > r, gmx::ArrayRef< const real > invmass, rvec *x) | ||
| Update coordinates for atoms. | |||
| static void | do_lincsp (ArrayRefWithPadding< const RVec > xPadded, ArrayRefWithPadding< RVec > fPadded, ArrayRef< RVec > fp, t_pbc *pbc, Lincs *lincsd, int th, ArrayRef< const real > invmass, ConstraintVariable econq, bool bCalcDHDL, bool bCalcVir, tensor rmdf) | ||
| LINCS projection, works on derivatives of the coordinates. | |||
| static gmx_unused void | calc_dist_iter (int b0, int b1, gmx::ArrayRef< const AtomPair > atoms, const rvec *gmx_restrict xp, const real *gmx_restrict bllen, const real *gmx_restrict blc, const t_pbc *pbc, real wfac, real *gmx_restrict rhs, real *gmx_restrict sol, bool *bWarn) | ||
| Determine the distances and right-hand side for the next iteration. | |||
| static void | do_lincs (ArrayRefWithPadding< const RVec > xPadded, ArrayRefWithPadding< RVec > xpPadded, const matrix box, t_pbc *pbc, Lincs *lincsd, int th, ArrayRef< const real > invmass, gmx_domdec_t *dd, bool bCalcDHDL, real wangle, bool *bWarn, real invdt, ArrayRef< RVec > vRef, bool bCalcVir, tensor vir_r_m_dr, gmx_wallcycle *wcycle) | ||
| Implements LINCS constraining. | |||
| static void | set_lincs_matrix_task (Lincs *li, Task *li_task, ArrayRef< const real > invmass, int *ncc_triangle, int *nCrossTaskTriangles) | ||
| Sets the elements in the LINCS matrix for task task. | |||
| static void | set_lincs_matrix (Lincs *li, ArrayRef< const real > invmass, real lambda) | ||
| Sets the elements in the LINCS matrix. | |||
| int | count_triangle_constraints (const InteractionLists &ilist, const ListOfLists< int > &at2con) | ||
| Counts the number of constraint triangles, i.e. triplets of atoms connected by three constraints. More... | |||
| static bool | more_than_two_sequential_constraints (const InteractionLists &ilist, const ListOfLists< int > &at2con) | ||
| Finds sequences of sequential constraints. | |||
| Lincs * | init_lincs (FILE *fplog, const gmx_mtop_t &mtop, int nflexcon_global, ArrayRef< const ListOfLists< int >> atomsToConstraintsPerMolType, bool bPLINCS, int nIter, int nProjOrder, ObservablesReducerBuilder *observablesReducerBuilder) | ||
| Initializes and returns the lincs data struct. | |||
| void | done_lincs (Lincs *li) | ||
| Destructs the lincs object when it is not nullptr. | |||
| static void | lincs_thread_setup (Lincs *li, int natoms) | ||
| Sets up the work division over the threads. | |||
| static void | assign_constraint (Lincs *li, int constraint_index, int a1, int a2, real lenA, real lenB, const ListOfLists< int > &at2con) | ||
| Assign a constraint. | |||
| static void | check_assign_connected (Lincs *li, gmx::ArrayRef< const int > iatom, const InteractionDefinitions &idef, bool bDynamics, int a1, int a2, const ListOfLists< int > &at2con) | ||
| Check if constraint with topology index constraint_index is connected to other constraints, and if so add those connected constraints to our task. | |||
| static void | check_assign_triangle (Lincs *li, gmx::ArrayRef< const int > iatom, const InteractionDefinitions &idef, bool bDynamics, int constraint_index, int a1, int a2, const ListOfLists< int > &at2con) | ||
| Check if constraint with topology index constraint_index is involved in a constraint triangle, and if so add the other two constraints in the triangle to our task. | |||
| static void | set_matrix_indices (Lincs *li, const Task &li_task, const ListOfLists< int > &at2con, bool bSortMatrix) | ||
| Sets matrix indices. | |||
| void | set_lincs (const InteractionDefinitions &idef, int numAtoms, ArrayRef< const real > invmass, real lambda, bool bDynamics, const gmx_domdec_t *dd, Lincs *li) | ||
| Initialize lincs stuff. | |||
| static void | lincs_warning (gmx_domdec_t *dd, ArrayRef< const RVec > x, ArrayRef< const RVec > xprime, t_pbc *pbc, int ncons, gmx::ArrayRef< const AtomPair > atoms, gmx::ArrayRef< const real > bllen, real wangle, int maxwarn, int *warncount) | ||
| Issues a warning when LINCS constraints cannot be satisfied. | |||
| static LincsDeviations | makeLincsDeviations (const Lincs &lincsd, ArrayRef< const RVec > x, const t_pbc *pbc) | ||
| Determine how well the constraints have been satisfied. | |||
| bool | constrain_lincs (bool computeRmsd, const t_inputrec &ir, int64_t step, Lincs *lincsd, ArrayRef< const real > invmass, gmx_domdec_t *dd, const gmx_multisim_t *ms, ArrayRefWithPadding< const RVec > x, ArrayRefWithPadding< RVec > xprime, ArrayRef< RVec > min_proj, const matrix box, t_pbc *pbc, bool hasMassPerturbed, real lambda, real *dvdlambda, real invdt, ArrayRef< RVec > v, bool bCalcVir, tensor vir_r_m_dr, ConstraintVariable econq, t_nrnb *nrnb, int maxwarn, int *warncount, gmx_wallcycle *wcycle) | ||
| Applies LINCS constraints. More... | |||
| void | addWithCoupled (ArrayRef< const int > iatoms, const int stride, const gmx::ListOfLists< AtomsAdjacencyListElement > &atomsAdjacencyList, ArrayRef< int > splitMap, const int c, int *currentMapIndex) | ||
Add constraint to splitMap with all constraints coupled to it. More... | |||
| void | launchLincsGpuKernel (LincsGpuKernelParameters *kernelParams, const DeviceBuffer< Float3 > &d_x, DeviceBuffer< Float3 > d_xp, bool updateVelocities, DeviceBuffer< Float3 > d_v, real invdt, bool computeVirial, const DeviceStream &deviceStream) | ||
| Backend-specific function to launch LINCS kernel. More... | |||
| template<bool updateVelocities, bool computeVirial, bool haveCoupledConstraints> | |||
| auto | lincsKernel (sycl::handler &cgh, const int numConstraintsThreads, const AtomPair *__restrict__ gm_constraints, const float *__restrict__ gm_constraintsTargetLengths, const int *__restrict__ gm_coupledConstraintsCounts, const int *__restrict__ gm_coupledConstraintsIndices, const float *__restrict__ gm_massFactors, float *__restrict__ gm_matrixA, const float *__restrict__ gm_inverseMasses, const int numIterations, const int expansionOrder, const Float3 *__restrict__ gm_x, Float3 *__restrict__ gm_xp, const float invdt, Float3 *__restrict__ gm_v, float *__restrict__ gm_virialScaled, PbcAiuc pbcAiuc) | ||
| Main kernel for LINCS constraints. More... | |||
| template<bool updateVelocities, bool computeVirial, bool haveCoupledConstraints, class... Args> | |||
| static void | launchLincsKernel (const DeviceStream &deviceStream, const int numConstraintsThreads, Args &&...args) | ||
| template<class... Args> | |||
| static void | launchLincsKernel (bool updateVelocities, bool computeVirial, bool haveCoupledConstraints, Args &&...args) | ||
| Select templated kernel and launch it. | |||
| template<typename... Args> | |||
| std::unique_ptr< Constraints > | makeConstraints (const gmx_mtop_t &mtop, const t_inputrec &ir, pull_t *pull_work, bool havePullConstraintsWork, bool doEssentialDynamics, Args &&...args) | ||
| Factory function for Constraints. More... | |||
| std::unique_ptr< MDAtoms > | makeMDAtoms (FILE *fp, const gmx_mtop_t &mtop, const t_inputrec &ir, bool useGpuForPme) | ||
| Builder function for MdAtomsWrapper. More... | |||
| static ResetSignal | convertToResetSignal (signed char sig) | ||
| Convert signed char (as used by SimulationSignal) to ResetSignal enum. More... | |||
| static void | initializeProjectionMatrix (const real invmO, const real invmH, const real dOH, const real dHH, matrix inverseCouplingMatrix) | ||
| Initializes a projection matrix. More... | |||
| SettleParameters | settleParameters (real mO, real mH, real invmO, real invmH, real dOH, real dHH) | ||
| Computes and returns settle parameters. More... | |||
| void | settle_proj (const SettleData &settled, ConstraintVariable econq, int nsettle, const int iatoms[], const t_pbc *pbc,ArrayRef< const RVec > x, ArrayRef< RVec > der, ArrayRef< RVec > derp, int CalcVirAtomEnd, tensor vir_r_m_dder) | ||
| Analytical algorithm to subtract the components of derivatives of coordinates working on settle type constraint. | |||
| template<typename T , typename TypeBool , int packSize, typename TypePbc , bool bCorrectVelocity, bool bCalcVirial> | |||
| static void | settleTemplate (const SettleData &settled, int settleStart, int settleEnd, const TypePbc pbc, const real *x, real *xprime, real invdt, real *gmx_restrict v, tensor vir_r_m_dr, bool *bErrorHasOccurred) | ||
| The actual settle code, templated for real/SimdReal and for optimization. | |||
| template<typename T , typename TypeBool , int packSize, typename TypePbc > | |||
| static void | settleTemplateWrapper (const SettleData &settled, int nthread, int thread, TypePbc pbc, const real x[], real xprime[], real invdt, real *v, bool bCalcVirial, tensor vir_r_m_dr, bool *bErrorHasOccurred) | ||
| Wrapper template function that divides the settles over threads and instantiates the core template with instantiated booleans. | |||
| void | csettle (const SettleData &settled,int nthread,int thread,const t_pbc *pbc,ArrayRefWithPadding< const RVec > x,ArrayRefWithPadding< RVec > xprime,real invdt,ArrayRefWithPadding< RVec > v,bool bCalcVirial,tensor vir_r_m_dr,bool *bErrorHasOccurred) | ||
| Constrain coordinates using SETTLE. Can be called on any number of threads. | |||
| void | launchSettleGpuKernel (int numSettles, const DeviceBuffer< WaterMolecule > &d_atomIds, const SettleParameters &settleParameters, const DeviceBuffer< Float3 > &d_x, DeviceBuffer< Float3 > d_xp, bool updateVelocities, DeviceBuffer< Float3 > d_v, real invdt, bool computeVirial, DeviceBuffer< float > d_virialScaled, const PbcAiuc &pbcAiuc, const DeviceStream &deviceStream) | ||
| Apply SETTLE. More... | |||
| template<bool updateVelocities, bool computeVirial> | |||
| auto | settleKernel (sycl::handler &cgh, const int numSettles, const WaterMolecule *__restrict__ gm_settles, SettleParameters pars, const Float3 *__restrict__ gm_x, Float3 *__restrict__ gm_xp, float invdt, Float3 *__restrict__ gm_v, float *__restrict__ gm_virialScaled, PbcAiuc pbcAiuc) | ||
| Function returning the SETTLE kernel lambda. | |||
| template<bool updateVelocities, bool computeVirial, class... Args> | |||
| static void | launchSettleKernel (const DeviceStream &deviceStream, int numSettles, Args &&...args) | ||
| SETTLE SYCL kernel launch code. | |||
| template<class... Args> | |||
| static void | launchSettleKernel (bool updateVelocities, bool computeVirial, Args &&...args) | ||
| Select templated kernel and launch it. | |||
| static int | pcomp (const void *p1, const void *p2) | ||
| Compares sort blocks. | |||
| static void | pr_sortblock (FILE *fp, const char *title, gmx::ArrayRef< const t_sortblock > sb) | ||
| Prints sortblocks. | |||
| static void | resizeLagrangianData (shakedata *shaked, int ncons) | ||
| Reallocates a vector. | |||
| void | make_shake_sblock_serial (shakedata *shaked, InteractionDefinitions *idef, int numAtoms) | ||
| Make SHAKE blocks when not using DD. | |||
| void | make_shake_sblock_dd (shakedata *shaked, const InteractionList &ilcon) | ||
| Make SHAKE blocks when using DD. | |||
| void | cshake (const int iatom[], int ncon, int *nnit, int maxnit, ArrayRef< const real > constraint_distance_squared, ArrayRef< RVec > positions, const t_pbc *pbc, ArrayRef< const RVec > initial_displacements, ArrayRef< const real > half_of_reduced_mass, real omega, ArrayRef< const real > invmass, ArrayRef< const real > distance_squared_tolerance, ArrayRef< real > scaled_lagrange_multiplier, int *nerror) | ||
| Inner kernel for SHAKE constraints. More... | |||
| static void | crattle (const int iatom[], int ncon, int *nnit, int maxnit, ArrayRef< const real > constraint_distance_squared, ArrayRef< RVec > vp, ArrayRef< const RVec > rij, ArrayRef< const real > m2, real omega, ArrayRef< const real > invmass, ArrayRef< const real > distance_squared_tolerance, ArrayRef< real > scaled_lagrange_multiplier, int *nerror, real invdt) | ||
| Implements RATTLE (ie. SHAKE for velocity verlet integrators) | |||
| static int | vec_shakef (FILE *fplog, shakedata *shaked, ArrayRef< const real > invmass, int ncon, ArrayRef< const t_iparams > ip, const int *iatom, real tol, ArrayRef< const RVec > x, ArrayRef< RVec > prime, const t_pbc *pbc, real omega, bool bFEP, real lambda, ArrayRef< real > scaled_lagrange_multiplier, real invdt, ArrayRef< RVec > v, bool bCalcVir, tensor vir_r_m_dr, ConstraintVariable econq) | ||
| Applies SHAKE. | |||
| static void | check_cons (FILE *log, int nc, ArrayRef< const RVec > x, ArrayRef< const RVec > prime, ArrayRef< const RVec > v, const t_pbc *pbc, ArrayRef< const t_iparams > ip, const int *iatom, ArrayRef< const real > invmass, ConstraintVariable econq) | ||
| Check that constraints are satisfied. | |||
| static bool | bshakef (FILE *log, shakedata *shaked, ArrayRef< const real > invmass, const InteractionDefinitions &idef, const t_inputrec &ir, ArrayRef< const RVec > x_s, ArrayRef< RVec > prime, const t_pbc *pbc, t_nrnb *nrnb, real lambda, real *dvdlambda, real invdt, ArrayRef< RVec > v, bool bCalcVir, tensor vir_r_m_dr, bool bDumpOnError, ConstraintVariable econq) | ||
| Applies SHAKE. | |||
| bool | constrain_shake (FILE *log,shakedata *shaked,gmx::ArrayRef< const real > invmass,const InteractionDefinitions &idef,const t_inputrec &ir,ArrayRef< const RVec > x_s,ArrayRef< RVec > xprime,ArrayRef< RVec > vprime,const t_pbc *pbc,t_nrnb *nrnb,real lambda,real *dvdlambda,real invdt,ArrayRef< RVec > v,bool bCalcVir,tensor vir_r_m_dr,bool bDumpOnError,ConstraintVariable econq) | ||
| Shake all the atoms blockwise. It is assumed that all the constraints in the idef->shakes field are sorted, to ascending block nr. The sblock array points into the idef->shakes.iatoms field, with block 0 starting at sblock[0] and running to ( < ) sblock[1], block n running from sblock[n] to sblock[n+1]. Array sblock should be large enough. Return TRUE when OK, FALSE when shake-error. | |||
| static void | sum_forces (ArrayRef< RVec > f, ArrayRef< const RVec > forceToAdd) | ||
| static void | calc_virial (int start, int homenr, const rvec x[], const ForceWithShiftForces &forceWithShiftForces, tensor vir_part, const matrix box, t_nrnb *nrnb, const t_forcerec *fr, PbcType pbcType) | ||
| static void | pull_potential_wrapper (const MpiComm &mpiComm, const t_inputrec &ir, const matrix box, ArrayRef< const RVec > x, const t_mdatoms *mdatoms, gmx_enerdata_t *enerd, pull_t *pull_work, const real *lambda, double t, gmx_wallcycle *wcycle) | ||
| static void | pme_receive_force_ener (t_forcerec *fr, gmx_domdec_t *dd, ForceWithVirial *forceWithVirial, gmx_enerdata_t *enerd, bool useGpuPmePpComms, bool receivePmeForceToGpu, gmx_wallcycle *wcycle) | ||
| static void | print_large_forces (FILE *fp, const t_mdatoms *md, const gmx_domdec_t *dd, int64_t step, real forceTolerance, ArrayRef< const RVec > x, ArrayRef< const RVec > f) | ||
| static void | postProcessForceWithShiftForces (t_nrnb *nrnb, gmx_wallcycle *wcycle, const matrix box, ArrayRef< const RVec > x, ForceOutputs *forceOutputs, tensor vir_force, const t_mdatoms &mdatoms, const t_forcerec &fr, VirtualSitesHandler *vsite, const StepWorkload &stepWork) | ||
When necessary, spreads forces on vsites and computes the virial for forceOutputs->forceWithShiftForces() | |||
| static void | postProcessForces (const gmx_domdec_t *dd, int64_t step, t_nrnb *nrnb, gmx_wallcycle *wcycle, const matrix box, ArrayRef< const RVec > x, ForceOutputs *forceOutputs, tensor vir_force, const t_mdatoms *mdatoms, const t_forcerec *fr, VirtualSitesHandler *vsite, const StepWorkload &stepWork) | ||
| Spread, compute virial for and sum forces, when necessary. | |||
| static void | do_nb_verlet (t_forcerec *fr, const interaction_const_t *ic, gmx_enerdata_t *enerd, const StepWorkload &stepWork, const InteractionLocality ilocality, const int clearF, const int64_t step, t_nrnb *nrnb, gmx_wallcycle *wcycle) | ||
| static void | clearRVecs (ArrayRef< RVec > v, const bool useOpenmpThreading) | ||
| static real | averageKineticEnergyEstimate (const t_grpopts &groupOptions) | ||
| Return an estimate of the average kinetic energy or 0 when unreliable. More... | |||
| static void | checkPotentialEnergyValidity (int64_t step, const gmx_enerdata_t &enerd, const t_inputrec &inputrec) | ||
| This routine checks that the potential energy is finite. More... | |||
| static void | computeSpecialForces (FILE *fplog, const MpiComm &mpiComm, const gmx_domdec_t *dd, const t_inputrec &inputrec, Awh *awh, gmx_enfrot *enforcedRotation, ImdSession *imdSession, pull_t *pull_work, int64_t step, double t, gmx_wallcycle *wcycle, ForceProviders *forceProviders, const matrix box, ArrayRef< const RVec > x, const t_mdatoms *mdatoms, ArrayRef< const real > lambda, const StepWorkload &stepWork, ForceWithVirial *forceWithVirialMtsLevel0, ForceWithVirial *forceWithVirialMtsLevel1, gmx_enerdata_t *enerd, gmx_edsam *ed, bool didNeighborSearch) | ||
| Compute forces and/or energies for special algorithms. More... | |||
| static void | launchPmeGpuSpread (gmx_pme_t *pmedata, const matrix box, const SimulationWorkload &simulationWork, const StepWorkload &stepWork, GpuEventSynchronizer *xReadyOnDevice, const real lambdaQ, bool useMdGpuGraph, gmx_wallcycle *wcycle) | ||
| Launch the prepare_step and spread stages of PME GPU. More... | |||
| static void | launchPmeGpuFftAndGather (gmx_pme_t *pmedata, const real lambdaQ, gmx_wallcycle *wcycle, const StepWorkload &stepWork) | ||
| Launch the FFT and gather stages of PME GPU. More... | |||
| static void | pmeGpuWaitAndReduce (gmx_pme_t *pme, const StepWorkload &stepWork, gmx_wallcycle *wcycle, ForceWithVirial *forceWithVirial, gmx_enerdata_t *enerd, const real lambdaQ) | ||
| Blocks until PME GPU tasks are completed, and gets the output forces and virial/energy (if they were to be computed). More... | |||
| static void | alternatePmeNbGpuWaitReduce (nonbonded_verlet_t *nbv, gmx_pme_t *pmedata, ForceOutputs *forceOutputsNonbonded, ForceOutputs *forceOutputsPme, gmx_enerdata_t *enerd, const real lambdaQ, const StepWorkload &stepWork, const SimulationWorkload &simulationWork, gmx_wallcycle *wcycle) | ||
| Polling wait for either of the PME or nonbonded GPU tasks. More... | |||
| static ForceOutputs | setupForceOutputs (ForceHelperBuffers *forceHelperBuffers, ArrayRefWithPadding< RVec > force, const DomainLifetimeWorkload &domainWork, const StepWorkload &stepWork, const bool havePpDomainDecomposition, gmx_wallcycle *wcycle) | ||
| Set up the different force buffers; also does clearing. More... | |||
| static void | launchGpuEndOfStepTasks (nonbonded_verlet_t *nbv, ListedForcesGpu *listedForcesGpu, gmx_pme_t *pmedata, gmx_enerdata_t *enerd, const MdrunScheduleWorkload &runScheduleWork, int64_t step, gmx_wallcycle *wcycle) | ||
| static int | getExpectedLocalXReadyOnDeviceConsumptionCount (const SimulationWorkload &simulationWork, const StepWorkload &stepWork, const DomainLifetimeWorkload &domainWork, const bool pmeSendCoordinatesFromGpu, const bool domainHasHomeAtoms) | ||
| Compute the number of times the "local coordinates ready on device" GPU event will be used as a synchronization point. More... | |||
| static int | getExpectedLocalFReadyOnDeviceConsumptionCount (const SimulationWorkload &simulationWork, const DomainLifetimeWorkload &domainWork, const StepWorkload &stepWork, bool useOrEmulateGpuNb, bool alternateGpuWait) | ||
| Compute the number of times the "local forces ready on device" GPU event will be used as a synchronization point. More... | |||
| static void | reduceAndUpdateMuTot (DipoleData *dipoleData, const MpiComm &mpiComm, const bool haveFreeEnergy, ArrayRef< const real > lambda, rvec muTotal, const DDBalanceRegionHandler &ddBalanceRegionHandler) | ||
| static void | combineMtsForces (const int numAtoms, ArrayRef< RVec > forceMtsLevel0, ArrayRef< RVec > forceMts, const real mtsFactor) | ||
| Combines MTS level0 and level1 force buffers into a full and MTS-combined force buffer. More... | |||
| static void | setupLocalGpuForceReduction (const MdrunScheduleWorkload &runScheduleWork, nonbonded_verlet_t *nbv, StatePropagatorDataGpu *stateGpu, GpuForceReduction *gpuForceReduction, PmePpCommGpu *pmePpCommGpu, const gmx_pme_t *pmedata, const gmx_domdec_t *dd) | ||
| Setup for the local GPU force reduction: reinitialization plus the registration of forces and dependencies. More... | |||
| static void | setupNonLocalGpuForceReduction (const MdrunScheduleWorkload &runScheduleWork, nonbonded_verlet_t *nbv, StatePropagatorDataGpu *stateGpu, GpuForceReduction *gpuForceReduction, const gmx_domdec_t *dd) | ||
| Setup for the non-local GPU force reduction: reinitialization plus the registration of forces and dependencies. More... | |||
| static int | getLocalAtomCount (const gmx_domdec_t *dd, const t_mdatoms &mdatoms, bool havePPDomainDecomposition) | ||
| Return the number of local atoms. | |||
| static void | doPairSearch (const t_commrec *cr, const t_inputrec &inputrec, const MDModulesNotifiers &mdModulesNotifiers, int64_t step, t_nrnb *nrnb, gmx_wallcycle *wcycle, const gmx_localtop_t &top, const matrix box, ArrayRefWithPadding< RVec > x, ArrayRef< RVec > v, const t_mdatoms &mdatoms, t_forcerec *fr, const MdrunScheduleWorkload &runScheduleWork) | ||
| Does pair search and closely related activities required on search steps. | |||
| static StopSignal | convertToStopSignal (signed char sig) | ||
| Convert signed char (as used by SimulationSignal) to StopSignal enum. More... | |||
| void | launchScaleCoordinatesKernel (int numAtoms, DeviceBuffer< Float3 > d_coordinates, const ScalingMatrix &mu, const DeviceStream &deviceStream) | ||
| Launches positions of velocities scaling kernel. More... | |||
| static auto | scaleKernel (Float3 *gm_x, const ScalingMatrix &scalingMatrix) | ||
| Function returning the scaling kernel lambda. | |||
| static bool | hasFlexibleConstraints (const gmx_moltype_t &moltype, gmx::ArrayRef< const t_iparams > iparams) | ||
Returns whether moltype contains flexible constraints. | |||
| static bool | hasIncompatibleVsites (const gmx_moltype_t &moltype, gmx::ArrayRef< const t_iparams > iparams) | ||
| Returns whether moltype has incompatible vsites. More... | |||
| static InteractionList | jointConstraintList (const gmx_moltype_t &moltype) | ||
| Returns a merged list with constraints of all types. | |||
| static AtomIndexExtremes | vsiteConstructRange (int a, const gmx_moltype_t &moltype) | ||
Returns the range of constructing atom for vsite with atom index a. | |||
| static AtomIndexExtremes | constraintAtomRange (int a, const ListOfLists< int > &at2con, const InteractionList &ilistConstraints) | ||
Returns the range of atoms constrained to atom a (including a itself) | |||
| static std::vector< bool > | buildIsParticleVsite (const gmx_moltype_t &moltype) | ||
Returns a list that tells whether atoms in moltype are vsites. | |||
|
static std::variant< int, IncompatibilityReasons > | detectGroup (int firstAtom, const gmx_moltype_t &moltype, const ListOfLists< int > &at2con, const InteractionList &ilistConstraints) | ||
Returns the size of the update group starting at firstAtom or an incompatibility reason. | |||
|
static std::variant < RangePartitioning, IncompatibilityReasons > | makeUpdateGroupingsPerMoleculeType (const gmx_moltype_t &moltype, gmx::ArrayRef< const t_iparams > iparams) | ||
Returns a list of update groups for moltype or an incompatibility reason. | |||
| std::variant< std::vector < RangePartitioning > , std::string > | makeUpdateGroupingsPerMoleculeType (const gmx_mtop_t &mtop) | ||
Returns a vector with update groups for each moleculetype in mtop or an error string when the criteria (see below) are not satisfied. More... | |||
|
static std::unordered_multimap < int, int > | getAngleIndices (const gmx_moltype_t &moltype) | ||
| Returns a map of angles ilist.iatoms indices with the middle atom as key. | |||
| template<int numPartnerAtoms> | |||
| static real | constraintGroupRadius (const gmx_moltype_t &moltype, gmx::ArrayRef< const t_iparams > iparams, const int centralAtom, const ListOfLists< int > &at2con, const std::unordered_multimap< int, int > &angleIndices, const real constraintLength, const real temperature) | ||
| When possible, computes the maximum radius of constrained atom in an update group. More... | |||
| static real | computeMaxUpdateGroupRadius (const gmx_moltype_t &moltype, gmx::ArrayRef< const t_iparams > iparams, const RangePartitioning &updateGrouping, real temperature) | ||
Returns the maximum update group radius for moltype. | |||
| real | computeMaxUpdateGroupRadius (const gmx_mtop_t &mtop, ArrayRef< const RangePartitioning > updateGroupingPerMoleculeType, real temperature) | ||
| Returns the maximum update group radius. More... | |||
| bool | systemHasConstraintsOrVsites (const gmx_mtop_t &mtop) | ||
| Returns whether mtop contains any constraints and/or vsites. More... | |||
| UpdateGroups | makeUpdateGroups (const gmx::MDLogger &mdlog, std::vector< RangePartitioning > &&updateGroupingPerMoleculeType, real maxUpdateGroupRadius, bool doRerun, bool useDomainDecomposition, bool systemHasConstraintsOrVsites, real cutoffMargin) | ||
| Builder for update groups. More... | |||
| static int | vsiteIlistNrCount (const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist) | ||
| Returns the sum of the vsite ilist sizes over all vsite types. More... | |||
| static int | pbc_rvec_sub (const t_pbc *pbc, const rvec xi, const rvec xj, rvec dx) | ||
| Computes the distance between xi and xj, pbc is used when pbc!=nullptr. | |||
| static real | inverseNorm (const rvec x) | ||
| Returns the 1/norm(x) | |||
| static PbcMode | getPbcMode (const t_pbc *pbcPtr) | ||
| Returns the PBC mode based on the system PBC and vsite properties. More... | |||
| template<VSiteCalculatePosition calculatePosition, VSiteCalculateVelocity calculateVelocity> | |||
| static void | construct_vsites_thread (ArrayRef< RVec > x, ArrayRef< RVec > v, ArrayRef< const t_iparams > ip, const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist, const t_pbc *pbc_null) | ||
| Executes the vsite construction task for a single thread. More... | |||
| template<VSiteCalculatePosition calculatePosition, VSiteCalculateVelocity calculateVelocity> | |||
| static void | construct_vsites (const ThreadingInfo *threadingInfo, ArrayRef< RVec > x, ArrayRef< RVec > v, ArrayRef< const t_iparams > ip, const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist, const DomainInfo &domainInfo, const matrix box) | ||
| Dispatch the vsite construction tasks for all threads. More... | |||
| void | constructVirtualSites (ArrayRef< RVec > x, ArrayRef< const t_iparams > ip, const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist) | ||
| Create positions of vsite atoms based for the local system. More... | |||
| static int | vsite_count (const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist, InteractionFunction ftype) | ||
| Returns the number of virtual sites in the interaction list, for VSITEN the number of atoms. | |||
| template<VirialHandling virialHandling> | |||
| static void | spreadForceForThread (ArrayRef< const RVec > x, ArrayRef< RVec > f, ArrayRef< RVec > fshift, matrix dxdf, ArrayRef< const t_iparams > ip, const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist, const t_pbc *pbc_null) | ||
| Executes the force spreading task for a single thread. | |||
| static void | spreadForceWrapper (ArrayRef< const RVec > x, ArrayRef< RVec > f, const VirialHandling virialHandling, ArrayRef< RVec > fshift, matrix dxdf, const bool clearDxdf, ArrayRef< const t_iparams > ip, const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist, const t_pbc *pbc_null) | ||
| Wrapper function for calling the templated thread-local spread function. | |||
| static void | clearTaskForceBufferUsedElements (InterdependentTask *idTask) | ||
| Clears the task force buffer elements that are written by task idTask. | |||
| static std::vector< int > | makeAtomToGroupMapping (const gmx::RangePartitioning &grouping) | ||
| Returns the an array with group indices for each atom. More... | |||
| int | countNonlinearVsites (const gmx_mtop_t &mtop) | ||
| Return the number of non-linear virtual site constructions in the system. | |||
| int | countInterUpdategroupVsites (const gmx_mtop_t &mtop, ArrayRef< const RangePartitioning > updateGroupingsPerMoleculeType) | ||
| Return the number of virtual sites that cross update groups. More... | |||
| std::unique_ptr < VirtualSitesHandler > | makeVirtualSitesHandler (const gmx_mtop_t &mtop, gmx_domdec_t *domdec, PbcType pbcType, ArrayRef< const RangePartitioning > updateGroupingPerMoleculeType) | ||
| Create the virtual site handler. More... | |||
| iparams_ (mtop.ffparams.iparams) | |||
| static void | flagAtom (InterdependentTask *idTask, const int atom, const int numThreads, const int numAtomsPerThread) | ||
Flag that atom atom which is home in another task, if it has not already been added before. | |||
| static void | assignVsitesToThread (VsiteThread *tData, int thread, int nthread, int natperthread, gmx::ArrayRef< int > taskIndex, const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist, ArrayRef< const t_iparams > ip, ArrayRef< const ParticleType > ptype) | ||
| Here we try to assign all vsites that are in our local range. More... | |||
| static void | assignVsitesToSingleTask (VsiteThread *tData, int task, gmx::ArrayRef< const int > taskIndex, const gmx::EnumerationArray< InteractionFunction, InteractionList > *ilist, ArrayRef< const t_iparams > ip) | ||
| Assign all vsites with taskIndex[]==task to task tData. | |||
| void | constructVirtualSitesGlobal (const gmx_mtop_t &mtop, ArrayRef< RVec > x) | ||
| Create positions of vsite atoms for the whole system assuming all molecules are wholex. More... | |||
| void | printBinaryInformation (FILE *fp, const IProgramContext &programContext, const BinaryInformationSettings &settings) | ||
| Print basic information about the executable with custom settings. More... | |||
| void | printBinaryInformation (TextWriter *writer, const IProgramContext &programContext, const BinaryInformationSettings &settings) | ||
| Print basic information about the executable with custom settings. More... | |||
| static bool | is_multisim_option_set (int argc, const char *const argv[]) | ||
| Return whether the command-line parameter that will trigger a multi-simulation is set. | |||
| static DevelopmentFeatureFlags | manageDevelopmentFeatures (const gmx::MDLogger &mdlog, const PmeRunMode pmeRunMode, const int numRanksPerSimulation, const int numPmeRanksPerSimulation, const bool canUseGpuAwareMpi) | ||
| Manage any development feature flag variables encountered. More... | |||
| static void | threadMpiMdrunnerAccessBarrier () | ||
| Barrier for safe simultaneous thread access to mdrunner data. More... | |||
| static void | mdrunner_start_fn (const void *arg) | ||
| The callback used for running on spawned threads. More... | |||
| static gmx::LoggerOwner | buildLogger (FILE *fplog, const bool isSimulationMainRank) | ||
| Initializes the logger for mdrun. | |||
| static TaskTarget | findTaskTarget (const char *optionString) | ||
| Make a TaskTarget from an mdrun argument string. | |||
| static void | finish_run (FILE *fplog, const gmx::MDLogger &mdlog, const t_commrec *cr, const t_inputrec &inputrec, t_nrnb nrnb[], gmx_wallcycle *wcycle, gmx_walltime_accounting_t walltime_accounting, nonbonded_verlet_t *nbv, const gmx_pme_t *pme, const int nratoms, gmx_bool bWriteStat) | ||
| Finish run, aggregate data to print performance info. | |||
| static bool | localStateHasFillerParticles (const gmx_mtop_t &mtop, const t_inputrec &inputrec, const bool useDomainDecomposition, const bool haveSinglePPRank, const bool useGpuDirectHalo) | ||
| Returns whether the run conditions permit the local state to have filler particles. | |||
| void | applyLocalState (const SimulationInput &simulationInput, t_fileio *logfio, const MpiComm &mpiCommSimulation, t_inputrec *ir, t_state *state, ObservablesHistory *observablesHistory, bool reproducibilityRequested, const MDModulesNotifiers ¬ifiers, gmx::ReadCheckpointDataHolder *modularSimulatorCheckpointData, bool useModularSimulator) | ||
| Initialize local stateful simulation data. More... | |||
| SimulationInputHandle | makeSimulationInput (const LegacyMdrunOptions &options) | ||
| static void | global_max (const MpiComm &mpiComm, int *n) | ||
| Global max algorithm. | |||
| static real | reactionFieldExclusionCorrection (gmx::ArrayRef< const gmx::RVec > x, const t_mdatoms &mdatoms, const interaction_const_t &ic, const int beginAtom) | ||
Computes and returns the RF exclusion energy for the last molecule starting at beginAtom. | |||
| int | computeFepPeriod (const t_inputrec &inputrec, const ReplicaExchangeParameters &replExParams) | ||
| Compute the period at which FEP calculation is performed. More... | |||
| std::tuple< StartingBehavior, LogFilePtr > | handleRestart (bool isSimulationMain, MPI_Comm communicator, const gmx_multisim_t *ms, AppendingBehavior appendingBehavior, int nfile, t_filenm fnm[]) | ||
| Handle startup of mdrun, particularly regarding -cpi and -append. More... | |||
| static void | prepareLogFile (BinaryInformationSettings settings, FILE *fplog) | ||
| Implements aspects of logfile handling common to opening either for writing or appending. | |||
| LogFilePtr | openLogFile (const char *lognm, bool appendFiles) | ||
| Open the log file for writing/appending. More... | |||
| void | prepareLogAppending (FILE *fplog) | ||
| Prepare to use the open log file when appending. More... | |||
| void | closeLogFile (t_fileio *logfio) | ||
| Close the log file. | |||
| template<class BasicMdspan > | |||
| constexpr std::enable_if_t < BasicMdspan::is_always_contiguous(), typename BasicMdspan::pointer > | begin (const BasicMdspan &basicMdspan) | ||
| Free begin function addressing memory of a contiguously laid out basic_mdspan. More... | |||
| template<class BasicMdspan > | |||
| constexpr std::enable_if_t < BasicMdspan::is_always_contiguous(), typename BasicMdspan::pointer > | end (const BasicMdspan &basicMdspan) | ||
| Free end function addressing memory of a contiguously laid out basic_mdspan. More... | |||
| template<class BasicMdspan > | |||
| constexpr BasicMdspan | addElementwise (const BasicMdspan &span1, const BasicMdspan &span2) | ||
| Elementwise addition. | |||
| template<class BasicMdspan > | |||
| constexpr BasicMdspan | subtractElementwise (const BasicMdspan &span1, const BasicMdspan &span2) | ||
| Elementwise subtraction - left minus right. | |||
| template<class BasicMdspan > | |||
| constexpr BasicMdspan | multiplyElementwise (const BasicMdspan &span1, const BasicMdspan &span2) | ||
| Elementwise multiplication. | |||
| template<class BasicMdspan > | |||
| constexpr BasicMdspan | divideElementwise (const BasicMdspan &span1, const BasicMdspan &span2) | ||
| Elementwise division - left / right. | |||
| template<std::ptrdiff_t... LHS, std::ptrdiff_t... RHS> | |||
| constexpr bool | operator== (const extents< LHS...> &lhs, const extents< RHS...> &rhs) noexcept | ||
| Comparison operator. More... | |||
| template<std::ptrdiff_t... LHS, std::ptrdiff_t... RHS> | |||
| constexpr bool | operator!= (const extents< LHS...> &lhs, const extents< RHS...> &rhs) noexcept | ||
| Check for non-equality. More... | |||
| template<CheckpointDataOperation operation, typename T > | |||
| ArrayRef< std::conditional_t < operation==CheckpointDataOperation::Write||std::is_const_v < T >, const typename T::value_type, typename T::value_type > > | makeCheckpointArrayRef (T &container) | ||
| template<CheckpointDataOperation operation, typename T > | |||
| ArrayRef< std::conditional_t < operation==CheckpointDataOperation::Write||std::is_const_v < T >, const typename T::value_type, typename T::value_type > > | makeCheckpointArrayRef (T &&container) | ||
| template<CheckpointDataOperation operation, typename T > | |||
| ArrayRef< std::conditional_t < operation==CheckpointDataOperation::Write||std::is_const_v < T >, const T, T > > | makeCheckpointArrayRefFromArray (T *begin, size_t size) | ||
| template<typename VersionEnum > | |||
| VersionEnum | checkpointVersion (const ReadCheckpointData *checkpointData, const std::string &key, const VersionEnum programVersion) | ||
| Read a checkpoint version enum variable. More... | |||
| template<typename VersionEnum > | |||
| VersionEnum | checkpointVersion (WriteCheckpointData *checkpointData, const std::string &key, const VersionEnum programVersion) | ||
| Write the current code checkpoint version enum variable. More... | |||
| forceMtsCombined_ ({}) | |||
| view_ ({},{}, false) | |||
| useForceMtsCombined_ (false) | |||
| template<class T > | |||
| T & | makeRefFromPointer (T *ptr) | ||
| Take pointer, check if valid, return reference. | |||
| template<class ToType , class TransformWithFunctionType > | |||
| void | addMdpTransformFromString (IKeyValueTreeTransformRules *rules, TransformWithFunctionType transformationFunction, std::string_view moduleName, std::string_view optionName) | ||
| Helper to declare mdp transform rules. More... | |||
| template<class ValueType > | |||
| void | addMdpOutputValue (KeyValueTreeObjectBuilder *builder, std::string_view moduleName, std::string_view optionName, const ValueType &optionValue) | ||
| Add an mdp value to output KVT with a module-prefixed name. More... | |||
| void | addMdpOutputComment (KeyValueTreeObjectBuilder *builder, std::string_view moduleName, std::string_view optionName, const std::string &comment) | ||
| Add a comment for an mdp value with a module-prefixed name. More... | |||
| static const char * | enumValueToString (AtomLocality enumValue) | ||
| Get the human-friendly name for atom localities. More... | |||
| static const char * | enumValueToString (InteractionLocality enumValue) | ||
| Get the human-friendly name for interaction localities. More... | |||
| static InteractionLocality | atomToInteractionLocality (const AtomLocality atomLocality) | ||
| Convert atom locality to interaction locality. More... | |||
| int | nonbondedMtsFactor (const t_inputrec &ir) | ||
| Returns the interval in steps at which the non-bonded pair forces are calculated. More... | |||
| std::vector< MtsLevel > | setupMtsLevels (const GromppMtsOpts &mtsOpts, std::vector< std::string > *errorMessages) | ||
| Sets up and returns the MTS levels and checks requirements of MTS. More... | |||
| bool | haveValidMtsSetup (const t_inputrec &ir) | ||
| Returns whether we use MTS and the MTS setup is internally valid. More... | |||
| std::vector< std::string > | checkMtsRequirements (const t_inputrec &ir) | ||
| Checks whether the MTS requirements on other algorithms and output frequencies are met. More... | |||
| static int | forceGroupMtsLevel (ArrayRef< const MtsLevel > mtsLevels, const MtsForceGroups mtsForceGroup) | ||
| Returns the MTS level at which a force group is to be computed. More... | |||
| bool | needStateGpu (SimulationWorkload simulationWorkload) | ||
| If StatePropagatorDataGpu object is needed. More... | |||
| conservedEnergyContribution_ (0) | |||
| previousStepConservedEnergyContribution_ (0) | |||
| conservedEnergyContributionStep_ (-1) | |||
| reportPreviousStepConservedEnergy_ (reportPreviousStepConservedEnergy) | |||
| statePropagatorData_ (statePropagatorData) | |||
| energyData_ (energyData) | |||
| fplog_ (fplog) | |||
| inputrec_ (inputrec) | |||
| mdAtoms_ (mdAtoms) | |||
| nrnb_ (nrnb) | |||
| identifier_ ("FirstOrderPressureCoupling-"+std::string(enumValueToString(pressureCouplingType_))) | |||
| numDegreesOfFreedom_ (numDegreesOfFreedom) | |||
| simulationTimeStep_ (simulationTimeStep) | |||
| ensembleTemperature_ (ensembleTemperature) | |||
| mttkPropagatorConnection_ (mttkPropagatorConnection) | |||
| nextEnergyCalculationStep_ (-1) | |||
| mdlog_ (mdlog) | |||
| template<NumVelocityScalingValues numStartVelocityScalingValues, ParrinelloRahmanVelocityScaling parrinelloRahmanVelocityScaling, NumVelocityScalingValues numEndVelocityScalingValues> | |||
| static void | updateVelocities (int a, real dt, real lambdaStart, real lambdaEnd, const RVec *gmx_restrict invMassPerDim, RVec *gmx_restrict v, const RVec *gmx_restrict f, const RVec &diagPR, const Matrix3x3 &matrixPR) | ||
| Update velocities. More... | |||
| static void | updatePositions (int a, real dt, const RVec *gmx_restrict x, RVec *gmx_restrict xprime, const RVec *gmx_restrict v) | ||
| Update positions. More... | |||
| template<NumVelocityScalingValues numStartVelocityScalingValues> | |||
| static void | scaleVelocities (int a, real lambda, RVec *gmx_restrict v) | ||
| Scale velocities. More... | |||
| template<NumPositionScalingValues numPositionScalingValues> | |||
| static void | scalePositions (int a, real lambda, RVec *gmx_restrict x) | ||
| Scale positions. More... | |||
| template<ParrinelloRahmanVelocityScaling parrinelloRahmanVelocityScaling> | |||
| static bool | canTreatPRScalingMatrixAsDiagonal (const Matrix3x3 &matrixPR) | ||
| Is the PR matrix diagonal? | |||
| template<IntegrationStage integrationStage> | |||
| constexpr bool | hasStartVelocityScaling () | ||
| template<IntegrationStage integrationStage> | |||
| constexpr bool | hasEndVelocityScaling () | ||
| template<IntegrationStage integrationStage> | |||
| constexpr bool | hasPositionScaling () | ||
| template<IntegrationStage integrationStage> | |||
| constexpr bool | hasParrinelloRahmanScaling () | ||
| template<IntegrationStage integrationStage> | |||
| static PropagatorConnection | getConnection (Propagator< integrationStage > *propagator, const PropagatorTag &propagatorTag) | ||
| template<CheckpointDataOperation operation> | |||
| static void | doCheckpointData (CheckpointData< operation > *checkpointData, ArrayRef< double > previousStepCom) | ||
| static void | runAllCallbacks (const std::vector< SignallerCallback > &callbacks, Step step, Time time) | ||
| Helper function to call all callbacks in a list. | |||
| template<typename Element , typename... Args> | |||
| ISimulatorElement * | getElementPointer (LegacySimulatorData *legacySimulatorData, ModularSimulatorAlgorithmBuilderHelper *builderHelper, StatePropagatorData *statePropagatorData, EnergyData *energyData, FreeEnergyPerturbationData *freeEnergyPerturbationData, GlobalCommunicationHelper *globalCommunicationHelper, ObservablesReducer *observablesReducer, Args &&...args) | ||
| template<typename Base , typename Element > | |||
| static std::enable_if_t < std::is_base_of_v< Base, Element >, Base * > | castOrNull (Element *element) | ||
| Returns a pointer casted to type Base if the Element is derived from Base. | |||
| template<typename Base , typename Element > | |||
| static std::enable_if_t <!std::is_base_of_v< Base, Element >, Base * > | castOrNull (Element gmx_unused *element) | ||
| Returns a nullptr of type Base if Element is not derived from Base. | |||
| ddpCount_ (0) | |||
| element_ (std::make_unique< Element >(this, fplog, cr, inputrec->nstxout, inputrec->nstvout, inputrec->nstfout, inputrec->nstxout_compressed, canMoleculesBeDistributedOverPBC, writeFinalConfiguration, finalConfigurationFilename, inputrec, globalTop)) | |||
| referenceTemperatureHelper_ (std::make_unique< ReferenceTemperatureHelper >(inputrec, this, mdatoms)) | |||
| vvResetVelocities_ (false) | |||
| isRegularSimulationEnd_ (false) | |||
| lastStep_ (-1) | |||
| globalState_ (globalState) | |||
| static void | updateGlobalState (t_state *globalState, const PaddedHostVector< RVec > &x, const PaddedHostVector< RVec > &v, const tensor box, int ddpCount, int ddpCountCgGl, const std::vector< int > &cgGl) | ||
| Update the legacy global state. More... | |||
| bool | timesClose (Time time, Time referenceTime) | ||
| Check whether two times are nearly equal. More... | |||
| const char * | enumValueToString (LJCombinationRule enumValue) | ||
| String corresponding to LJ combination rule. | |||
| static void | copy_int_to_nbat_int (const int *a, int na, int na_round, const int *in, int fill, int *innb) | ||
| void | copy_rvec_to_nbat_real (const int *a, int na, int na_round, const rvec *x, int nbatFormat, real *xnb, int a0) | ||
| Copy na rvec elements from x to xnb using nbatFormat, start dest a0, and fills up to na_round with coordinates that are far away. | |||
| template<int coordinateStride> | |||
| static void | copyRVecToNbatXYZReal (int numAtoms, const rvec *x, real *xnb, int a0) | ||
| template<int packSize> | |||
| static void | copyRVecToNbatPackedReal (int numAtoms, const rvec *x, real *xnb, int a0) | ||
| Copies coordinates with RVec layout to SIMD layout with X/Y/Z packs. More... | |||
| static void | set_lj_parameter_data (nbnxn_atomdata_t::Params *params, gmx_bool bSIMD) | ||
| template<typename T > | |||
| static gmx_unused void | setExclusionFilters (AlignedVector< T > *exclusionFilters, const NbnxmKernelType kernelType) | ||
| Allocates and sets the SIMD exclusion filters. | |||
| template<int packSize> | |||
| static void | copy_lj_to_nbat_lj_comb (ArrayRef< const real > ljparam_type, const int *type, int na, real *ljparam_at) | ||
| static void | nbnxn_atomdata_set_atomtypes (nbnxn_atomdata_t::Params *params, const GridSet &gridSet, ArrayRef< const int > atomTypesA, ArrayRef< const int > atomTypesB, const bool useGpuNonbondedFE) | ||
| static void | nbnxn_atomdata_set_ljcombparams (nbnxn_atomdata_t::Params *params, const int XFormat, const GridSet &gridSet, const bool useGpuNonbondedFE) | ||
| static void | nbnxn_atomdata_set_charges (nbnxn_atomdata_t *nbat, const GridSet &gridSet, ArrayRef< const real > chargesA, ArrayRef< const real > chargesB, const bool useGpuNonbondedFE) | ||
| static void | nbnxn_atomdata_mask_fep (nbnxn_atomdata_t *nbat, const GridSet &gridSet) | ||
| static void | nbnxn_atomdata_set_energygroups (const GridSet &gridSet, ArrayRef< const int32_t > atomInfo, EnergyGroupsPerCluster *energyGroupsPerCluster) | ||
| void | nbnxn_atomdata_set (nbnxn_atomdata_t gmx_unused *nbat, const GridSet gmx_unused &gridSet, ArrayRef< const int > gmx_unused atomTypesA, ArrayRef< const int > gmx_unused atomTypesB, ArrayRef< const real > gmx_unused atomChargesA, ArrayRef< const real > gmx_unused atomChargesB, ArrayRef< const int32_t > gmx_unused atomInfo, bool gmx_unused useGpuNonbondedFE) | ||
| Sets the atomdata after pair search. | |||
| void | nbnxn_atomdata_copy_shiftvec (std::optional< bool > haveDynamicBox, ArrayRef< const RVec > shiftVectors, nbnxn_atomdata_t *nbat) | ||
| Copy the shift vectors to nbat. | |||
| static Range< int > | getGridRange (const GridSet &gridSet, const AtomLocality locality) | ||
| static void | copyXToNbatXForGridPart (const Grid &grid, const Range< int > &columnRange, const rvec *coordinates, nbnxn_atomdata_t *nbat) | ||
| static void | copyXToNbatXForGridPartIndexed (const Grid &grid, const Range< int > &columnRange, ArrayRef< const int > atomIndices, const rvec *coordinates, nbnxn_atomdata_t *nbat) | ||
| void | nbnxn_atomdata_copy_x_to_nbat_x (const GridSet &gridSet, AtomLocality locality, const rvec *coordinates, nbnxn_atomdata_t *nbat) | ||
| Transform coordinates to xbat layout. More... | |||
| void | nbnxn_atomdata_x_to_nbat_x_gpu (const GridSet &gridSet, AtomLocality locality, NbnxmGpu *gpu_nbv, DeviceBuffer< RVec > d_x, GpuEventSynchronizer *xReadyOnDevice) | ||
| Transform coordinates to xbat layout on GPU. More... | |||
| static void | nbnxn_atomdata_clear_reals (ArrayRef< real > dest, int i0, int i1) | ||
| static gmx_unused void | nbnxn_atomdata_reduce_reals (real *gmx_restrict dest, gmx_bool bDestSet, const real **gmx_restrict src, int nsrc, int i0, int i1) | ||
| static gmx_unused void | nbnxn_atomdata_reduce_reals_simd (real gmx_unused *gmx_restrict dest, gmx_bool gmx_unused bDestSet, const gmx_unused real **gmx_restrict src, int gmx_unused nsrc, int gmx_unused i0, int gmx_unused i1) | ||
| template<int forceStride> | |||
| static void | addNbatFXYZToFPart (const nbnxn_atomdata_output_t &out, const int a0, const int a1, const int *cellIndices, ArrayRef< RVec > forces) | ||
| template<int packSize> | |||
| static void | addNbatFPackedToFPart (const nbnxn_atomdata_output_t &out, const int a0, const int a1, const int *cellIndices, ArrayRef< RVec > forces) | ||
| Adds forces in SIMD packed layout to an RVec array. More... | |||
| static Range< int > | getAtomRange (const AtomLocality locality, const GridSet &gridSet) | ||
| void | nbnxn_atomdata_add_nbat_fshift_to_fshift (const nbnxn_atomdata_t &nbat, ArrayRef< RVec > fshift) | ||
| Add the fshift force stored in nbat to fshift. | |||
| static void | clearBufferAll (ArrayRef< real > buffer) | ||
| Clears all elements of buffer. | |||
| template<int numComponentsPerElement> | |||
| static void | clearBufferFlagged (const int outputIndex, ArrayRef< const gmx_bitmask_t > flags, ArrayRef< real > buffer) | ||
Clears elements of size and stride numComponentsPerElement. More... | |||
| template<int packSize> | |||
| static int | atom_to_x_index (int a) | ||
| Returns the index in a coordinate array corresponding to atom a. | |||
| static RVec | getCoordinate (const nbnxn_atomdata_t &nbat, const int a) | ||
Returns the coordinates of atoms a. | |||
| static std::optional< std::string > | checkKernelSetup (const NbnxmKernelBenchOptions &options) | ||
| Checks the kernel setup. More... | |||
| static NbnxmKernelType | translateBenchmarkEnum (const NbnxmBenchMarkKernels &kernel) | ||
| Helper to translate between the different enumeration values. | |||
| static NbnxmKernelSetup | getKernelSetup (const NbnxmKernelBenchOptions &options) | ||
| Returns the kernel setup. | |||
| static InteractionModifiers | convertInteractionModifiers (const NbnxmBenchMarkInteractionModifiers interactionModifier) | ||
| Converts the benchmark interaction modifier enum to the corresponding NBNxM enum. | |||
| static interaction_const_t | setupInteractionConst (const NbnxmKernelBenchOptions &options) | ||
| Return an interaction constants struct with members used in the benchmark set appropriately. | |||
| static LJCombinationRule | convertLJCombinationRule (const NbnxmBenchMarkCombRule combRule) | ||
| Converts the benchmark LJ comb.rule. enum to the corresponding NBNxM enum. | |||
|
static std::unique_ptr < nonbonded_verlet_t > | setupNbnxmForBenchInstance (const NbnxmKernelBenchOptions &options, const BenchmarkSystem &system) | ||
| Sets up and returns a Nbnxm object for the given benchmark options and system. | |||
| static void | expandSimdOptionAndPushBack (const NbnxmKernelBenchOptions &options, std::vector< NbnxmKernelBenchOptions > *optionsList) | ||
| Add the options instance to the list for all requested kernel SIMD types. | |||
| static void | setupAndRunInstance (const BenchmarkSystem &system, const NbnxmKernelBenchOptions &options, const bool doWarmup) | ||
| Sets up and runs the requested benchmark instance and prints the results. | |||
| void | bench (int sizeFactor, const NbnxmKernelBenchOptions &options) | ||
| Sets up and runs one or more Nbnxm kernel benchmarks. More... | |||
| static void | generateCoordinates (int multiplicationFactor, std::vector< gmx::RVec > *coordinates, matrix box) | ||
Generates coordinates and a box for the base system scaled by multiplicationFactor. | |||
| template<typename T > | |||
| static std::enable_if_t < std::is_same_v< T, gmx::BasicVector< float > >, gmx::BasicVector< float > > | loadBoundingBoxCorner (const BoundingBox::Corner &corner) | ||
| Loads a corner of a bounding box into a float vector. | |||
| static gmx::BasicVector< float > | max (const gmx::BasicVector< float > &v1, const gmx::BasicVector< float > &v2) | ||
| Return the element-wise max of two 3-float vectors, needed to share code with SIMD. | |||
| static float | dotProduct (const gmx::BasicVector< float > &v1, const gmx::BasicVector< float > &v2) | ||
| Return the dot product of two 3-float vectors, needed to share code with SIMD. | |||
| static float | clusterBoundingBoxDistance2 (const BoundingBox &bb_i, const BoundingBox &bb_j) | ||
| Returns the distance^2 between two bounding boxes. More... | |||
| static gmx_unused void | clusterBoundingBoxDistance2_xxxx_simd4 (const float *, const int, const float *, float *) | ||
| 4-wide SIMD code for nsi bb distances for bb format xxxxyyyyzzzz | |||
| static ClusterDistanceKernelType | getClusterDistanceKernelType (const PairlistType pairlistType, const nbnxn_atomdata_t &atomdata) | ||
| Return the cluster distance kernel type given the pairlist type and atomdata. | |||
| void | cuda_set_cacheconfig () | ||
| Set up the cache configuration for the non-bonded kernels. | |||
| template<bool computeScalarForce, class RealType > | |||
| static void | pmeCoulombCorrectionVF (const RealType rSq, const real beta, RealType *pot, RealType gmx_unused *force) | ||
| template<bool computeScalarForce, class RealType , class BoolType > | |||
| static void | pmeLJCorrectionVF (const RealType rInv, const RealType rSq, const real ewaldLJCoeffSq, const real ewaldLJCoeffSixDivSix, RealType *pot, RealType gmx_unused *force, const BoolType mask, const BoolType bIiEqJnr) | ||
| template<class RealType > | |||
| static void | sixthRoot (const RealType r, RealType *sixthRoot, RealType *invSixthRoot) | ||
| Computes r^(1/6) and 1/r^(1/6) | |||
| template<class RealType > | |||
| static RealType | calculateRinv6 (const RealType rInvV) | ||
| template<class RealType > | |||
| static RealType | calculateVdw6 (const RealType c6, const RealType rInv6) | ||
| template<class RealType > | |||
| static RealType | calculateVdw12 (const RealType c12, const RealType rInv6) | ||
| template<class RealType > | |||
| static RealType | reactionFieldScalarForce (const RealType qq, const RealType rInv, const RealType r, const real reactionFieldCoefficient, const real two) | ||
| template<class RealType > | |||
| static RealType | reactionFieldPotential (const RealType qq, const RealType rInv, const RealType r, const real reactionFieldCoefficient, const real potentialShift) | ||
| template<class RealType > | |||
| static RealType | ewaldScalarForce (const RealType coulomb, const RealType rInv) | ||
| template<class RealType > | |||
| static RealType | ewaldPotential (const RealType coulomb, const RealType rInv, const real potentialShift) | ||
| template<class RealType > | |||
| static RealType | lennardJonesScalarForce (const RealType v6, const RealType v12) | ||
| template<class RealType > | |||
| static RealType | lennardJonesPotential (const RealType v6, const RealType v12, const RealType c6, const RealType c12, const real repulsionShift, const real dispersionShift, const real oneSixth, const real oneTwelfth) | ||
| template<class RealType > | |||
| static RealType | ewaldLennardJonesGridSubtract (const RealType c6grid, const real potentialShift, const real oneSixth) | ||
| template<class RealType > | |||
| static void | computeForceSwitchVariables (const RealType r, const real rSwitch, RealType *rSwitched, RealType *rSwitchedSquared, RealType *rSwitchedSquaredTimesR) | ||
| Generates intermediate quantities for force switch interactions. | |||
| template<class RealType , class BoolType > | |||
| static RealType | forceSwitchScalarForceMod (const RealType fScalarInp, const RealType rSwitched, const RealType rSwitchedSquaredTimesR, const real c2, const real c3, const BoolType mask) | ||
| Return the force for force-switch interactions. | |||
| template<class RealType , class BoolType > | |||
| static RealType | forceSwitchPotentialMod (const RealType rSwitched, const RealType rSwitchedSquaredTimesR, const real c3, const real c4, const BoolType mask) | ||
| Return the modification of the potential for force-switch interactions. | |||
| template<class RealType , class BoolType > | |||
| static RealType | potSwitchScalarForceMod (const RealType fScalarInp, const RealType potential, const RealType sw, const RealType r, const RealType dsw, const BoolType mask) | ||
| template<class RealType , class BoolType > | |||
| static RealType | potSwitchPotentialMod (const RealType potentialInp, const RealType sw, const BoolType mask) | ||
| template<typename DataTypes , KernelSoftcoreType softcoreType, bool scLambdasOrAlphasDiffer, bool elecInteractionTypeIsEwald, LJKernelType ljKernelType, bool computeForces> | |||
| static void | nb_free_energy_kernel (const AtomPairlist &nlist, const ArrayRefWithPadding< const RVec > &coords, const int ntype, const interaction_const_t &ic, ArrayRef< const RVec > shiftvec, ArrayRef< const real > nbfp, ArrayRef< const real > gmx_unused nbfp_grid, ArrayRef< const real > chargeA, ArrayRef< const real > chargeB, ArrayRef< const int > typeA, ArrayRef< const int > typeB, const bool computeForeignLambda, const StepWorkload *stepWork, ArrayRef< const real > lambda, t_nrnb *gmx_restrict nrnb, ArrayRefWithPadding< RVec > threadForceBuffer, rvec gmx_unused *threadForceShiftBuffer, ArrayRef< real > threadVCoul, ArrayRef< real > threadVVdw, ArrayRef< real > threadDvdl) | ||
| Templated free-energy non-bonded kernel. | |||
| template<KernelSoftcoreType softcoreType, bool scLambdasOrAlphasDiffer, bool elecInteractionTypeIsEwald, LJKernelType ljKernelType, bool computeForces> | |||
| static KernelFunction | dispatchKernelOnUseSimd (const bool useSimd) | ||
| template<KernelSoftcoreType softcoreType, bool scLambdasOrAlphasDiffer, bool elecInteractionTypeIsEwald, LJKernelType ljKernelType> | |||
| static KernelFunction | dispatchKernelOnComputeForces (const bool computeForces, const bool useSimd) | ||
| template<KernelSoftcoreType softcoreType, bool scLambdasOrAlphasDiffer, bool elecInteractionTypeIsEwald> | |||
| static KernelFunction | dispatchKernelOnLJType (const LJKernelType ljKernelType, const bool computeForces, const bool useSimd) | ||
| template<KernelSoftcoreType softcoreType, bool scLambdasOrAlphasDiffer> | |||
| static KernelFunction | dispatchKernelOnElecInteractionType (const bool elecInteractionTypeIsEwald, const LJKernelType ljKernelType, const bool computeForces, const bool useSimd) | ||
| template<KernelSoftcoreType softcoreType> | |||
| static KernelFunction | dispatchKernelOnScLambdasOrAlphasDifference (const bool scLambdasOrAlphasDiffer, const bool elecInteractionTypeIsEwald, const LJKernelType ljKernelType, const bool computeForces, const bool useSimd) | ||
| static KernelFunction | dispatchKernel (const bool scLambdasOrAlphasDiffer, const bool elecInteractionTypeIsEwald, const LJKernelType ljKernelType, const bool computeForces, const bool useSimd, const interaction_const_t &interactionParameters) | ||
| void | gmx_nb_free_energy_kernel (const AtomPairlist &nlist, const ArrayRefWithPadding< const RVec > &coords, const bool useSimd, const int ntype, const interaction_const_t &interactionParameters, ArrayRef< const RVec > shiftvec, ArrayRef< const real > nbfp, ArrayRef< const real > nbfp_grid, ArrayRef< const real > chargeA, ArrayRef< const real > chargeB, ArrayRef< const int > typeA, ArrayRef< const int > typeB, const bool computeForeignLambda, const StepWorkload *stepWork, ArrayRef< const real > lambda, t_nrnb *nrnb, ArrayRefWithPadding< RVec > threadForceBuffer, rvec *threadForceShiftBuffer, ArrayRef< real > threadVCoul, ArrayRef< real > threadVVdw, ArrayRef< real > threadDvdl) | ||
| void | gmx_nb_free_energy_kernel (const AtomPairlist &nlist, const ArrayRefWithPadding< const RVec > &coords, bool useSimd, int ntype, const interaction_const_t &ic, ArrayRef< const RVec > shiftvec, ArrayRef< const real > nbfp, ArrayRef< const real > nbfp_grid, ArrayRef< const real > chargeA, ArrayRef< const real > chargeB, ArrayRef< const int > typeA, ArrayRef< const int > typeB, bool computeForeignLambda, const StepWorkload *stepWork, ArrayRef< const real > lambda, t_nrnb *gmx_restrict nrnb, ArrayRefWithPadding< RVec > threadForceBuffer, rvec *threadForceShiftBuffer, ArrayRef< real > threadVc, ArrayRef< real > threadVv, ArrayRef< real > threadDvdl) | ||
| The non-bonded free-energy kernel. More... | |||
| static void | countPruneKernelTime (GpuTimers *timers, gmx_wallclock_gpu_nbnxn_t *timings, const InteractionLocality iloc) | ||
| Count pruning kernel time if either kernel has been triggered. More... | |||
| static void | gpu_reduce_staged_outputs (const NBStagingData &nbst, const InteractionLocality iLocality, const bool reduceEnergies, const bool reduceFshift, real *e_lj, real *e_el, double *dvdl_lj, double *dvdl_el, rvec *fshift) | ||
| Reduce data staged internally in the nbnxn module. More... | |||
| static void | gpu_reduce_staged_foreign_term (const NBStagingData &nbst, const InteractionLocality iLocality, const int nLambda, ForeignLambdaTerms *foreign_term) | ||
| Reduce free energy lambda data staged internally in the nbnxm module. More... | |||
| template<typename GpuPairlist > | |||
| static void | gpu_accumulate_timings (gmx_wallclock_gpu_nbnxn_t *timings, GpuTimers *timers, const GpuPairlist *plist, AtomLocality atomLocality, const StepWorkload &stepWork, bool doTiming) | ||
| Do the per-step timing accounting of the nonbonded tasks. More... | |||
| bool | gpu_try_finish_task (NbnxmGpu *nb, const StepWorkload &stepWork, const AtomLocality aloc, real *e_lj, real *e_el, double *dvdl_lj, double *dvdl_el, ArrayRef< RVec > shiftForces, ForeignLambdaTerms *foreign_term, GpuTaskCompletion completionKind) | ||
| Attempts to complete nonbonded GPU task. More... | |||
| float | gpu_wait_finish_task (NbnxmGpu *nb, const StepWorkload &stepWork, AtomLocality aloc, const bool haveSoftCore, gmx_enerdata_t *enerd, ArrayRef< RVec > shiftForces, gmx_wallcycle *wcycle) | ||
| Wait for the asynchronously launched nonbonded tasks and data transfers to finish. More... | |||
| static bool | canSkipNonbondedWork (const NbnxmGpu &nb, InteractionLocality iloc) | ||
| An early return condition for empty NB GPU workloads. More... | |||
| static Range< int > | getGpuAtomRange (const NBAtomDataGpu *atomData, const AtomLocality atomLocality) | ||
| Calculate atom range and return start index and length. More... | |||
| void | copy_gpu_fepparams (NbnxmGpu gmx_unused *nb, bool gmx_unused bFepGpuNonBonded, float gmx_unused alphaCoul, float gmx_unused alphaVdw, int gmx_unused lambdaPower, float gmx_unused sigma6WithInvalidSigma, float gmx_unused sigma6Minimum, float gmx_unused lambdaCoul, float gmx_unused lambdaVdw, int gmx_unused nLambda, const EnumerationArray< FreeEnergyPerturbationCouplingType, std::vector< double >> gmx_unused &all_lambda) | ||
| Copy FEP parameters to GPU. More... | |||
| NbnxmGpu * | gpu_init (const DeviceStreamManager gmx_unused &deviceStreamManager, const interaction_const_t gmx_unused *ic, const PairlistParams gmx_unused &listParams, const nbnxn_atomdata_t gmx_unused *nbat, bool gmx_unused bLocalAndNonlocal, const std::optional< int > gmx_unused nLambda) | ||
| Initializes the data structures related to GPU nonbonded calculations. More... | |||
| void | gpu_init_pairlist (NbnxmGpu gmx_unused *nb, const struct NbnxnPairlistGpu gmx_unused *h_nblist, InteractionLocality gmx_unused iloc) | ||
| Initializes pair-list data for GPU, called at every pair search step. More... | |||
| void | gpu_init_feppairlist (NbnxmGpu gmx_unused *nb, const AtomPairlist gmx_unused &h_feplist, InteractionLocality gmx_unused iloc, const GridSet gmx_unused &gridSet) | ||
| Initializes fep pair-list data for GPU, called at every pair search step. More... | |||
| void | gpu_init_atomdata (NbnxmGpu gmx_unused *nb, const nbnxn_atomdata_t gmx_unused *nbat) | ||
| Initializes atom-data on the GPU, called at every pair search step. More... | |||
| void | gpu_pme_loadbal_update_param (struct nonbonded_verlet_t gmx_unused *nbv, const interaction_const_t gmx_unused &ic) | ||
| Re-generate the GPU Ewald force table, resets rlist, and update the electrostatic type switching to twin cut-off (or back) if needed. | |||
| void | gpu_upload_shiftvec (NbnxmGpu gmx_unused *nb, const nbnxn_atomdata_t gmx_unused *nbatom) | ||
| Uploads shift vector to the GPU if the box is dynamic (otherwise just returns). More... | |||
| void | gpu_clear_outputs (NbnxmGpu gmx_unused *nb, bool gmx_unused computeVirial) | ||
| Clears GPU outputs: nonbonded force, shift force and energy. More... | |||
| void | gpu_free (NbnxmGpu gmx_unused *nb) | ||
| Frees all GPU resources used for the nonbonded calculations. More... | |||
| struct gmx_wallclock_gpu_nbnxn_t * | gpu_get_timings (NbnxmGpu gmx_unused *nb) | ||
| Returns the GPU timings structure or NULL if GPU is not used or timing is off. More... | |||
| void | gpu_reset_timings (struct nonbonded_verlet_t gmx_unused *nbv) | ||
| Resets nonbonded GPU timings. More... | |||
| int | gpu_min_ci_balanced (NbnxmGpu gmx_unused *nb) | ||
| Calculates the minimum size of proximity lists to improve SM load balance with GPU non-bonded kernels. More... | |||
| bool | gpu_is_kernel_ewald_analytical (const NbnxmGpu gmx_unused *nb) | ||
| Returns if analytical Ewald GPU kernels are used. More... | |||
| NBAtomDataGpu * | gpuGetNBAtomData (NbnxmGpu gmx_unused *nb) | ||
| Returns an opaque pointer to the GPU NBNXM atom data. | |||
| DeviceBuffer< RVec > | gpu_get_f (NbnxmGpu gmx_unused *nb) | ||
| Returns forces device buffer. | |||
| size_t | getExclusiveScanWorkingArraySize (GpuPairlist *plist, const DeviceStream &deviceStream) | ||
| Calculates working memory required for exclusive sum, used in neighbour list sorting on GPU. More... | |||
| void | performExclusiveScan (size_t temporaryBufferSize, char *temporaryBuffer, GpuPairlist *plist, const DeviceStream &deviceStream) | ||
| Perform exclusive scan to obtain input for sci sorting. | |||
| void | nbnxn_gpu_compile_kernels (NbnxmGpu gmx_unused *nb) | ||
| Handles any JIT compilation of nbnxn kernels for the selected device. | |||
| static real | gridAtomDensity (int numAtoms, const RVec &gridBoundingBoxSize) | ||
| Returns the atom density (> 0) of a rectangular grid. | |||
| static std::array< real, DIM-1 > | getTargetCellLength (const Grid::Geometry &geometry, const real atomDensity) | ||
| Get approximate dimensions of each cell. Returns the length along X and Y. | |||
| static int | getMaxNumCells (const Grid::Geometry &geometry, const int numAtoms, const int numColumns) | ||
| static bool | isHomeZone (const int ddZone) | ||
Returns whether ddZone is the home zone. | |||
| static void | sort_atoms (int dim, gmx_bool Backwards, int gmx_unused dd_zone, bool gmx_unused relevantAtomsAreWithinGridBounds, int *a, int n, ArrayRef< const RVec > x, real h0, real invh, int n_per_h, ArrayRef< int > sort) | ||
| Sorts particle index a on coordinates x along dim. More... | |||
| static float | R2F_D (const float x) | ||
| Returns x. | |||
| static float | R2F_U (const float x) | ||
| Returns x. | |||
| static void | calc_bounding_box (const int numAtoms, const int stride, const real *x, BoundingBox *bb) | ||
| Computes the bounding box for na coordinates in order x,y,z, bb order xyz0. | |||
| template<int packSize> | |||
| static void | calcBoundingBoxXPacked (const int numAtoms, const real *x, BoundingBox *bb) | ||
| Computes the bounding box for packed coordinates. More... | |||
| template<int packSize> | |||
| static gmx_unused void | calcBoundingBoxHalves (const int numAtoms, const real *x, BoundingBox *bb, BoundingBox *bbj) | ||
| Computes the whole plus half bounding boxes for packed coordinates. More... | |||
| static void | calc_bounding_box_xxxx (int na, int stride, const real *x, float *bb) | ||
| Computes the bounding box for na coordinates in order xyz, bb order xxxxyyyyzzzz. | |||
| static void | combine_bounding_box_pairs (const Grid &grid, ArrayRef< const BoundingBox > bb, ArrayRef< BoundingBox > bbj) | ||
| Combines pairs of consecutive bounding boxes. | |||
| static void | print_bbsizes_simple (FILE *fp, const Grid &grid) | ||
| Prints the average bb size, used for debug output. | |||
| static void | print_bbsizes_supersub (FILE *fp, const Grid &grid) | ||
| Prints the average bb size, used for debug output. | |||
| static void | sort_cluster_on_flag (int numAtomsInCluster, int atomStart, int atomEnd, ArrayRef< const int32_t > atomInfo, ArrayRef< int > order, int *flags) | ||
| Set non-bonded interaction flags for the current cluster. More... | |||
| static void | setCellAndAtomCount (ArrayRef< int > cell, int cellIndex, ArrayRef< int > cxy_na, int atomIndex) | ||
Sets the cell index in the cell array for atom atomIndex and increments the atom count for the grid column. | |||
| static void | resizeForNumberOfCells (const int numNbnxnAtoms, const int numAtomsMoved, const int ddZone, GridSetData *gridSetData, nbnxn_atomdata_t *nbat) | ||
| Resizes grid and atom data which depend on the number of cells. | |||
| real | generateAndFill2DGrid (Grid *grid, ArrayRef< GridWork > gridWork, HostVector< int > *cells, const rvec lowerCorner, const rvec upperCorner, const UpdateGroupsCog *updateGroupsCog, Range< int > atomRange, int numGridAtomsWithoutFillers, real *atomDensity, real maxAtomGroupRadius, ArrayRef< const RVec > x, int ddZone, const int *move, bool computeGridDensityRatio) | ||
| Sets the 2D search grid dimensions puts the atoms on the 2D grid. More... | |||
| static int | numGrids (const GridSet::DomainSetup &domainSetup) | ||
| Returns the number of search grids. | |||
| static int | getGridOffset (ArrayRef< const Grid > grids, int gridIndex) | ||
| void | launchNbnxmKernelTransformXToXq (const Grid &grid, NbnxmGpu *nb, DeviceBuffer< Float3 > d_x, const DeviceStream &deviceStream, unsigned int numColumnsMax, int gridId) | ||
| Launch coordinate layout conversion kernel. More... | |||
| void | gpu_launch_kernel_pruneonly (NbnxmGpu *nb, const InteractionLocality iloc, const int numParts) | ||
Launch the pairlist prune only kernel for the given locality. numParts tells in how many parts, i.e. calls the list will be pruned. | |||
| void | gpu_launch_kernel (NbnxmGpu *nb, const gmx::StepWorkload &stepWork, const InteractionLocality iloc) | ||
| Launch GPU kernel. More... | |||
| void | gpu_launch_free_energy_kernel (NbnxmGpu gmx_unused *nb, const SimulationWorkload gmx_unused &simulationWork, const StepWorkload gmx_unused &stepWork, InteractionLocality gmx_unused iloc) | ||
| Launch asynchronously the nonbonded free energy calculations. More... | |||
| void | gpu_init_platform_specific (NbnxmGpu *nb) | ||
| Initializes the NBNXM GPU data structures. | |||
| void | gpu_free_platform_specific (NbnxmGpu *nb) | ||
| Releases the NBNXM GPU data structures. More... | |||
| int | gpu_min_ci_balanced (NbnxmGpu *nb) | ||
| This function is documented in the header file. | |||
| template<bool hasLargeRegisterPool, bool doPruneNBL, bool doCalcEnergies> | |||
| void | launchNbnxmKernelHelper (NbnxmGpu *nb, const StepWorkload &stepWork, InteractionLocality iloc) | ||
| template void | launchNbnxmKernelHelper< false, false, false > (NbnxmGpu *nb, const StepWorkload &stepWork, const InteractionLocality iloc) | ||
| template void | launchNbnxmKernelHelper< false, false, true > (NbnxmGpu *nb, const StepWorkload &stepWork, const InteractionLocality iloc) | ||
| template void | launchNbnxmKernelHelper< false, true, true > (NbnxmGpu *nb, const StepWorkload &stepWork, const InteractionLocality iloc) | ||
| template void | launchNbnxmKernelHelper< false, true, false > (NbnxmGpu *nb, const StepWorkload &stepWork, const InteractionLocality iloc) | ||
| template void | launchNbnxmKernelHelper< true, false, false > (NbnxmGpu *nb, const StepWorkload &stepWork, const InteractionLocality iloc) | ||
| template void | launchNbnxmKernelHelper< true, false, true > (NbnxmGpu *nb, const StepWorkload &stepWork, const InteractionLocality iloc) | ||
| template void | launchNbnxmKernelHelper< true, true, true > (NbnxmGpu *nb, const StepWorkload &stepWork, const InteractionLocality iloc) | ||
| template void | launchNbnxmKernelHelper< true, true, false > (NbnxmGpu *nb, const StepWorkload &stepWork, const InteractionLocality iloc) | ||
| void | launchNbnxmKernel (NbnxmGpu *nb, const StepWorkload &stepWork, InteractionLocality iloc, bool doPrune) | ||
| Launch HIP NBNXM kernel. More... | |||
| template<ElecType elecType, VdwType vdwType, bool doPrune, bool doCalcEnergies, PairlistType pairlistType> | |||
| static const std::string | getKernelName () | ||
| Lookup kernel name based on launch configuration. | |||
| static __device__ float2 | fetchNbfpC6C12 (const float2 *nbfpComb, int type) | ||
| static __device__ float2 | convertSigmaEpsilonToC6C12 (const float sigma, const float epsilon) | ||
Convert sigma and epsilon VdW parameters to c6,c12 pair. | |||
| template<bool doCalcEnergies> | |||
| static __device__ void | ljForceSwitch (const shift_consts_t dispersionShift, const shift_consts_t repulsionShift, const float2 c6c12, const float rVdwSwitch, const float rInv, const float r2, float *fInvR, float *eLJ) | ||
| Calculate force and energy for a pair of atoms, VdW force-switch flavor. | |||
| template<enum VdwType vdwType> | |||
| static __device__ float | calculateLJEwaldC6Grid (const Float2 *nbfpComb, const int typeI, const int typeJ) | ||
| Fetch C6 grid contribution coefficients and return the product of these. | |||
| template<bool doCalcEnergies, enum VdwType vdwType> | |||
| static __device__ void | ljEwaldComb (const Float2 *nbfpComb, const float sh_lj_ewald, const int typeI, const int typeJ, const float r2, const float r2Inv, const float lje_coeff2, const float lje_coeff6_6, const float pairExclMask, float *fInvR, float *eLJ) | ||
| Calculate LJ-PME grid force contribution with geometric or LB combination rule. | |||
| template<bool doCalcEnergies> | |||
| static __device__ void | ljPotentialSwitch (const switch_consts_t vdwSwitch, const float rVdwSwitch, const float rInv, const float r2, float *fInvR, float *eLJ) | ||
| Apply potential switch. | |||
| static __device__ float | pmeCorrF (const float z2) | ||
| Calculate analytical Ewald correction term. | |||
| static __device__ float2 | fetchCoulombForceR (const float *coulombTable, int index) | ||
| static __device__ float | interpolateCoulombForceR (const float *coulombTable, const float coulombTabScale, const float r) | ||
| Interpolate Ewald coulomb force correction using the F*r table. | |||
| template<PairlistType pairlistType> | |||
| static __device__ float | reduceForceJWarpShuffle (AmdPackedFloat3 f, const int tidxi) | ||
| Reduce c_clSize j-force components using AMD DPP instruction. More... | |||
| template<PairlistType pairlistType> | |||
| static __device__ float | reduceForceIWarpShuffle (AmdPackedFloat3 f, const int tidxi, const int tidxj) | ||
| Lowest level i force reduction. More... | |||
| template<PairlistType pairlistType, bool calculateShift> | |||
| static __device__ float3 | reduceForceIAtomics (AmdPackedFloat3 input, float3 *result, const int tidxj, const int aidx) | ||
| Lowest level i force reduction. More... | |||
| template<bool calculateShift, PairlistType pairlistType> | |||
| static __device__ void | reduceForceI (AmdPackedFloat3 *input, float3 *result, const int tidxi, const int tidxj, const int tidx, const int sci, float3 *fShift, const int shiftBase) | ||
| Reduce i forces. More... | |||
| template<PairlistType pairlistType> | |||
| static __device__ void | reduceEnergyWarpShuffle (float localLJ, float localEl, float *gm_LJ, float *gm_El, int tidx) | ||
| Energy reduction kernel. More... | |||
| template<bool doPruneNBL, bool doCalcEnergies, enum ElecType elecType, enum VdwType vdwType, int nthreadZ, int minBlocksPerMp, PairlistType pairlistType> | |||
| __launch_bounds__ (c_clSizeSq< pairlistType > *nthreadZ, minBlocksPerMp) __global__ static void nbnxmKernel(NBAtomDataGpu atdat | |||
| Main kernel for NBNXM. More... | |||
| template<PairlistType pairlistType, bool haveFreshList, int threadZ, int minBlocksPp> | |||
| __launch_bounds__ (c_clSizeSq< pairlistType > *threadZ, minBlocksPp) __global__ static void nbnxmKernelPruneOnly(NBAtomDataGpu atdat | |||
| Prune-only kernel for NBNXM. More... | |||
| void | launchNbnxmKernelPruneOnly (NbnxmGpu *nb, const InteractionLocality iloc, const int *numParts, const int numSciInPart) | ||
| Launch HIP NBNXM prune-only kernel. More... | |||
| template<int threadsPerBlock> | |||
| __launch_bounds__ (threadsPerBlock) __global__ void nbnxmKernelBucketSciSort(GpuPairlist plist) | |||
| HIP bucket sci sort kernel. More... | |||
| void | launchNbnxmKernelHelperSciSort (const DeviceStream &deviceStream, GpuPairlist *plist) | ||
| NBNXM kernel launch code. | |||
| void | launchNbnxmKernelSciSort (NbnxmGpu *nb, InteractionLocality iloc) | ||
| Launch kernel to sum up energies and shifts. | |||
| template<PairlistType pairlistType> | |||
| __device__ __forceinline__ int | nb_any_internal (int predicate, int widx) | ||
| template<PairlistType pairlistType, typename T > | |||
| __device__ size_t | incrementSharedMemorySlotPtr () | ||
| Increment the pointer into shared memory. More... | |||
| size_t | numberOfKernelBlocksSanityCheck (int numSci, const DeviceInformation &deviceInfo) | ||
| template<bool isPruneKernel, int numThreadZ, VdwType vdwType, PairlistType pairlistType> | |||
| constexpr size_t | requiredSharedMemorySize () | ||
| bool | targetHasLargeRegisterPool (const DeviceInformation &deviceInfo) | ||
| Find out if the target device has a large enough register pool (MI2xx and later) | |||
| void | clear_fshift (real *fshift) | ||
| Clears the shift forces. | |||
| void | reduce_energies_over_lists (const nbnxn_atomdata_t *nbat, int nlist, real *Vvdw, real *Vc) | ||
| Reduces the collected energy terms over the pair-lists/threads. | |||
|
enum EwaldExclusionType int typedef void() | NbnxmKernelFunc (const NbnxnPairlistCpu &nbl, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| Pair-interaction kernel type that also calculates energies. | |||
| CoulombKernelType | getCoulombKernelType (EwaldExclusionType ewaldExclusionType, CoulombInteractionType coulombInteractionType, bool haveEqualCoulombVwdRadii, bool nbnxmIsDirectCoulombProvider) | ||
| Lookup function for Coulomb kernel type. | |||
| int | getVdwKernelType (NbnxmKernelType kernelType, LJCombinationRule ljCombinationRule, VanDerWaalsType vanDerWaalsType, InteractionModifiers interactionModifiers, LongRangeVdW longRangeVdW) | ||
| Lookup function for Vdw kernel type. | |||
| static void | nbnxn_kernel_cpu (const PairlistSet &pairlistSet, const NbnxmKernelSetup &kernelSetup, nbnxn_atomdata_t *nbat, const interaction_const_t &ic, gmx::ArrayRef< const gmx::RVec > shiftVectors, const gmx::StepWorkload &stepWork, int clearF, real *vCoulomb, real *vVdw, gmx_wallcycle *wcycle) | ||
| Dispatches the non-bonded N versus M atom cluster CPU kernels. More... | |||
| static void | accountFlops (t_nrnb *nrnb, const PairlistSet &pairlistSet, const nonbonded_verlet_t &nbv, const interaction_const_t &ic, const gmx::StepWorkload &stepWork) | ||
| void | nbnxn_kernel_gpu_ref (const NbnxnPairlistGpu *nbl, const nbnxn_atomdata_t *nbat, const interaction_const_t &iconst, ArrayRef< const RVec > shiftvec, const StepWorkload &stepWork, int clearF, ArrayRef< real > f, real *fshift, real *Vc, real *Vvdw) | ||
| Reference (slow) kernel for nb n vs n GPU type pair lists. | |||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJ_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJ_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJ_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJFsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJFsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJFsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJPsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJPsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJPsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombGeom_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombGeom_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombGeom_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombLB_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombLB_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombLB_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJ_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJ_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJ_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJFsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJFsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJFsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJPsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJPsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJPsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombGeom_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombGeom_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombGeom_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombLB_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombLB_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombLB_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJ_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJ_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJ_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJFsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJFsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJFsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJPsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJPsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJPsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombGeom_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombGeom_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombGeom_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombLB_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombLB_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombLB_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJ_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJ_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJ_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJFsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJFsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJFsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJPsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJPsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJPsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombGeom_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombGeom_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombGeom_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombLB_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombLB_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombLB_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJ_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJ_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJ_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJFsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJFsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJFsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJPsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJPsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJPsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombGeom_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombGeom_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombGeom_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombLB_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombLB_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombLB_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJ_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJ_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJ_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJFsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJFsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJFsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJPsw_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJPsw_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJPsw_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombGeom_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombGeom_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombGeom_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombLB_F_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombLB_VF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| void | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombLB_VgrpF_ref (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template<NbnxmKernelType kernelType> | |||
| void | nbnxmRefPruneKernel (NbnxnPairlistCpu *nbl, const nbnxn_atomdata_t *nbat, ArrayRef< const RVec > shiftvec, real rlistInner) | ||
Prune a single NbnxnPairlistCpu entry with distance rlistInner. More... | |||
| template void | nbnxmRefPruneKernel< NbnxmKernelType::Cpu4x4_PlainC > (NbnxnPairlistCpu *nbl, const nbnxn_atomdata_t *nbat, ArrayRef< const RVec > shiftvec, real rlistInner) | ||
| template void | nbnxmRefPruneKernel< NbnxmKernelType::Cpu1x1_PlainC > (NbnxnPairlistCpu *nbl, const nbnxn_atomdata_t *nbat, ArrayRef< const RVec > shiftvec, real rlistInner) | ||
| template<KernelLayout kernelLayout, KernelCoulombType coulombType, VdwCutoffCheck vdwCutoffCheck, LJCombinationRule ljCombinationRule, InteractionModifiers vdwModifier, LJEwald ljEwald, EnergyOutput energyOutput> | |||
| void | nbnxmKernelSimd (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| The actual NBNxM SIMD kernel. More... | |||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r2xMM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::None > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::System > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::RF, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldTabulated, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::No, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::EwaldAnalytical, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::Geometric, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::LorentzBerthelot, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::ForceSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotSwitch, LJEwald::None, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
| template void | nbnxmKernelSimd< KernelLayout::r4xM, KernelCoulombType::None, VdwCutoffCheck::Yes, LJCombinationRule::None, InteractionModifiers::PotShift, LJEwald::CombGeometric, EnergyOutput::GroupPairs > (const NbnxnPairlistCpu &pairlist, const nbnxn_atomdata_t &nbat, const interaction_const_t &ic, const rvec *shift_vec, nbnxn_atomdata_output_t *out) | ||
|
std::unique_ptr < nonbonded_verlet_t > | init_nb_verlet (const MDLogger &mdlog, const t_inputrec &inputrec, const t_forcerec &forcerec, const MpiComm &mpiComm, const gmx_domdec_t *dd, const gmx_hw_info_t &hardwareInfo, bool useGpuForNonbonded, bool useGpuForNonbondedFE, const DeviceStreamManager *deviceStreamManager, const gmx_mtop_t &mtop, bool localAtomOrderMatchesNbnxmOrder, ObservablesReducerBuilder *observablesReducerBuilder, ArrayRef< const RVec > coordinates, matrix box, gmx_wallcycle *wcycle) | ||
| Creates an Nbnxm object. | |||
| void | nbnxn_put_on_grid_nonlocal (nonbonded_verlet_t *nb_verlet, const gmx::DomdecZones &zones, ArrayRef< const int32_t > atomInfo, ArrayRef< const RVec > x) | ||
| As nbnxn_put_on_grid, but for the non-local atoms. More... | |||
| std::optional< std::string > | nbnxmGpuClusteringDescription () | ||
| Returns information for describing the NBNXM GPU clustering support, if applicable to the build. | |||
| static constexpr bool | isGpuKernelType (const NbnxmKernelType kernelType) | ||
| const char * | nbnxmKernelTypeToName (NbnxmKernelType kernelType) | ||
| static constexpr bool | sc_isGpuSpecificPairlist (const PairlistType pairlistType) | ||
| static constexpr int | sc_gpuClusterSize (const PairlistType pairlistType) | ||
| The NBNxM GPU i-cluster size in atoms for the given NBNxM GPU kernel layout. | |||
| static constexpr int | sc_gpuNumClusterPerCellX (const PairlistType pairlistType) | ||
| The number of super clusters in the X dimension. | |||
| static constexpr int | sc_gpuNumClusterPerCellY (const PairlistType pairlistType) | ||
| The number of super clusters in the X dimension. | |||
| static constexpr int | sc_gpuNumClusterPerCellZ (const PairlistType pairlistType) | ||
| The number of super clusters in the X dimension. | |||
| static constexpr int | sc_gpuClusterPerSuperCluster (const PairlistType pairlistType) | ||
| The NBNxM GPU super cluster size according to the kernel layout. | |||
| static constexpr int | sc_gpuNumClusterPerCell (const PairlistType pairlistType) | ||
| The NBNxM GPU super cluster size according to the kernel layout. | |||
| static constexpr int | sc_gpuClusterPairSplit (const PairlistType pairlistType) | ||
| The number of sub-parts used for data storage for a GPU cluster pair. More... | |||
| static constexpr bool | sc_gpuPairlistHasSplitJCluster (const PairlistType pairlistType) | ||
| static constexpr int | sc_gpuSplitJClusterSize (const PairlistType pairlistType) | ||
| The size of the J clusters on the GPU, after taking pair splitting into account. | |||
| constexpr int | sc_gpuJgroupSize (const PairlistType pairlistType) | ||
| With GPU kernels we group cluster pairs in 4 to optimize memory usage of integers containing 32 bits. | |||
| static constexpr int | sc_gpuParallelExecutionWidth (const PairlistType pairlistType) | ||
| Parallel execution width corresponding to the current kernel layout. | |||
| static constexpr int | sc_gpuExclSize (const PairlistType pairlistType) | ||
| The fixed size of the exclusion mask array for a half GPU cluster pair. | |||
| real | nbnxmPairlistVolumeRadiusIncrease (bool useGpu, real atomDensity) | ||
| Returns the increase in pairlist radius when including volume of pairs beyond rlist. More... | |||
| real | nbnxn_get_rlist_effective_inc (int clusterSize, const RVec &averageClusterBoundingBox) | ||
| Returns the effective list radius of the pair-list. More... | |||
| static int | get_2log (int n) | ||
Returns the base-2 log of n.
| |||
| static constexpr int | sc_iClusterSize (const NbnxmKernelType kernelType) | ||
| The nbnxn i-cluster size in atoms for the given NBNxM kernel type. | |||
| static constexpr int | sc_jClusterSize (const NbnxmKernelType kernelType) | ||
| The nbnxn j-cluster size in atoms for the given NBNxM kernel type. More... | |||
| static constexpr bool | kernelTypeIsSimd (const NbnxmKernelType kernelType) | ||
| Returns whether a SIMD kernel is in use. | |||
| static constexpr bool | kernelTypeIsPlainC (const NbnxmKernelType kernelType) | ||
| Returns whether a plain-C kernel is in use. | |||
| static constexpr bool | kernelTypeUsesSimplePairlist (const NbnxmKernelType kernelType) | ||
Returns whether the pair-list corresponding to kernelType is simple. | |||
| static bool | useLjCombRule (const enum VdwType vdwType) | ||
| Returns true if LJ combination rules are used in the non-bonded kernels. More... | |||
| void | gpu_copy_xq_to_gpu (NbnxmGpu gmx_unused *nb, const struct nbnxn_atomdata_t gmx_unused *nbdata, AtomLocality gmx_unused aloc) | ||
| Launch asynchronously the xq buffer host to device copy. More... | |||
| void | gpu_launch_kernel (NbnxmGpu gmx_unused *nb, const StepWorkload gmx_unused &stepWork, InteractionLocality gmx_unused iloc) | ||
| Launch asynchronously the nonbonded force calculations. More... | |||
| void | gpu_launch_kernel_pruneonly (NbnxmGpu gmx_unused *nb, InteractionLocality gmx_unused iloc, int gmx_unused numParts) | ||
| Launch asynchronously the nonbonded prune-only kernel. More... | |||
| void | gpu_launch_cpyback (NbnxmGpu gmx_unused *nb, nbnxn_atomdata_t gmx_unused *nbatom, const StepWorkload gmx_unused &stepWork, AtomLocality gmx_unused aloc) | ||
| Launch asynchronously the download of short-range forces from the GPU (and energies/shift forces if required). | |||
| bool | gpu_try_finish_task (NbnxmGpu gmx_unused *nb, const StepWorkload gmx_unused &stepWork, AtomLocality gmx_unused aloc, real gmx_unused *e_lj, real gmx_unused *e_el, double gmx_unused *dvdl_lj, double gmx_unused *dvdl_el, ArrayRef< RVec > gmx_unused shiftForces, ForeignLambdaTerms gmx_unused *foreign_term, GpuTaskCompletion gmx_unused completionKind) | ||
| Attempts to complete nonbonded GPU task. More... | |||
| float | gpu_wait_finish_task (NbnxmGpu gmx_unused *nb, const StepWorkload gmx_unused &stepWork, AtomLocality gmx_unused aloc, const bool gmx_unused haveSoftCore, gmx_enerdata_t gmx_unused *enerd, ArrayRef< RVec > gmx_unused shiftForces, gmx_wallcycle gmx_unused *wcycle) | ||
| Completes the nonbonded GPU task blocking until GPU tasks and data transfers to finish. More... | |||
| void | nbnxn_gpu_init_x_to_nbat_x (const GridSet gmx_unused &gridSet, NbnxmGpu gmx_unused *gpu_nbv) | ||
| Initialization for X buffer operations on GPU. Called on the NS step and performs (re-)allocations and memory copies. ! | |||
| void | nbnxn_gpu_x_to_nbat_x (const Grid gmx_unused &grid, NbnxmGpu gmx_unused *gpu_nbv, DeviceBuffer< RVec > gmx_unused d_x, GpuEventSynchronizer gmx_unused *xReadyOnDevice, AtomLocality gmx_unused locality, int gmx_unused gridId, int gmx_unused numColumnsMax, bool gmx_unused mustInsertNonLocalDependency) | ||
| X buffer operations on GPU: performs conversion from rvec to nb format. More... | |||
| void | nbnxnInsertNonlocalGpuDependency (NbnxmGpu gmx_unused *nb, InteractionLocality gmx_unused interactionLocality) | ||
| Sync the nonlocal stream with dependent tasks in the local queue. More... | |||
| void | setupGpuShortRangeWorkLow (NbnxmGpu gmx_unused *nb, const ListedForcesGpu gmx_unused *listedForcesGpu, InteractionLocality gmx_unused iLocality) | ||
| Set up internal flags that indicate what type of short-range work there is. More... | |||
| bool | haveGpuShortRangeWork (const NbnxmGpu gmx_unused *nb, InteractionLocality gmx_unused interactionLocality) | ||
| Returns true if there is GPU short-range work for the given interaction locality. More... | |||
| void | nbnxn_gpu_x_to_nbat_x (const Grid &grid, NbnxmGpu *nb, DeviceBuffer< RVec > d_x, GpuEventSynchronizer *xReadyOnDevice, const AtomLocality locality, int gridId, int numColumnsMax, bool mustInsertNonLocalDependency) | ||
| static void | init_ewald_coulomb_force_table (const EwaldCorrectionTables &tables, NBParamGpu *nbp, const DeviceContext &deviceContext, const DeviceStream &deviceStream) | ||
| static bool | useTabulatedEwaldByDefault (InteractionModifiers vdwModifier, const DeviceInformation &deviceInfo) | ||
| static ElecType | nbnxn_gpu_pick_ewald_kernel_type (const interaction_const_t &ic, const DeviceInformation &deviceInfo) | ||
| static void | set_cutoff_parameters (NBParamGpu *nbp, const interaction_const_t &ic, const PairlistParams &listParams) | ||
| static void | init_timings (gmx_wallclock_gpu_nbnxn_t *t) | ||
| static void | initAtomdataFirst (NBAtomDataGpu *atomdata, int numTypes, const DeviceContext &deviceContext, const DeviceStream &localStream, const std::optional< int > nLambda) | ||
Initialize atomdata first time; it only gets filled at pair-search. | |||
| static VdwType | nbnxmGpuPickVdwKernelType (const interaction_const_t &ic, LJCombinationRule ljCombinationRule) | ||
| static ElecType | nbnxmGpuPickElectrostaticsKernelType (const interaction_const_t &ic, const DeviceInformation &deviceInfo) | ||
| static void | initNbparam (NBParamGpu *nbp, const interaction_const_t &ic, const PairlistParams &listParams, const nbnxn_atomdata_t::Params &nbatParams, const DeviceContext &deviceContext, const DeviceStream &localStream, const std::optional< int > nLambda) | ||
| Initialize the nonbonded parameter data structure. | |||
| static GpuPairlistByLocality | initializeGpuLists (bool localAndNonLocal) | ||
|
static gmx_unused GpuFeplistByLocality | initializeGpuFepLists (bool localAndNonLocal) | ||
| void | copy_gpu_fepparams (NbnxmGpu *nb, const bool bFepGpuNonBonded, const float alphaCoul, const float alphaVdw, const int lambdaPower, const float sigma6WithInvalidSigma, const float sigma6Minimum, const float lambdaCoul, const float lambdaVdw, const int nLambda, const EnumerationArray< FreeEnergyPerturbationCouplingType, std::vector< double >> &all_lambda) | ||
| NbnxmGpu * | gpu_init (const DeviceStreamManager &deviceStreamManager, const interaction_const_t *ic, const PairlistParams &listParams, const nbnxn_atomdata_t *nbat, const bool bLocalAndNonlocal, const gmx_unused std::optional< int > nLambda) | ||
| void | gpu_pme_loadbal_update_param (nonbonded_verlet_t *nbv, const interaction_const_t &ic) | ||
| void | gpu_upload_shiftvec (NbnxmGpu *nb, const nbnxn_atomdata_t *nbatom) | ||
| void | gpu_init_pairlist (NbnxmGpu *nb, const NbnxnPairlistGpu *h_plist, const InteractionLocality iloc) | ||
| This function is documented in the header file. | |||
| void | gpu_init_feppairlist (NbnxmGpu *nb, const AtomPairlist &h_feplist, const InteractionLocality iloc, const GridSet &gridSet) | ||
| void | gpu_init_atomdata (NbnxmGpu *nb, const nbnxn_atomdata_t *nbat) | ||
| void | gpu_clear_outputs (NbnxmGpu *nb, bool computeVirial) | ||
| gmx_wallclock_gpu_nbnxn_t * | gpu_get_timings (NbnxmGpu *nb) | ||
| This function is documented in the header file. | |||
| void | gpu_reset_timings (nonbonded_verlet_t *nbv) | ||
| This function is documented in the header file. | |||
| bool | gpu_is_kernel_ewald_analytical (const NbnxmGpu *nb) | ||
| void | setupGpuShortRangeWorkLow (NbnxmGpu *nb, const ListedForcesGpu *listedForcesGpu, const InteractionLocality iLocality) | ||
| bool | haveGpuShortRangeWork (const NbnxmGpu *nb, const InteractionLocality interactionLocality) | ||
| void | gpu_launch_cpyback (NbnxmGpu *nb, struct nbnxn_atomdata_t *nbatom, const StepWorkload &stepWork, const AtomLocality atomLocality) | ||
| Launch asynchronously the download of nonbonded forces from the GPU (and energies/shift forces if required). | |||
| void | nbnxnInsertNonlocalGpuDependency (NbnxmGpu *nb, const InteractionLocality interactionLocality) | ||
| void | gpu_copy_xq_to_gpu (NbnxmGpu *nb, const nbnxn_atomdata_t *nbatom, const AtomLocality atomLocality) | ||
| Launch asynchronously the xq buffer host to device copy. | |||
| void | nbnxn_gpu_init_x_to_nbat_x (const GridSet &gridSet, NbnxmGpu *gpu_nbv) | ||
| void | gpu_free (NbnxmGpu *nb) | ||
| This function is documented in the header file. | |||
| NBAtomDataGpu * | gpuGetNBAtomData (NbnxmGpu *nb) | ||
| DeviceBuffer< RVec > | gpu_get_f (NbnxmGpu *nb) | ||
| static | __attribute__ ((always_inline)) Float2 convertSigmaEpsilonToC6C12(const float sigma | ||
Convert sigma and epsilon VdW parameters to c6,c12 pair. More... | |||
| if | constexpr (calcFr) | ||
| if | constexpr (doCalcEnergies) | ||
| static bool | nbnxmSimdSupported (const MDLogger &mdlog, const t_inputrec &inputrec) | ||
Returns whether CPU SIMD support exists for the given inputrec. More... | |||
| static NbnxmKernelType | pickNbnxmKernelCpuSimdType (const t_inputrec &inputrec, const gmx_hw_info_t gmx_unused &hardwareInfo) | ||
| Returns the most suitable CPU SIMD kernel type. More... | |||
| static EwaldExclusionType | pickNbnxmKernelCpuSimdExclusion (const gmx_hw_info_t gmx_unused &hardwareInfo) | ||
| Returns the most suitable CPU SIMD kernel exclusion type. More... | |||
| static NbnxmKernelSetup | pickNbnxnKernelCpu (const t_inputrec &inputrec, const gmx_hw_info_t &hardwareInfo, bool useSimd, const MDLogger &mdlog) | ||
| Returns the most suitable CPU kernel type and Ewald handling. | |||
| static NbnxmKernelSetup | pick_nbnxn_kernel (const gmx::MDLogger &mdlog, gmx_bool use_simd_kernels, const gmx_hw_info_t &hardwareInfo, const PairlistType gpuPairlistType, const NonbondedResource &nonbondedResource, const t_inputrec &inputrec) | ||
| Returns the most suitable kernel type and Ewald handling. | |||
| static int | getMinimumIlistCountForGpuBalancing (NbnxmGpu *nbnxmGpu) | ||
| Gets and returns the minimum i-list count for balancing based on the GPU used or env.var. when set. | |||
|
static std::optional < LJCombinationRule > | chooseLJCombinationRule (const t_forcerec &forcerec) | ||
| Returns the LJ combination rule choices for the LJ pair parameters. | |||
| static LJCombinationRule | chooseLJPmeCombinationRule (const t_forcerec &forcerec) | ||
| Returns the LJ combination rule choices for the LJ PME-grid parameters. | |||
| static void | validate_global_work_size (const KernelLaunchConfig &config, int work_dim, const DeviceInformation *dinfo) | ||
| Validates the input global work size parameter. | |||
| static cl_kernel | selectPruneKernel (cl_kernel kernel_pruneonly[], bool firstPrunePass) | ||
| Return a pointer to the prune kernel version to be executed at the current invocation. More... | |||
| static cl_kernel | select_nbnxn_kernel (NbnxmGpu *nb, enum ElecType elecType, enum VdwType vdwType, bool bDoEne, bool bDoPrune) | ||
| Return a pointer to the kernel version to be executed at the current step. OpenCL kernel objects are cached in nb. If the requested kernel is not found in the cache, it will be created and the cache will be updated. | |||
| static int | calc_shmem_required_nonbonded (enum VdwType vdwType, bool bPrefetchLjParam) | ||
| Calculates the amount of shared memory required by the nonbonded kernel in use. | |||
| static void | fillin_ocl_structures (NBParamGpu *nbp, cl_nbparam_params_t *nbparams_params) | ||
| Initializes data structures that are going to be sent to the OpenCL device. More... | |||
| static int | calc_shmem_required_prune (const int num_threads_z) | ||
| Calculates the amount of shared memory required by the prune kernel. More... | |||
| static cl_kernel | nbnxn_gpu_create_kernel (NbnxmGpu *nb, const char *kernel_name) | ||
| Initializes the OpenCL kernel pointers of the nbnxn_ocl_ptr_t input data structure. | |||
| static void | nbnxn_gpu_init_kernels (NbnxmGpu *nb) | ||
| Initializes the OpenCL kernel pointers of the nbnxn_ocl_ptr_t input data structure. | |||
| static void | free_kernel (cl_kernel *kernel_ptr) | ||
| Releases an OpenCL kernel pointer. | |||
| static void | free_kernels (cl_kernel *kernels, int count) | ||
| Releases a list of OpenCL kernel pointers. | |||
| static void | freeGpuProgram (cl_program program) | ||
| Free the OpenCL program. More... | |||
| static std::string | makeDefinesForKernelTypes (bool bFastGen, enum ElecType elecType, enum VdwType vdwType) | ||
| Returns a string with the compiler defines required to avoid all flavour generation. More... | |||
| void | nbnxn_gpu_compile_kernels (NbnxmGpu *nb) | ||
Compiles nbnxn kernels for OpenCL GPU given by mygpu. More... | |||
| static constexpr bool | c_useSimdGpuClusterPairDistance (const PairlistType layoutType) | ||
| static constexpr int | sizeNeededForBufferFlags (const int numAtoms) | ||
| static void | resizeAndZeroBufferFlags (std::vector< gmx_bitmask_t > *flags, const int numAtoms) | ||
| static real | listRangeForBoundingBoxToGridCell (real rlist, const GridDimensions &gridDims) | ||
| static real | listRangeForGridCellToGridCell (real rlist, const GridDimensions &iGridDims, const GridDimensions &jGridDims) | ||
| template<int dim> | |||
| static void | get_cell_range (real b0, real b1, const GridDimensions &jGridDims, real d2, real rlist, int *cf, int *cl) | ||
| template<PairlistType layoutType> | |||
| static bool gmx_unused | clusterpairInRangePlainC (const NbnxmPairlistGpuWork &work, const int si, const int csj, const int jCoordStride, const real *x_j, const real rlist2) | ||
| template<PairlistType layoutType> | |||
| static bool | clusterpairInRange (const NbnxmPairlistGpuWork &work, const int si, const int csj, const int jCoordStride, const real *x_j, const real rlist2) | ||
| template<typename JClusterListType > | |||
| static int | findJClusterInJList (int jCluster, const JListRanges &ranges, const JClusterListType &cjList) | ||
| template<PairlistType layoutType> | |||
| static void | setExclusionsForIEntry (const GridSet &gridSet, NbnxnPairlistCpu *nbl, bool diagRemoved, int na_cj_2log, const ListOfLists< int > &exclusions) | ||
| static KernelLayoutClusterRatio | layoutClusterRatio (const Grid::Geometry &geometry) | ||
| Returns the j/i cluster size ratio for the geometry of a grid. | |||
| static void | fep_list_new_nri_copy (AtomPairlist *nlist, int energyGroupPair=-1) | ||
| Add a new entry to the i-list as a copy of the last entry. More... | |||
| template<PairlistType layoutType> | |||
| static void | make_fep_list (ArrayRef< const int > atomIndices, const nbnxn_atomdata_t *nbat, NbnxnPairlistCpu *nbl, bool bDiagRemoved, const real shx, const real shy, const real shz, const real gmx_unused rlist_fep2, const Grid &iGrid, const Grid &jGrid, AtomPairlist *nlist) | ||
| template<PairlistType layoutType> | |||
| static int | cj_mod_cjPacked (int cj) | ||
| template<PairlistType layoutType> | |||
| static int | cj_to_cjPacked (int cj) | ||
| template<PairlistType layoutType> | |||
| static void | make_fep_list (ArrayRef< const int > atomIndices, const nbnxn_atomdata_t *nbat, NbnxnPairlistGpu *nbl, bool bDiagRemoved, real shx, real shy, real shz, real rlist_fep2, const Grid &iGrid, const Grid &jGrid, AtomPairlist *nlist) | ||
| template<PairlistType layoutType> | |||
| static void | setExclusionsForIEntry (const GridSet &gridSet, NbnxnPairlistGpu *nbl, bool diagRemoved, int gmx_unused na_cj_2log, const ListOfLists< int > &exclusions) | ||
| template<PairlistType layoutType> | |||
| static void | addNewIEntry (NbnxnPairlistCpu *nbl, int ci, int shift, int flags) | ||
| template<PairlistType layoutType> | |||
| static void | addNewIEntry (NbnxnPairlistGpu *nbl, int sci, int shift, int gmx_unused flags) | ||
| static void | sort_cj_excl (nbnxn_cj_t *cj, int ncj, NbnxmPairlistCpuWork *work) | ||
| template<PairlistType layoutType> | |||
| static void | closeIEntry (NbnxnPairlistCpu *nbl, int gmx_unused sp_max_av, bool gmx_unused progBal, float gmx_unused nsp_tot_est, int gmx_unused thread, int gmx_unused nthread) | ||
| template<PairlistType layoutType> | |||
| static void | split_sci_entry (NbnxnPairlistGpu *nbl, int nsp_target_av, bool progBal, float nsp_tot_est, int thread, int nthread) | ||
| template<PairlistType layoutType> | |||
| static void | closeIEntry (NbnxnPairlistGpu *nbl, int nsp_max_av, bool progBal, float nsp_tot_est, int thread, int nthread) | ||
| template<PairlistType layoutType> | |||
| static void | sync_work (NbnxnPairlistCpu gmx_unused *nbl) | ||
| template<PairlistType layoutType> | |||
| static void | sync_work (NbnxnPairlistGpu *nbl) | ||
| static void | clear_pairlist (NbnxnPairlistCpu *nbl) | ||
| static void | clear_pairlist (NbnxnPairlistGpu *nbl) | ||
| static void | set_icell_bb_simple (ArrayRef< const BoundingBox > bb, int ci, const RVec &shift, BoundingBox *bb_ci) | ||
| template<PairlistType layoutType> | |||
| static void | set_icell_bb (const Grid &iGrid, int ci, const RVec &shift, NbnxmPairlistCpuWork *work) | ||
| template<PairlistType layoutType> | |||
| static gmx_unused void | set_icell_bbxxxx_supersub (ArrayRef< const float > bb, int ci, const RVec &shift, float *bb_ci) | ||
| template<PairlistType layoutType> | |||
| static gmx_unused void | set_icell_bb_supersub (ArrayRef< const BoundingBox > bb, int ci, const RVec &shift, BoundingBox *bb_ci) | ||
| template<PairlistType layoutType> | |||
| static gmx_unused void | set_icell_bb (const Grid &iGrid, int ci, const RVec &shift, NbnxmPairlistGpuWork *work) | ||
| template<ClusterDistanceKernelType kernelType> | |||
| static void | icellSetXSimple (int ci, const RVec &shift, int stride, const real *x, NbnxmPairlistCpuWork::IClusterData *iClusterData) | ||
| template<PairlistType > | |||
| static void | icell_set_x (int ci, const RVec &shift, int stride, const real *x, const ClusterDistanceKernelType kernelType, NbnxmPairlistCpuWork *work) | ||
| template<PairlistType layoutType> | |||
| static void | icell_set_x (int ci, const RVec &shift, int stride, const real *x, ClusterDistanceKernelType, NbnxmPairlistGpuWork *work) | ||
| template<PairlistType layoutType> | |||
| static real | minimum_subgrid_size_xy (const Grid &grid) | ||
| template<PairlistType layoutType> | |||
| static real | effective_buffer_1x1_vs_MxN (const Grid &iGrid, const Grid &jGrid) | ||
| static real | nonlocal_vol2 (const gmx::DomdecZones &zones, const rvec ls, real r) | ||
| static void | get_nsubpair_target (const GridSet &gridSet, const InteractionLocality iloc, const real rlist, const int min_ci_balanced, int *nsubpair_target, float *nsubpair_tot_est) | ||
| static void | print_nblist_ci_cj (FILE *fp, const NbnxnPairlistCpu &nbl) | ||
| template<PairlistType layoutType> | |||
| static void | print_nblist_sci_cj (FILE *fp, const NbnxnPairlistGpu &nbl) | ||
| template<PairlistType layoutType> | |||
| static void | combine_nblists (ArrayRef< const NbnxnPairlistGpu > nbls, NbnxnPairlistGpu *nblc) | ||
| static void | balance_fep_lists (ArrayRef< std::unique_ptr< AtomPairlist >> fepLists, ArrayRef< PairsearchWork > work) | ||
| static void | combine_fep_lists (ArrayRef< std::unique_ptr< AtomPairlist >> fepLists) | ||
| static float | boundingbox_only_distance2 (const GridDimensions &iGridDims, const GridDimensions &jGridDims, real rlist, bool simple, const PairlistType layoutType) | ||
| static int | get_ci_block_size (const Grid &iGrid, const bool haveMultipleDomains, const int numLists) | ||
| Returns a suitable block size, in cells, per thread that will generate reasonably balanced lists. | |||
| static int | getBufferFlagShift (int numAtomsPerCluster) | ||
| static void | makeClusterListWrapper (NbnxnPairlistCpu *nbl, const Grid gmx_unused &iGrid, const int ci, const Grid &jGrid, const int firstCell, const int lastCell, const bool excludeSubDiagonal, const nbnxn_atomdata_t *nbat, const real rlist2, const real rbb2, const ClusterDistanceKernelType kernelType, int *numDistanceChecks) | ||
| static void | makeClusterListWrapper (NbnxnPairlistGpu *nbl, const Grid &gmx_unused iGrid, const int ci, const Grid &jGrid, const int firstCell, const int lastCell, const bool excludeSubDiagonal, const nbnxn_atomdata_t *nbat, const real rlist2, const real rbb2, ClusterDistanceKernelType gmx_unused kernelType, int *numDistanceChecks) | ||
| static int | getNumSimpleJClustersInList (const NbnxnPairlistCpu &nbl) | ||
| static int | getNumSimpleJClustersInList (const gmx_unused NbnxnPairlistGpu &nbl) | ||
| static void | incrementNumSimpleJClustersInList (NbnxnPairlistCpu *nbl, int ncj_old_j) | ||
| static void | incrementNumSimpleJClustersInList (NbnxnPairlistGpu gmx_unused *nbl, int gmx_unused ncj_old_j) | ||
| static void | checkListSizeConsistency (const NbnxnPairlistCpu &nbl, const bool haveFreeEnergy) | ||
| static void | checkListSizeConsistency (const NbnxnPairlistGpu gmx_unused &nbl, bool gmx_unused haveFreeEnergy) | ||
| static void | setBufferFlags (const NbnxnPairlistCpu &nbl, const int ncj_old_j, const int gridj_flag_shift, gmx_bitmask_t *gridj_flag, const int th) | ||
| static void | setBufferFlags (const NbnxnPairlistGpu gmx_unused &nbl, int gmx_unused ncj_old_j, int gmx_unused gridj_flag_shift, gmx_bitmask_t gmx_unused *gridj_flag, int gmx_unused th) | ||
| template<typename T > | |||
| static void | nbnxn_make_pairlist_part (const GridSet &gridSet, const Grid &iGrid, const Grid &jGrid, PairsearchWork *work, const nbnxn_atomdata_t *nbat, const ListOfLists< int > &exclusions, const bool includeAllPairs, real rlist, const PairlistType pairlistType, bool bFBufferFlag, int nsubpair_max, bool progBal, float nsubpair_tot_est, int th, int nth, T *nbl, AtomPairlist *nbl_fep) | ||
| static void | reduce_buffer_flags (ArrayRef< PairsearchWork > searchWork, int nsrc, ArrayRef< gmx_bitmask_t > dest) | ||
| static void | print_reduction_cost (ArrayRef< const gmx_bitmask_t > flags, int nout) | ||
| template<bool setFlags> | |||
| static void | copySelectedListRange (const nbnxn_ci_t *gmx_restrict srcCi, const NbnxnPairlistCpu *gmx_restrict src, NbnxnPairlistCpu *gmx_restrict dest, gmx_bitmask_t *flag, int iFlagShift, int jFlagShift, int t) | ||
| static int | countClusterpairs (ArrayRef< const NbnxnPairlistCpu > pairlists) | ||
| static void | rebalanceSimpleLists (ArrayRef< const NbnxnPairlistCpu > srcSet, ArrayRef< NbnxnPairlistCpu > destSet, ArrayRef< PairsearchWork > searchWork) | ||
| static bool | checkRebalanceSimpleLists (ArrayRef< const NbnxnPairlistCpu > lists) | ||
| static void | sort_sci (NbnxnPairlistGpu *nbl) | ||
| static Range< int > | getIZoneRange (const GridSet::DomainSetup &domainSetup, const InteractionLocality locality) | ||
| static Range< int > | getJZoneRange (const gmx::DomdecZones *ddZones, const InteractionLocality locality, const int iZone) | ||
| static ArrayRef< const Grid > | getGridList (ArrayRef< const Grid > grids, const Range< int > &ddZoneRange) | ||
| static void | prepareListsForDynamicPruning (ArrayRef< NbnxnPairlistCpu > lists) | ||
| Prepares CPU lists produced by the search for dynamic pruning. | |||
| static bool | isLastLocality (const PairSearch &pairSearch, const InteractionLocality iLocality) | ||
| Returns whether iLocality is the last locality to construct pairlists for. | |||
| template<PairlistType layoutType> | |||
| static int | atomIndexInClusterpairSplit (const int atomIndex) | ||
Returns the index of atom with index atomIndex within a split (or whole when not split) cluster-pair. | |||
| constexpr bool | nbnxmSortListsOnGpu () | ||
| Whether we want to use GPU for neighbour list sorting. | |||
| template<typename T , int iClusterSize, int jClusterSize> | |||
| constexpr std::array< T, iClusterSize/jClusterSize > | diagonalMaskJSmallerI () | ||
| Returns a diagonal interaction mask with atoms j<i masked out. More... | |||
| template<typename T , int iClusterSize, int jClusterSize> | |||
| constexpr std::array< T, jClusterSize/iClusterSize > | diagonalMaskJLargerI () | ||
| Returns a diagonal interaction mask with atoms j>i masked out. More... | |||
| template<int iClusterSize, int jClusterSize> | |||
| static gmx_unused uint32_t | getImask (const bool maskOutSubDiagonal, const int ci, const int cj) | ||
| Returns a diagonal or off-diagonal interaction mask. More... | |||
| template<ClusterDistanceKernelType kernelType> | |||
| static gmx_unused constexpr int | sc_iClusterSizeSimd () | ||
| template<ClusterDistanceKernelType kernelType> | |||
| static gmx_unused constexpr int | sc_jClusterSizeSimd () | ||
| template<ClusterDistanceKernelType kernelType> | |||
| static gmx_unused constexpr int | sc_xStride () | ||
| Stride of the packed x coordinate array. | |||
| template<ClusterDistanceKernelType kernelType> | |||
| static gmx_unused int | xIndexFromCi (int ci) | ||
| Returns the nbnxn coordinate data index given the i-cluster index. | |||
| template<ClusterDistanceKernelType kernelType> | |||
| static gmx_unused int | xIndexFromCj (int cj) | ||
| Returns the nbnxn coordinate data index given the j-cluster index. | |||
| template<ClusterDistanceKernelType kernelType, int jSubClusterIndex> | |||
| static gmx_unused int | cjFromCi (int ci) | ||
| Returns the j-cluster index given the i-cluster index. More... | |||
| void | setICellCoordinatesSimd4xM (int gmx_unused ci, const RVec gmx_unused &shift, int gmx_unused stride, const real gmx_unused *x, NbnxmPairlistCpuWork gmx_unused *work) | ||
| void | setICellCoordinatesSimd2xMM (int gmx_unused ci, const RVec gmx_unused &shift, int gmx_unused stride, const real gmx_unused *x, NbnxmPairlistCpuWork gmx_unused *work) | ||
| void | makeClusterListSimd4xM (const Grid gmx_unused &jGrid, NbnxnPairlistCpu gmx_unused *nbl, int gmx_unused icluster, int gmx_unused firstCell, int gmx_unused lastCell, bool gmx_unused excludeSubDiagonal, const real gmx_unused *gmx_restrict x_j, real gmx_unused rlist2, float gmx_unused rbb2, int gmx_unused *gmx_restrict numDistanceChecks) | ||
| void | makeClusterListSimd2xMM (const Grid gmx_unused &jGrid, NbnxnPairlistCpu gmx_unused *nbl, int gmx_unused icluster, int gmx_unused firstCell, int gmx_unused lastCell, bool gmx_unused excludeSubDiagonal, const real gmx_unused *gmx_restrict x_j, real gmx_unused rlist2, float gmx_unused rbb2, int gmx_unused *gmx_restrict numDistanceChecks) | ||
| void | setICellCoordinatesSimd4xM (int ci, const RVec &shift, int gmx_unused stride, const real *x, NbnxmPairlistCpuWork *work) | ||
| Copies PBC shifted i-cell packed atom coordinates to working array for the 4xM layout. | |||
| void | setICellCoordinatesSimd2xMM (int ci, const RVec &shift, int gmx_unused stride, const real *x, NbnxmPairlistCpuWork *work) | ||
| Copies PBC shifted i-cell packed atom coordinates to working array for the 2xMM layout. | |||
| void | makeClusterListSimd4xM (const Grid &jGrid, NbnxnPairlistCpu *nbl, int icluster, int firstCell, int lastCell, bool excludeSubDiagonal, const real *gmx_restrict x_j, real rlist2, float rbb2, int *gmx_restrict numDistanceChecks) | ||
| SIMD code for checking and adding cluster-pairs to the list using the 4xM layout. More... | |||
| void | makeClusterListSimd2xMM (const Grid &jGrid, NbnxnPairlistCpu *nbl, int icluster, int firstCell, int lastCell, bool excludeSubDiagonal, const real *gmx_restrict x_j, real rlist2, float rbb2, int *gmx_restrict numDistanceChecks) | ||
| SIMD code for checking and adding cluster-pairs to the list using the 2xMM layout. More... | |||
| static bool | supportsDynamicPairlistGenerationInterval (const t_inputrec &ir) | ||
| Returns if we can (heuristically) change nstlist and rlist. More... | |||
| static real | getPressureTolerance (const real inputrecVerletBufferPressureTolerance) | ||
| Returns the Verlet buffer pressure tolerance set by an env.var. or from input. | |||
| void | increaseNstlist (FILE *fplog, const MpiComm &mpiCommSimulation, t_inputrec *ir, int nstlistOnCmdline, const gmx_mtop_t *mtop, const matrix box, real effectiveAtomDensity, bool useOrEmulateGpuForNonbondeds) | ||
| Try to increase nstlist when using the Verlet cut-off scheme. More... | |||
| static real | calcPruneVerletBufferSize (const CalcVerletBufferParameters ¶ms, const int nstlist) | ||
| Wrapper for calcVerletBufferSize() for determining the pruning cut-off. More... | |||
| static void | setDynamicPairlistPruningParameters (const t_inputrec &inputrec, const gmx_mtop_t &mtop, const real effectiveAtomDensity, const bool useGpuList, const VerletbufListSetup &listSetup, const bool userSetNstlistPrune, const interaction_const_t &interactionConst, PairlistParams *listParams) | ||
Set the dynamic pairlist pruning parameters in ic. More... | |||
| static std::string | formatListSetup (const std::string &listName, int nstList, int nstListForSpacing, real rList, real interactionCutoff) | ||
| Returns a string describing the setup of a single pair-list. More... | |||
| void | setupDynamicPairlistPruning (const MDLogger &mdlog, const t_inputrec &inputrec, const gmx_mtop_t &mtop, real effectiveAtomDensity, const interaction_const_t &interactionConst, PairlistParams *listParams) | ||
| Set up the dynamic pairlist pruning. More... | |||
| void | printNbnxmPressureError (const MDLogger &mdlog, const t_inputrec &inputrec, const gmx_mtop_t &mtop, real effectiveAtomDensity, const PairlistParams &listParams) | ||
| Prints an estimate of the error in the pressure due to missing interactions. More... | |||
| template<int nR, KernelLayout kernelLayout> | |||
| std::array< std::array < SimdBool, nR > , kernelLayoutClusterRatio < kernelLayout > )==KernelLayoutClusterRatio::JSizeEqualsISize?1:2 > | generateDiagonalMasks (const nbnxn_atomdata_t::SimdMasks &simdMasks) | ||
| Returns the diagonal filter masks. | |||
| template<int nR, bool maskInteractions, std::size_t inputSize, std::size_t interactSize> | |||
| void | rInvSixAndRInvTwelve (const std::array< SimdReal, inputSize > &rInvSquaredV, const std::array< SimdBool, interactSize > &interactV, std::array< SimdReal, nR > &rInvSixV, std::array< SimdReal, nR > &rInvTwelveV) | ||
| Computes r^-6 and r^-12, masked when requested. | |||
| template<int nR, bool maskInteractions, bool haveCutoffCheck, bool calculateEnergies, std::size_t inputSize, std::size_t interactSize, std::size_t vljvSize> | |||
| void | lennardJonesInteractionsSigmaEpsilon (const std::array< SimdReal, inputSize > &rInvV, const std::array< SimdBool, interactSize > &interactV, const SimdBool *const withinCutoffV, const std::array< SimdReal, nR > &sigmaV, const std::array< SimdReal, nR > &epsilonV, const SimdReal dispersionShift, const SimdReal repulsionShift, const SimdReal sixth, const SimdReal twelfth, std::array< SimdReal, nR > &frLJV, std::array< SimdReal, vljvSize > &vLJV) | ||
| Returns F*r and optionally the potential for LJ with (un)shifted potential with sigma/epsilon. | |||
| template<int nR, std::size_t inputSize> | |||
| void | computeForceSwitchVariables (const std::array< SimdReal, inputSize > &rSquaredV, const std::array< SimdReal, inputSize > &rInvV, SimdReal rSwitch, std::array< SimdReal, nR > &rSwitchedV, std::array< SimdReal, nR > &rSwitchedSquaredV, std::array< SimdReal, nR > &rSwitchedSquaredTimesRV) | ||
| Computes (r - r_switch), (r - r_switch)^2 and (r - r_switch)^2 * r. | |||
| SimdReal | addLJForceSwitch (SimdReal force, SimdReal rSwitched, SimdReal rSwitchedSquaredTimesR, SimdReal c2, SimdReal c3) | ||
Adds the force switch term to force. | |||
| SimdReal | ljForceSwitchPotential (SimdReal rSwitched, SimdReal rSwitchedSquaredTimesR, SimdReal c0, SimdReal c3, SimdReal c4) | ||
| Returns the LJ force switch function for the potential. | |||
| template<int nR, std::size_t inputSize> | |||
| void | computePotentialSwitchVariables (const std::array< SimdReal, inputSize > &rSquaredV, const std::array< SimdReal, inputSize > &rInvV, SimdReal rSwitch, std::array< SimdReal, nR > &rSwitchedV, std::array< SimdReal, nR > &rSwitchedSquaredV) | ||
| Computes (r - r_switch) and (r - r_switch)^2. | |||
| SimdReal | potentialSwitchFunction (SimdReal rsw, SimdReal rsw2, SimdReal c3, SimdReal c4, SimdReal c5) | ||
| Returns the potential switch function. | |||
| SimdReal | potentialSwitchFunctionDerivative (SimdReal rsw, SimdReal rsw2, SimdReal c2, SimdReal c3, SimdReal c4) | ||
| Returns the derivative of the potential switch function. | |||
| template<int nR, bool maskInteractions, bool calculateEnergies, std::size_t inputSize, std::size_t interactSize, std::size_t ljepSize, std::size_t vljvSize> | |||
| void | addLennardJonesEwaldCorrections (const std::array< SimdReal, inputSize > &rSquaredV, const std::array< SimdReal, inputSize > &rInvSquaredV, const std::array< SimdBool, interactSize > &interactV, const SimdBool *withinCutoffV, const std::array< SimdReal, nR > &c6GridV, const std::array< SimdReal, ljepSize > &ljEwaldParams, SimdReal sixth, std::array< SimdReal, nR > &frLJV, std::array< SimdReal, vljvSize > &vLJV) | ||
| Adds the Ewald long-range correction for r^-6. | |||
| template<KernelLayoutClusterRatio clusterRatio> | |||
| static int | cjFromCi (const int iCluster) | ||
| Returns the j-cluster index for the given i-cluster index. More... | |||
| template<KernelLayout kernelLayout> | |||
| std::enable_if_t< kernelLayout==KernelLayout::r4xM, SimdReal > | loadIAtomData (const real *ptr, const int offset, const int iRegister) | ||
Load a single real for an i-atom into iRegister. | |||
| template<KernelLayout kernelLayout> | |||
| std::enable_if_t< kernelLayout==KernelLayout::r2xMM, SimdReal > | loadIAtomData (const real *ptr, const int offset, const int iRegister) | ||
Load a pair of consecutive reals for two i-atom into the respective halves of iRegister. | |||
| template<KernelLayout kernelLayout> | |||
| std::enable_if_t< kernelLayout==KernelLayout::r4xM, SimdReal > | loadJAtomData (const real *ptr, const int offset) | ||
| Returns a SIMD register containing GMX_SIMD_REAL_WIDTH reals loaded from ptr + offset. | |||
| template<KernelLayout kernelLayout> | |||
| std::enable_if_t< kernelLayout==KernelLayout::r2xMM, SimdReal > | loadJAtomData (const real *ptr, const int offset) | ||
| Returns a SIMD register containing a duplicate sequence of GMX_SIMD_REAL_WIDTH/2 reals loaded from ptr + offset. | |||
| template<bool loadMasks, KernelLayout kernelLayout> | |||
| std::enable_if_t<!loadMasks, std::array< SimdBool, 0 > > | loadSimdPairInteractionMasks (const int excl, SimdBitMask *filterBitMasksV) | ||
| Loads no interaction masks, returns an empty array. | |||
| template<bool loadMasks, KernelLayout kernelLayout> | |||
| std::enable_if_t< loadMasks &&kernelLayout==KernelLayout::r4xM, std::array< SimdBool, sc_iClusterSize(kernelLayout)> > | loadSimdPairInteractionMasks (const int excl, SimdBitMask *filterBitMasksV) | ||
| Loads interaction masks for a cluster pair for 4xM kernel layout. | |||
| template<bool loadMasks, KernelLayout kernelLayout> | |||
| std::enable_if_t< loadMasks &&kernelLayout==KernelLayout::r2xMM, std::array< SimdBool, sc_iClusterSize(kernelLayout)/2 > > | loadSimdPairInteractionMasks (const int excl, SimdBitMask *filterBitMasksV) | ||
| Loads interaction masks for a cluster pair for 2xMM kernel layout. | |||
| template<int nR> | |||
| int | pairCountWithinCutoff (SimdReal rSquaredV[nR], SimdReal cutoffSquared) | ||
| Return the number of atoms pairs that are within the cut-off distance. | |||
| template<KernelLayout kernelLayout> | |||
| void | nbnxmSimdPruneKernel (NbnxnPairlistCpu *nbl, const nbnxn_atomdata_t &nbat, ArrayRef< const RVec > shiftvec, real rlistInner) | ||
| Prune a single NbnxnPairlistCpu entry with distance rlistInner. | |||
| static auto | nbnxmKernelTransformXToXq (Float4 *__restrict__ gm_xq, const Float3 *__restrict__ gm_x, const int *__restrict__ gm_atomIndex, const int *__restrict__ gm_numAtoms, const int *__restrict__ gm_cellIndex, int cellOffset, int numAtomsPerCell, int columnsOffset) | ||
| SYCL kernel for transforming position coordinates from rvec to nbnxm layout. More... | |||
| static void | launchSciSortOnGpu (GpuPairlist *plist, const int maxWorkGroupSize, const DeviceStream &deviceStream) | ||
| template<int workGroupSize, int nElements> | |||
| static auto | nbnxnKernelExclusivePrefixSum (const int *__restrict__ gm_input, int *__restrict__ gm_output) | ||
| SYCL exclusive prefix sum kernel for list sorting. More... | |||
| static auto | nbnxnKernelBucketSciSort (const nbnxn_sci_t *__restrict__ gm_sci, const int *__restrict__ gm_sciCount, int *__restrict__ gm_sciOffset, nbnxn_sci_t *__restrict__ gm_sciSorted) | ||
| SYCL bucket sci sort kernel. More... | |||
| template<int workGroupSize> | |||
| static void | launchPrefixSumKernel (sycl::queue &q, GpuPairlistSorting *sorting) | ||
| static void | launchBucketSortKernel (sycl::queue &q, GpuPairlist *plist) | ||
| static int | getNbnxmSubGroupSize (const DeviceInformation &deviceInfo, PairlistType layoutType) | ||
| constexpr bool | c_avoidFloatingPointAtomics (PairlistType layoutType) | ||
| Should we avoid FP atomics to the same location from the same work-group? More... | |||
| static void | reduceForceJShuffle (Float3 f, const sycl::nd_item< 3 > &itemIdx, const int tidxi, const int aidx, sycl::global_ptr< Float3 > a_f) | ||
| Reduce c_clSize j-force components using shifts and atomically accumulate into a_f. More... | |||
| template<int subGroupSize, int groupSize> | |||
| static float | groupReduce (const sycl::nd_item< 3 > itemIdx, const unsigned int tidxi, sycl::local_ptr< float > sm_buf, float valueToReduce) | ||
Do workgroup-level reduction of a single float. More... | |||
| static void | reduceForceJGeneric (sycl::local_ptr< float > sm_buf, Float3 f, const sycl::nd_item< 3 > &itemIdx, const int tidxi, const int tidxj, const int aidx, sycl::global_ptr< Float3 > a_f) | ||
| Reduce c_clSize j-force components using local memory and atomically accumulate into a_f. More... | |||
| template<bool useShuffleReduction> | |||
| static void | reduceForceJ (sycl::local_ptr< float > sm_buf, Float3 f, const sycl::nd_item< 3 > itemIdx, const int tidxi, const int tidxj, const int aidx, sycl::global_ptr< Float3 > a_f) | ||
| Reduce c_clSize j-force components using either shifts or local memory and atomically accumulate into a_f. | |||
| template<typename FCiBufferWrapperX , typename FCiBufferWrapperY , typename FCiBufferWrapperZ > | |||
| static void | reduceForceIAndFShiftGeneric (sycl::local_ptr< float > sm_buf, const FCiBufferWrapperX &fCiBufX, const FCiBufferWrapperY &fCiBufY, const FCiBufferWrapperZ &fCiBufZ, const bool calcFShift, const sycl::nd_item< 3 > itemIdx, const int tidxi, const int tidxj, const int sci, const int shift, sycl::global_ptr< Float3 > a_f, sycl::global_ptr< Float3 > a_fShift) | ||
| Local memory-based i-force reduction. More... | |||
| template<int numShuffleReductionSteps, typename FCiBufferWrapperX , typename FCiBufferWrapperY , typename FCiBufferWrapperZ > | |||
| static std::enable_if_t < numShuffleReductionSteps!=1, void > | reduceForceIAndFShiftShuffles (const FCiBufferWrapperX &fCiBufX, const FCiBufferWrapperY &fCiBufY, const FCiBufferWrapperZ &fCiBufZ, const bool calcFShift, const sycl::nd_item< 3 > itemIdx, const int tidxi, const int tidxj, const int sci, const int shift, sycl::global_ptr< Float3 > a_f, sycl::global_ptr< Float3 > a_fShift) | ||
| Shuffle-based i-force reduction. More... | |||
| template<int numShuffleReductionSteps, typename FCiBufferWrapperX , typename FCiBufferWrapperY , typename FCiBufferWrapperZ > | |||
| static std::enable_if_t < numShuffleReductionSteps==1, void > | reduceForceIAndFShiftShuffles (const FCiBufferWrapperX &fCiBufX, const FCiBufferWrapperY &fCiBufY, const FCiBufferWrapperZ &fCiBufZ, const bool calcFShift, const sycl::nd_item< 3 > itemIdx, const int tidxi, const int tidxj, const int sci, const int shift, sycl::global_ptr< Float3 > a_f, sycl::global_ptr< Float3 > a_fShift) | ||
reduceForceIAndFShiftShuffles specialization for single-step reduction (e.g., Intel iGPUs). More... | |||
| template<bool useShuffleReduction, int subGroupSize, typename FCiBufferWrapperX , typename FCiBufferWrapperY , typename FCiBufferWrapperZ > | |||
| static void | reduceForceIAndFShift (sycl::local_ptr< float > sm_buf, const FCiBufferWrapperX &fCiBufX, const FCiBufferWrapperY &fCiBufY, const FCiBufferWrapperZ &fCiBufZ, const bool calcFShift, const sycl::nd_item< 3 > itemIdx, const int tidxi, const int tidxj, const int sci, const int shift, sycl::global_ptr< Float3 > a_f, sycl::global_ptr< Float3 > a_fShift) | ||
| Final i-force reduction. More... | |||
| template<int subGroupSize, bool doPruneNBL, bool doCalcEnergies, enum ElecType elecType, enum VdwType vdwType> | |||
| static auto | nbnxmKernel (sycl::handler &cgh, const Float4 *__restrict__ gm_xq, Float3 *__restrict__ gm_f, const Float3 *__restrict__ gm_shiftVec, Float3 *__restrict__ gm_fShift, float *__restrict__ gm_energyElec, float *__restrict__ gm_energyVdw, nbnxn_cj_packed_t *__restrict__ gm_plistCJPacked, const nbnxn_sci_t *__restrict__ gm_plistSci, const nbnxn_excl_t *__restrict__ gm_plistExcl, const Float2 *__restrict__ gm_ljComb, const int *__restrict__ gm_atomTypes, const Float2 *__restrict__ gm_nbfp, const Float2 *__restrict__ gm_nbfpComb, const float *__restrict__ gm_coulombTab, int *__restrict__ gm_sciHistogram, int *__restrict__ gm_sciCount, const int numTypes, const float rCoulombSq, const float rVdwSq, const float twoKRf, const float ewaldBeta, const float rlistOuterSq, const float ewaldShift, const float epsFac, const float ewaldCoeffLJ_2, const float cRF, const shift_consts_t dispersionShift, const shift_consts_t repulsionShift, const switch_consts_t vdwSwitch, const float rVdwSwitch, const float ljEwaldShift, const float coulombTabScale, const bool calcShift) | ||
| Main kernel for NBNXM. More... | |||
| template<int subGroupSize, bool doPruneNBL, bool doCalcEnergies, enum ElecType elecType, enum VdwType vdwType, class... Args> | |||
| static void | launchNbnxmKernel (const DeviceStream &deviceStream, const int numSci, Args &&...args) | ||
| NBNXM kernel launch code. | |||
| template<int subGroupSize, bool doPruneNBL, bool doCalcEnergies, class... Args> | |||
| void | chooseAndLaunchNbnxmKernel (enum ElecType elecType, enum VdwType vdwType, Args &&...args) | ||
| Select templated kernel and launch it. | |||
| template<bool haveFreshList, PairlistType layoutType> | |||
| auto | nbnxmKernelPruneOnly (sycl::handler &cgh, const int numSci, const int numParts, const Float4 *__restrict__ gm_xq, const Float3 *__restrict__ gm_shiftVec, nbnxn_cj_packed_t *__restrict__ gm_plistCJPacked, const nbnxn_sci_t *__restrict__ gm_plistSci, unsigned int *__restrict__ gm_plistIMask, int *__restrict__ gm_rollingPruningPart, int *__restrict__ gm_sciHistogram, int *__restrict__ gm_sciCount, const float rlistOuterSq, const float rlistInnerSq) | ||
| Prune-only kernel for NBNXM. More... | |||
| template<bool haveFreshList, PairlistType layoutType, class... Args> | |||
| void | launchNbnxmKernelPruneOnly (const DeviceStream &deviceStream, const int numSciInPartMax, Args &&...args) | ||
| Leap Frog SYCL prune-only kernel launch code. | |||
| template<PairlistType layoutType, class... Args> | |||
| void | chooseAndLaunchNbnxmKernelPruneOnly (bool haveFreshList, Args &&...args) | ||
| Select templated kernel and launch it. | |||
| void | launchNbnxmKernelPruneOnly (NbnxmGpu *nb, const InteractionLocality iloc, const int numParts, const int numSciInPartMax) | ||
| Launch SYCL NBNXM prune-only kernel. More... | |||
| static constexpr unsigned | sc_superClInteractionMask (const PairlistType layoutType) | ||
| void | assignOptionsFromKeyValueTree (Options *options, const KeyValueTreeObject &tree, IKeyValueTreeErrorHandler *errorHandler) | ||
| Assigns option values from a given KeyValueTreeObject. More... | |||
| void | checkForUnknownOptionsInKeyValueTree (const KeyValueTreeObject &tree, const Options &options) | ||
| Checks that a given KeyValueTreeObject can be assigned to given Options. More... | |||
| KeyValueTreeObject | adjustKeyValueTreeFromOptions (const KeyValueTreeObject &tree, const Options &options) | ||
| Adjusts a KeyValueTreeObject to the structure of given Options. More... | |||
| bool | boxesAreEqual (const matrix box1, const matrix box2) | ||
| Returns whether two boxes are of equal size and shape (within reasonable tolerance). | |||
| bool | boxIsZero (const matrix box) | ||
| Returns whether a box is only initialised to zero or not. | |||
| void | shiftAtoms (const RVec &shift, ArrayRef< RVec > x) | ||
| Shift all coordinates. More... | |||
| void | placeCoordinatesWithCOMInBox (const PbcType &pbcType, UnitCellType unitCellType, CenteringType centerType, const matrix box, ArrayRef< RVec > x, const gmx_mtop_t &mtop, COMShiftType comShiftType) | ||
| Moves collection of atoms along the center of mass into a box. More... | |||
| static IVec | shiftIndexToXYZ (int shiftIndex) | ||
| Convert shift index to periodic cell shifts. | |||
| static int | xyzToShiftIndex (int x, int y, int z) | ||
| Convert grid coordinates to shift index. | |||
| static int | ivecToShiftIndex (const gmx::IVec &iv) | ||
| Convert grid coordinates to shift index. | |||
| static int | ivecToShiftIndex (ivec iv) | ||
| Convert grid coordinates to shift index. | |||
| static int | shiftIndexToXDim (int iv) | ||
Return the shift in the X dimension of grid space corresponding to iv. | |||
| const char * | centerTypeNames (CenteringType type) | ||
| Get names for the different centering types. More... | |||
| const char * | unitCellTypeNames (UnitCellType type) | ||
| Get names for the different unit cell representation types. More... | |||
| double | getTransformationPullCoordinateValue (pull_coord_work_t *coord, ArrayRef< const pull_coord_work_t > variableCoords, double t) | ||
| Calculates pull->coord[coord_ind].spatialData.value for a transformation pull coordinate. More... | |||
| static double | computeDerivativeForTransformationPullCoord (pull_coord_work_t *coord, const int variablePcrdIndex) | ||
| Calculates and returns the derivative of a transformation pull coordinate from a dependent coordinate. More... | |||
| void | distributeTransformationPullCoordForce (pull_coord_work_t *pcrd, gmx::ArrayRef< pull_coord_work_t > variableCoords) | ||
| Distributes the force on a transformation pull coordinates to the involved coordinates of lower rank. More... | |||
| static bool | checkIfRandomDeviceIsFunctional () | ||
| Check if the RDRAND random device functioning correctly. More... | |||
| template<typename GeneratorType > | |||
| static uint64_t | makeRandomSeedInternal (GeneratorType &gen) | ||
| Get the next pure or pseudo-random number. More... | |||
| uint64_t | makeRandomSeed () | ||
| Return 64 random bits from the random device, suitable as seed. More... | |||
| template<class RealType = real, unsigned int Bits, class Rng > | |||
| RealType | generateCanonical (Rng &g) | ||
| Generate a floating-point value with specified number of random bits. More... | |||
| void | compileSelection (SelectionCollection *coll) | ||
| void | swap (SelectionCollection &lhs, SelectionCollection &rhs) noexcept | ||
| HelpTopicPointer | createSelectionHelpTopic () | ||
| */ More... | |||
| void | serializeKeyValueTree (const KeyValueTreeObject &root, ISerializer *serializer) | ||
| Serializes a KeyValueTreeObject with given serializer. | |||
| KeyValueTreeObject | deserializeKeyValueTree (ISerializer *serializer) | ||
| Deserializes a KeyValueTreeObject from a given serializer. | |||
| static void gmx_unused | simdPrefetch (void gmx_unused *m) | ||
| Prefetch memory at address m. More... | |||
| static void | store (float *m, float a) | ||
| Store contents of float variable to aligned memory m. More... | |||
| static void | storeU (float *m, float a) | ||
| Store contents of float variable to unaligned memory m. More... | |||
| static float | fma (float a, float b, float c) | ||
| Float Fused-multiply-add. Result is a*b + c. More... | |||
| static float | fms (float a, float b, float c) | ||
| Float Fused-multiply-subtract. Result is a*b - c. More... | |||
| static float | fnma (float a, float b, float c) | ||
| Float Fused-negated-multiply-add. Result is -a*b + c. More... | |||
| static float | fnms (float a, float b, float c) | ||
| Float Fused-negated-multiply-subtract. Result is -a*b - c. More... | |||
| static float | maskAdd (float a, float b, float m) | ||
| Add two float variables, masked version. More... | |||
| static float | maskzMul (float a, float b, float m) | ||
| Multiply two float variables, masked version. More... | |||
| static float | maskzFma (float a, float b, float c, float m) | ||
| Float fused multiply-add, masked version. More... | |||
| static float gmx_simdcall | maskzRcp (float x, float m) | ||
| Float 1.0/x, masked version. More... | |||
| static float | abs (float a) | ||
| Float Floating-point abs(). More... | |||
| static float | max (float a, float b) | ||
| Set each float element to the largest from two variables. More... | |||
| static float | min (float a, float b) | ||
| Set each float element to the smallest from two variables. More... | |||
| static float | round (float a) | ||
| Float round to nearest integer value (in floating-point format). More... | |||
| static float | trunc (float a) | ||
| Truncate float, i.e. round towards zero - common hardware instruction. More... | |||
| static float | reduce (float a) | ||
| Return sum of all elements in float variable (i.e., the variable itself). More... | |||
| static float | andNot (float a, float b) | ||
| Bitwise andnot for two scalar float variables. More... | |||
| static bool | testBits (float a) | ||
| Return true if any bits are set in the float variable. More... | |||
| static bool | anyTrue (bool a) | ||
| Returns if the boolean is true. More... | |||
| static float | selectByMask (float a, bool mask) | ||
| Select from single precision variable where boolean is true. More... | |||
| static float | selectByNotMask (float a, bool mask) | ||
| Select from single precision variable where boolean is false. More... | |||
| static float | blend (float a, float b, bool sel) | ||
| Blend float selection. More... | |||
| static std::int32_t | cvtR2I (float a) | ||
| Round single precision floating point to integer. More... | |||
| static std::int32_t | cvttR2I (float a) | ||
| Truncate single precision floating point to integer. More... | |||
| static std::int32_t | cvtI2R (std::int32_t a) | ||
| Return integer. More... | |||
| static void | store (double *m, double a) | ||
| Store contents of double variable to aligned memory m. More... | |||
| static void | storeU (double *m, double a) | ||
| Store contents of double variable to unaligned memory m. More... | |||
| static double | fma (double a, double b, double c) | ||
| double Fused-multiply-add. Result is a*b + c. More... | |||
| static double | fms (double a, double b, double c) | ||
| double Fused-multiply-subtract. Result is a*b - c. More... | |||
| static double | fnma (double a, double b, double c) | ||
| double Fused-negated-multiply-add. Result is - a*b + c. More... | |||
| static double | fnms (double a, double b, double c) | ||
| double Fused-negated-multiply-subtract. Result is -a*b - c. More... | |||
| static double | maskAdd (double a, double b, double m) | ||
| Add two double variables, masked version. More... | |||
| static double | maskzMul (double a, double b, double m) | ||
| Multiply two double variables, masked version. More... | |||
| static double | maskzFma (double a, double b, double c, double m) | ||
| double fused multiply-add, masked version. More... | |||
| static double gmx_simdcall | maskzRcp (double x, double m) | ||
| Double 1.0/x, masked version. More... | |||
| static double | abs (double a) | ||
| double doubleing-point abs(). More... | |||
| static double | max (double a, double b) | ||
| Set each double element to the largest from two variables. More... | |||
| static double | min (double a, double b) | ||
| Set each double element to the smallest from two variables. More... | |||
| static double | round (double a) | ||
| double round to nearest integer value (in doubleing-point format). More... | |||
| static double | trunc (double a) | ||
| Truncate double, i.e. round towards zero - common hardware instruction. More... | |||
| static double | reduce (double a) | ||
| Return sum of all elements in double variable (i.e., the variable itself). More... | |||
| static double | andNot (double a, double b) | ||
| Bitwise andnot for two scalar double variables. More... | |||
| static bool | testBits (double a) | ||
| Return true if any bits are set in the double variable. More... | |||
| static double | selectByMask (double a, bool mask) | ||
| Select from double precision variable where boolean is true. More... | |||
| static double | selectByNotMask (double a, bool mask) | ||
| Select from double precision variable where boolean is false. More... | |||
| static double | blend (double a, double b, bool sel) | ||
| Blend double selection. More... | |||
| static std::int32_t | cvtR2I (double a) | ||
| Round single precision doubleing point to integer. More... | |||
| static std::int32_t | cvttR2I (double a) | ||
| Truncate single precision doubleing point to integer. More... | |||
| static double | cvtF2D (float a) | ||
| Convert float to double (mimicks SIMD conversion) More... | |||
| static float | cvtD2F (double a) | ||
| Convert double to float (mimicks SIMD conversion) More... | |||
| static void | store (std::int32_t *m, std::int32_t a) | ||
| Store contents of integer variable to aligned memory m. More... | |||
| static void | storeU (std::int32_t *m, std::int32_t a) | ||
| Store contents of integer variable to unaligned memory m. More... | |||
| static std::int32_t | andNot (std::int32_t a, std::int32_t b) | ||
| Bitwise andnot for two scalar integer variables. More... | |||
| static bool | testBits (std::int32_t a) | ||
| Return true if any bits are set in the integer variable. More... | |||
| static std::int32_t | selectByMask (std::int32_t a, bool mask) | ||
| Select from integer variable where boolean is true. More... | |||
| static std::int32_t | selectByNotMask (std::int32_t a, bool mask) | ||
| Select from integer variable where boolean is false. More... | |||
| static std::int32_t | blend (std::int32_t a, std::int32_t b, bool sel) | ||
| Blend integer selection. More... | |||
| static bool | cvtB2IB (bool a) | ||
| Just return a boolean (mimicks SIMD real-to-int bool conversions) More... | |||
| static bool | cvtIB2B (bool a) | ||
| Just return a boolean (mimicks SIMD int-to-real bool conversions) More... | |||
| static float | copysign (float x, float y) | ||
| Composes single value with the magnitude of x and the sign of y. More... | |||
| static void | invsqrtPair (float x0, float x1, float *out0, float *out1) | ||
| Calculate 1/sqrt(x) for two floats. More... | |||
| static float | inv (float x) | ||
| Calculate 1/x for float. More... | |||
| static float | maskzInvsqrt (float x, bool m) | ||
| Calculate 1/sqrt(x) for masked entry of float. More... | |||
| static float | maskzInv (float x, bool m) | ||
| Calculate 1/x for masked entry of float. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static float | sqrt (float x) | ||
| Float sqrt(x). This is the square root. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static float | cbrt (float x) | ||
| Float cbrt(x). This is the cubic root. More... | |||
| static float | log (float x) | ||
| Float log(x). This is the natural logarithm. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static float | exp2 (float x) | ||
| Float 2^x. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static float | exp (float x) | ||
| Float exp(x). More... | |||
| static float | erf (float x) | ||
| Float erf(x). More... | |||
| static float | erfc (float x) | ||
| Float erfc(x). More... | |||
| static void | sincos (float x, float *sinval, float *cosval) | ||
| Float sin & cos. More... | |||
| static float | sin (float x) | ||
| Float sin. More... | |||
| static float | cos (float x) | ||
| Float cos. More... | |||
| static float | tan (float x) | ||
| Float tan. More... | |||
| static float | asin (float x) | ||
| float asin. More... | |||
| static float | acos (float x) | ||
| Float acos. More... | |||
| static float | atan (float x) | ||
| Float atan. More... | |||
| static float | atan2 (float y, float x) | ||
| Float atan2(y,x). More... | |||
| static float | pmeForceCorrection (float z2) | ||
| Calculate the force correction due to PME analytically in float. More... | |||
| static float | pmePotentialCorrection (float z2) | ||
| Calculate the potential correction due to PME analytically in float. More... | |||
| static double | copysign (double x, double y) | ||
| Composes double value with the magnitude of x and the sign of y. More... | |||
| static void | invsqrtPair (double x0, double x1, double *out0, double *out1) | ||
| Calculate 1/sqrt(x) for two doubles. More... | |||
| static double | inv (double x) | ||
| Calculate 1/x for double. More... | |||
| static double | maskzInvsqrt (double x, bool m) | ||
| Calculate 1/sqrt(x) for masked entry of double. More... | |||
| static double | maskzInv (double x, bool m) | ||
| Calculate 1/x for masked entry of double. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static double | sqrt (double x) | ||
| Double sqrt(x). This is the square root. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static double | cbrt (double x) | ||
| Double cbrt(x). This is the cubic root. More... | |||
| static double | log (double x) | ||
| Double log(x). This is the natural logarithm. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static double | exp2 (double x) | ||
| Double 2^x. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static double | exp (double x) | ||
| Double exp(x). More... | |||
| static double | erf (double x) | ||
| Double erf(x). More... | |||
| static double | erfc (double x) | ||
| Double erfc(x). More... | |||
| static void | sincos (double x, double *sinval, double *cosval) | ||
| Double sin & cos. More... | |||
| static double | sin (double x) | ||
| Double sin. More... | |||
| static double | cos (double x) | ||
| Double cos. More... | |||
| static double | tan (double x) | ||
| Double tan. More... | |||
| static double | asin (double x) | ||
| Double asin. More... | |||
| static double | acos (double x) | ||
| Double acos. More... | |||
| static double | atan (double x) | ||
| Double atan. More... | |||
| static double | atan2 (double y, double x) | ||
| Double atan2(y,x). More... | |||
| static double | pmeForceCorrection (double z2) | ||
| Calculate the force correction due to PME analytically in double. More... | |||
| static double | pmePotentialCorrection (double z2) | ||
| Calculate the potential correction due to PME analytically in double. More... | |||
| static double | invsqrtSingleAccuracy (double x) | ||
| Calculate 1/sqrt(x) for double, but with single accuracy. More... | |||
| static void | invsqrtPairSingleAccuracy (double x0, double x1, double *out0, double *out1) | ||
| Calculate 1/sqrt(x) for two doubles, but with single accuracy. More... | |||
| static double | invSingleAccuracy (double x) | ||
| Calculate 1/x for double, but with single accuracy. More... | |||
| static double | maskzInvsqrtSingleAccuracy (double x, bool m) | ||
| Calculate 1/sqrt(x) for masked entry of double, but with single accuracy. More... | |||
| static double | maskzInvSingleAccuracy (double x, bool m) | ||
| Calculate 1/x for masked entry of double, but with single accuracy. More... | |||
| static double | sqrtSingleAccuracy (double x) | ||
| Calculate sqrt(x) for double, but with single accuracy. More... | |||
| static double | logSingleAccuracy (double x) | ||
| Double log(x), but with single accuracy. This is the natural logarithm. More... | |||
| static double | exp2SingleAccuracy (double x) | ||
| Double 2^x, but with single accuracy. More... | |||
| static double | expSingleAccuracy (double x) | ||
| Double exp(x), but with single accuracy. More... | |||
| static double | erfSingleAccuracy (double x) | ||
| Double erf(x), but with single accuracy. More... | |||
| static double | erfcSingleAccuracy (double x) | ||
| Double erfc(x), but with single accuracy. More... | |||
| static void | sincosSingleAccuracy (double x, double *sinval, double *cosval) | ||
| Double sin & cos, but with single accuracy. More... | |||
| static double | sinSingleAccuracy (double x) | ||
| Double sin, but with single accuracy. More... | |||
| static double | cosSingleAccuracy (double x) | ||
| Double cos, but with single accuracy. More... | |||
| static double | tanSingleAccuracy (double x) | ||
| Double tan, but with single accuracy. More... | |||
| static double | asinSingleAccuracy (double x) | ||
| Double asin, but with single accuracy. More... | |||
| static double | acosSingleAccuracy (double x) | ||
| Double acos, but with single accuracy. More... | |||
| static double | atanSingleAccuracy (double x) | ||
| Double atan, but with single accuracy. More... | |||
| static double | atan2SingleAccuracy (double y, double x) | ||
| Double atan2(y,x), but with single accuracy. More... | |||
| static double | pmeForceCorrectionSingleAccuracy (double z2) | ||
| Force correction due to PME in double, but with single accuracy. More... | |||
| static double | pmePotentialCorrectionSingleAccuracy (double z2) | ||
| Potential correction due to PME in double, but with single accuracy. More... | |||
| template<int align> | |||
| static void | gatherLoadTranspose (const float *base, const std::int32_t offset[], float *v0, float *v1, float *v2, float *v3) | ||
| Load 4 consecutive floats from base/offset into four variables. More... | |||
| template<int align> | |||
| static void | gatherLoadTranspose (const float *base, const std::int32_t offset[], float *v0, float *v1) | ||
| Load 2 consecutive floats from base/offset into four variables. More... | |||
| template<int align> | |||
| static void | gatherLoadUTranspose (const float *base, const std::int32_t offset[], float *v0, float *v1, float *v2) | ||
| Load 3 consecutive floats from base/offsets, store into three vars. More... | |||
| template<int align> | |||
| static void | transposeScatterStoreU (float *base, const std::int32_t offset[], float v0, float v1, float v2) | ||
| Store 3 floats to 3 to base/offset. More... | |||
| template<int align> | |||
| static void | transposeScatterIncrU (float *base, const std::int32_t offset[], float v0, float v1, float v2) | ||
| Add 3 floats to base/offset. More... | |||
| template<int align> | |||
| static void | transposeScatterDecrU (float *base, const std::int32_t offset[], float v0, float v1, float v2) | ||
| Subtract 3 floats from base/offset. More... | |||
| static void | expandScalarsToTriplets (float scalar, float *triplets0, float *triplets1, float *triplets2) | ||
| Copy single float to three variables. More... | |||
| template<int align> | |||
| static void | gatherLoadBySimdIntTranspose (const float *base, std::int32_t offset, float *v0, float *v1, float *v2, float *v3) | ||
| Load 4 floats from base/offsets and store into variables. More... | |||
| template<int align> | |||
| static void | gatherLoadUBySimdIntTranspose (const float *base, std::int32_t offset, float *v0, float *v1) | ||
| Load 2 floats from base/offsets and store into variables (unaligned). More... | |||
| template<int align> | |||
| static void | gatherLoadBySimdIntTranspose (const float *base, std::int32_t offset, float *v0, float *v1) | ||
| Load 2 floats from base/offsets and store into variables (aligned). More... | |||
| static float | reduceIncr4ReturnSum (float *m, float v0, float v1, float v2, float v3) | ||
| Add each float to four consecutive memory locations, return sum. More... | |||
| template<int align> | |||
| static void | gatherLoadTranspose (const double *base, const std::int32_t offset[], double *v0, double *v1, double *v2, double *v3) | ||
| Load 4 consecutive doubles from base/offset into four variables. More... | |||
| template<int align> | |||
| static void | gatherLoadTranspose (const double *base, const std::int32_t offset[], double *v0, double *v1) | ||
| Load 2 consecutive doubles from base/offset into four variables. More... | |||
| template<int align> | |||
| static void | gatherLoadUTranspose (const double *base, const std::int32_t offset[], double *v0, double *v1, double *v2) | ||
| Load 3 consecutive doubles from base/offsets, store into three vars. More... | |||
| template<int align> | |||
| static void | transposeScatterStoreU (double *base, const std::int32_t offset[], double v0, double v1, double v2) | ||
| Store 3 doubles to 3 to base/offset. More... | |||
| template<int align> | |||
| static void | transposeScatterIncrU (double *base, const std::int32_t offset[], double v0, double v1, double v2) | ||
| Add 3 doubles to base/offset. More... | |||
| template<int align> | |||
| static void | transposeScatterDecrU (double *base, const std::int32_t offset[], double v0, double v1, double v2) | ||
| Subtract 3 doubles from base/offset. More... | |||
| static void | expandScalarsToTriplets (double scalar, double *triplets0, double *triplets1, double *triplets2) | ||
| Copy single double to three variables. More... | |||
| template<int align> | |||
| static void | gatherLoadBySimdIntTranspose (const double *base, std::int32_t offset, double *v0, double *v1, double *v2, double *v3) | ||
| Load 4 doubles from base/offsets and store into variables. More... | |||
| template<int align> | |||
| static void | gatherLoadUBySimdIntTranspose (const double *base, std::int32_t offset, double *v0, double *v1) | ||
| Load 2 doubles from base/offsets and store into variables (unaligned). More... | |||
| template<int align> | |||
| static void | gatherLoadBySimdIntTranspose (const double *base, std::int32_t offset, double *v0, double *v1) | ||
| Load 2 doubles from base/offsets and store into variables (aligned). More... | |||
| static double | reduceIncr4ReturnSum (double *m, double v0, double v1, double v2, double v3) | ||
| Add each double to four consecutive memory locations, return sum. More... | |||
| bool | decideWhetherToUseGpusForNonbondedWithThreadMpi (TaskTarget nonbondedTarget, bool haveAvailableDevices, const std::vector< int > &userGpuTaskAssignment, EmulateGpuNonbonded emulateGpuNonbonded, bool canUseNonbondedOnGpu, bool binaryReproducibilityRequested, int numRanksPerSimulation) | ||
| Decide whether this thread-MPI simulation will run nonbonded tasks on GPUs. More... | |||
| static bool | decideWhetherToUseGpusForPmeFft (const TaskTarget pmeFftTarget) | ||
| bool | canUseGpusForNonbonded (const t_inputrec &ir, const bool doRerun, std::string *error) | ||
| static bool | canUseGpusForPme (const bool useGpuForNonbonded, const TaskTarget pmeTarget, const TaskTarget pmeFftTarget, const t_inputrec &inputrec, std::string *errorMessage) | ||
| bool | decideWhetherToUseGpusForPmeWithThreadMpi (bool useGpuForNonbonded, TaskTarget pmeTarget, TaskTarget pmeFftTarget, int numDevicesToUse, const std::vector< int > &userGpuTaskAssignment, const t_inputrec &inputrec, int numRanksPerSimulation, int numPmeRanksPerSimulation) | ||
| Decide whether this thread-MPI simulation will run PME tasks on GPUs. More... | |||
| bool | decideWhetherToUseGpusForNonbonded (TaskTarget nonbondedTarget, const std::vector< int > &userGpuTaskAssignment, EmulateGpuNonbonded emulateGpuNonbonded, bool canUseNonbondedOnGpu, bool binaryReproducibilityRequested, bool gpusWereDetected) | ||
| Decide whether the simulation will try to run nonbonded tasks on GPUs. More... | |||
| bool | decideWhetherToUseGpusForNonbondedFE (bool useGpuForNonbonded, TaskTarget nonBondedFeTarget) | ||
| Decide whether the simulation will try to run nonbonde FE tasks on GPUs. More... | |||
| bool | decideWhetherToUseGpusForPme (bool useGpuForNonbonded, TaskTarget pmeTarget, TaskTarget pmeFftTarget, const std::vector< int > &userGpuTaskAssignment, const t_inputrec &inputrec, int numRanksPerSimulation, int numPmeRanksPerSimulation, bool gpusWereDetected) | ||
| Decide whether the simulation will try to run tasks of different types on GPUs. More... | |||
| PmeRunMode | determinePmeRunMode (bool useGpuForPme, const TaskTarget &pmeFftTarget, const t_inputrec &inputrec) | ||
| Determine PME run mode. More... | |||
| bool | decideWhetherToUseGpusForBonded (bool useGpuForNonbonded, bool useGpuForPme, TaskTarget bondedTarget, const t_inputrec &inputrec, const gmx_mtop_t &mtop, int numPmeRanksPerSimulation, bool gpusWereDetected) | ||
| Decide whether the simulation will try to run bonded tasks on GPUs. More... | |||
| bool | decideWhetherToUseGpuForUpdate (bool isDomainDecomposition, bool useUpdateGroups, PmeRunMode pmeRunMode, bool havePmeOnlyRank, bool useGpuForNonbonded, TaskTarget updateTarget, bool gpusWereDetected, const t_inputrec &inputrec, const gmx_mtop_t &mtop, bool useEssentialDynamics, bool doOrientationRestraints, bool haveFrozenAtoms, bool useModularSimulator, bool doRerun, const gmx::MDLogger &mdlog) | ||
| Decide whether to use GPU for update. More... | |||
| bool | decideWhetherDirectGpuCommunicationCanBeUsed (gmx::GpuAwareMpiStatus mpiStatus, bool haveMts, bool useReplicaExchange, bool haveSwapCoords, bool gpusWereDetected, const gmx::MDLogger &mdlog) | ||
| Decide whether direct GPU communication can be used. More... | |||
| bool | decideWhetherToUseGpuForHalo (bool havePPDomainDecomposition, bool useGpuForNonbonded, bool canUseDirectGpuComm, bool useModularSimulator, bool doRerun, bool haveEnergyMinimization, const gmx::MDLogger &mdlog) | ||
| Decide whether to use GPU for halo exchange. More... | |||
| SimulationWorkload | createSimulationWorkload (const gmx::MDLogger &mdlog, const t_inputrec &inputrec, bool haveDynamicBox, bool useReplicaExchange, bool disableNonbondedCalculation, const DevelopmentFeatureFlags &devFlags, bool haveFillerParticlesInLocalState, bool havePpDomainDecomposition, bool haveSeparatePmeRank, bool useGpuForNonbonded, bool useGpuForNonbondedFE, PmeRunMode pmeRunMode, bool useGpuForBonded, bool useGpuForUpdate, bool useGpuDirectHalo, bool canUseDirectGpuComm, bool useGpuPmeDecomposition) | ||
| Build datastructure that contains decisions whether to run different workload task on GPUs. More... | |||
| static bool | haveSpecialForces (const t_inputrec &inputrec, const gmx::ForceProviders &forceProviders, const pull_t *pull_work, const gmx_edsam *ed) | ||
| Return true if there are special forces computed. More... | |||
| DomainLifetimeWorkload | setupDomainLifetimeWorkload (const t_inputrec &inputrec, const t_forcerec &fr, const pull_t *pull_work, const gmx_edsam *ed, const t_mdatoms &mdatoms, const SimulationWorkload &simulationWork) | ||
| Set up workload flags that have the lifetime of the PP domain decomposition. More... | |||
| StepWorkload | setupStepWorkload (const int legacyFlags, ArrayRef< const gmx::MtsLevel > mtsLevels, const int64_t step, const DomainLifetimeWorkload &domainWork, const SimulationWorkload &simulationWork) | ||
| Set up force flag struct from the force bitmask. More... | |||
| std::vector< GpuTask > | findGpuTasksOnThisRank (bool haveGpusOnThisPhysicalNode, TaskTarget nonbondedTarget, TaskTarget nonbondedFeTarget, TaskTarget pmeTarget, TaskTarget bondedTarget, TaskTarget updateTarget, bool useGpuForNonbonded, bool useGpuForPme, bool rankHasPpTask, bool rankHasPmeTask) | ||
| Returns container of all tasks on this rank that are eligible for GPU execution. More... | |||
| GpuTasksOnRanks | findAllGpuTasksOnThisNode (ArrayRef< const GpuTask > gpuTasksOnThisRank, const PhysicalNodeCommunicator &physicalNodeComm) | ||
| Returns container of all tasks on all ranks of this node that are eligible for GPU execution. More... | |||
| void | checkHardwareOversubscription (int numThreadsOnThisRank, int rank, const HardwareTopology &hwTop, const PhysicalNodeCommunicator &comm, const MDLogger &mdlog) | ||
| Warns for oversubscribing the hardware threads, when that is the case. | |||
| void | setThrowForPerformanceProblems (bool newValue) | ||
| Flag for controlling behaviour in cases where performance might be low. More... | |||
| std::vector< int > | parseUserGpuIdString (const std::string &gpuIdString) | ||
| Parse a GPU ID specifier string into a container describing device IDs exposed to the run. More... | |||
| std::vector< int > | makeListOfAvailableDevices (gmx::ArrayRef< const std::unique_ptr< DeviceInformation >> deviceInfoList, const std::string &devicesSelectedByUserString) | ||
| Implement GPU ID selection by returning the available GPU IDs on this physical node that are compatible. More... | |||
| std::vector< int > | parseUserTaskAssignmentString (const std::string &gpuIdString) | ||
| Parse a GPU ID specifier string into a container describing device ID to task mapping. More... | |||
| std::vector< int > | makeGpuIds (ArrayRef< const int > compatibleGpus, size_t numGpuTasks) | ||
Make a vector containing numGpuTasks IDs of the IDs found in compatibleGpus. More... | |||
| std::string | makeGpuIdString (const std::vector< int > &gpuIds, int totalNumberOfTasks) | ||
| Convert a container of GPU deviced IDs to a string that can be used by gmx tune_pme as input to mdrun -gputasks. More... | |||
| void | checkUserGpuIds (ArrayRef< const std::unique_ptr< DeviceInformation >> deviceInfoList, ArrayRef< const int > compatibleGpus, ArrayRef< const int > gpuIds) | ||
| Check that all user-selected GPUs are compatible. More... | |||
| void | reportGpuUsage (const MDLogger &mdlog, ArrayRef< const GpuTaskAssignment > gpuTaskAssignmentOnRanksOfThisNode, size_t numGpuTasksOnThisNode, size_t numPpRanks, bool printHostName, PmeRunMode pmeRunMode, const SimulationWorkload &simulationWork) | ||
| Log a report on how GPUs are being used on the ranks of the physical node of rank 0 of the simulation. More... | |||
| template<GpuTask TaskType> | |||
| static bool | hasTaskType (const GpuTaskMapping &mapping) | ||
Function for whether the task of mapping has value TaskType. More... | |||
| static bool | hasPmeOrNonbondedTask (const GpuTaskMapping &mapping) | ||
Function for whether the mapping has the GPU PME or Nonbonded task. More... | |||
| static std::vector< int > | parseGpuDeviceIdentifierList (const std::string &gpuIdString) | ||
| Parse a GPU ID specifier string into a container. More... | |||
| void | resumeIttTracingWhenAppropriate () | ||
| Resume tracing when applicable. More... | |||
| std::optional< std::string > | rdtscpDescription () | ||
| When targeting x86, returns whether RDTSCP support is present. | |||
| std::optional< std::string > | instrumentationApiDescription () | ||
| Returns information for describing a possible profiling/instrumentation API. | |||
| void | writeHeader (TextWriter *writer, const std::string &text, const std::string §ion, bool writeFormattedText) | ||
| Write appropiate Header to output stream. More... | |||
| void | writeSystemInformation (TextWriter *writer, const gmx_mtop_t &top, bool writeFormattedText) | ||
| Write information about the molecules in the system. More... | |||
| void | writeParameterInformation (TextWriter *writer, const t_inputrec &ir, bool writeFormattedText) | ||
| Write information about system parameters. More... | |||
| void | writeInformation (TextOutputFile *outputStream, const t_inputrec &ir, const gmx_mtop_t &top, bool writeFormattedText, bool notStdout) | ||
| Wrapper for writing out information. More... | |||
| static bool | isEmbeddedAtom (Index globalAtomIndex, const std::set< int > &embeddedIndices) | ||
| std::vector< bool > | splitEmbeddedBlocks (gmx_mtop_t *mtop, const std::set< int > &embeddedIndices) | ||
| Splits embedded atom containing molecules out of MM blocks in topology. More... | |||
| std::vector< real > | removeEmbeddedClassicalCharges (gmx_mtop_t *mtop, const std::set< int > &embeddedIndices, const std::vector< bool > &isEmbeddedBlock, real refQ, const MDLogger &logger, WarningHandler *wi) | ||
| Removes classical charges from embedded atoms and virtual sites. More... | |||
| void | addEmbeddedNBExclusions (gmx_mtop_t *mtop, const std::set< int > &embeddedIndices, const MDLogger &logger) | ||
| Build exclusion list for non-bonded interactions between embedded atoms. More... | |||
| std::vector< int > | buildEmbeddedAtomNumbers (const gmx_mtop_t &mtop) | ||
Builds and returns a vector of atom numbers for all atoms in mtop. More... | |||
| void | modifyEmbeddedTwoCenterInteractions (gmx_mtop_t *mtop, const std::set< int > &embeddedIndices, const std::vector< bool > &isEmbeddedBlock, const MDLogger &logger) | ||
| Modifies pairwise bonded interactions. More... | |||
| std::vector< LinkFrontierAtom > | buildLinkFrontier (gmx_mtop_t *mtop, const std::set< int > &embeddedIndices, const std::vector< bool > &isEmbeddedBlock, const MDLogger &logger) | ||
| Builds link frontier vector with pairs of atoms indicting broken embedded - MM chemical bonds. More... | |||
| void | modifyEmbeddedThreeCenterInteractions (gmx_mtop_t *mtop, const std::set< int > &embeddedIndices, const std::vector< bool > &isEmbeddedBlock, const MDLogger &logger) | ||
| Modifies three-centers interactions (i.e. Angles, Settles) More... | |||
| void | modifyEmbeddedFourCenterInteractions (gmx_mtop_t *mtop, const std::set< int > &embeddedIndices, const std::vector< bool > &isEmbeddedBlock, const MDLogger &logger) | ||
| Modifies four-centers interactions. More... | |||
| void | checkConstrainedBonds (gmx_mtop_t *mtop, const std::set< int > &embeddedIndices, const std::vector< bool > &isEmbeddedBlock, WarningHandler *wi) | ||
| Checks for constrained bonds within embedded subsystem. More... | |||
| void | blockaToExclusionBlocks (const t_blocka *b, gmx::ArrayRef< ExclusionBlock > b2) | ||
| Convert the exclusions. More... | |||
| void | exclusionBlocksToBlocka (gmx::ArrayRef< const ExclusionBlock > b2, t_blocka *b) | ||
Convert the exclusions expressed in b into t_blocka form. | |||
| void | mergeExclusions (ListOfLists< int > *excl, gmx::ArrayRef< ExclusionBlock > b2) | ||
Merge the contents of b2 into excl. More... | |||
| Isotope | getIsotopeFromString (const std::string &isotope) | ||
| Convert isotope name from string to enum. | |||
| std::vector< Isotope > | getIsotopes (const t_atoms *atoms) | ||
| Reads element list and returns vector of isotopes. | |||
|
std::vector < AtomicStructureFactor > | readAtomicStructureFactors () | ||
| Helper function to read in atomic scattering data from file. | |||
| void | registerTrajectoryAnalysisModules (CommandLineModuleManager *manager) | ||
| Registers all trajectory analysis command-line modules. More... | |||
| gmx_rmpbc_t | gmx_rmpbc_init (const gmx::TopologyInformation &topInfo) | ||
| Convenience overload useful for implementing legacy tools. | |||
| static std::size_t | getPageSize () | ||
| Return a page size, from a sysconf/WinAPI query if available, or a default guess (4096 bytes). More... | |||
| std::string | simpleValueToString (const Any &value) | ||
| Converts a Any value to a string. More... | |||
|
std::unordered_map < std::string, std::string > | versionDescriptions () | ||
| Returns information for describing the GROMACS version. | |||
| ArrayRef< bool > | makeArrayRef (std::vector< BoolType > &boolVector) | ||
| Create ArrayRef to bool from reference to std::vector<BoolType>. More... | |||
| ArrayRef< const bool > | makeConstArrayRef (const std::vector< BoolType > &boolVector) | ||
| Create ArrayRef to const bool from reference to std::vector<BoolType>. More... | |||
| std::string | bromacs () | ||
| Return a cool definition for the acronym GROMACS. | |||
| std::string | getCoolQuote () | ||
| Return a string with a cool quote. | |||
| const char * | getErrorCodeString (int errorcode) | ||
| Returns a short string description of an error code. More... | |||
| void | printFatalErrorMessage (FILE *fp, const std::exception &ex) | ||
| Formats a standard fatal error message for reporting an exception. More... | |||
| std::string | formatExceptionMessageToString (const std::exception &ex) | ||
| Formats an error message for reporting an exception. More... | |||
| void | formatExceptionMessageToFile (FILE *fp, const std::exception &ex) | ||
| Formats an error message for reporting an exception. More... | |||
| void | formatExceptionMessageToWriter (TextWriter *writer, const std::exception &ex) | ||
| Formats an error message for reporting an exception. More... | |||
| int | processExceptionAtExit (const std::exception &ex) | ||
| Handles an exception that is causing the program to terminate. More... | |||
| void | processExceptionAsFatalError (const std::exception &ex) | ||
| Helper function for terminating the program on an exception. More... | |||
| IFileInputRedirector & | defaultFileInputRedirector () | ||
| Returns default implementation for IFileInputRedirector. More... | |||
| IFileOutputRedirector & | defaultFileOutputRedirector () | ||
| Returns default implementation for IFileOutputRedirector. More... | |||
| const DataFileFinder & | getLibraryFileFinder () | ||
| Gets a finder for locating data files from share/top/. More... | |||
| void | setLibraryFileFinder (const DataFileFinder *finder) | ||
| Sets a finder for location data files from share/top/. More... | |||
| std::filesystem::path | findLibraryFile (const std::filesystem::path &filename, bool bAddCWD=true, bool bFatal=true) | ||
| Finds full path for a library file. More... | |||
| FilePtr | openLibraryFile (const std::filesystem::path &filename, bool bAddCWD=true, bool bFatal=true) | ||
Opens a library file for reading in an RAII-style FILE handle. More... | |||
| std::string | openmpDescription () | ||
| Returns information for describing the OpenMP support. | |||
| IKeyValueTreeErrorHandler * | defaultKeyValueTreeErrorHandler () | ||
| Returns a default IKeyValueTreeErrorHandler that throws on first exception. | |||
| std::size_t | pageSize () | ||
| Return the memory page size on this system. More... | |||
| template<class T1 , class Policy1 , class T2 , class Policy2 > | |||
| bool | operator== (const Allocator< T1, Policy1 > &a, const Allocator< T2, Policy2 > &b) | ||
| Return true if two allocators are identical. More... | |||
| template<class T1 , class Policy1 , class T2 , class Policy2 > | |||
| bool | operator!= (const Allocator< T1, Policy1 > &a, const Allocator< T2, Policy2 > &b) | ||
| Return true if two allocators are different. | |||
| template<typename Callable > | |||
| auto | coordinateExceptionHandling (MPI_Comm communicator, Callable callable) -> typename std::invoke_result_t< Callable > | ||
Call the callable and then make sure all MPI ranks of communicator have consistent exception-throwing behaviour. More... | |||
| void | init (int *argc, char ***argv) | ||
| Initializes the GROMACS library. More... | |||
| void | finalize () | ||
| Deinitializes the GROMACS library. More... | |||
| KeyValueTreePath | operator+ (const KeyValueTreePath &a, const KeyValueTreePath &b) | ||
| Combines two paths as with KeyValueTreePath::append(). | |||
| KeyValueTreePath | operator+ (const KeyValueTreePath &a, const std::string &b) | ||
| Combines an element to a path as with KeyValueTreePath::append(). | |||
| void | dumpKeyValueTree (TextWriter *writer, const KeyValueTreeObject &tree) | ||
| Writes a human-readable representation of the tree with given writer. More... | |||
| void | compareKeyValueTrees (TextWriter *writer, const KeyValueTreeObject &tree1, const KeyValueTreeObject &tree2, real ftol, real abstol) | ||
| Compares two KeyValueTrees and prints any differences. | |||
| static std::string | simpleValueToString (const KeyValueTreeValue &value) | ||
| Helper function to format a simple KeyValueTreeValue. | |||
| void | writeKeyValueTreeAsMdp (TextWriter *writer, const KeyValueTreeObject &tree) | ||
Write a flat key-value tree to writer in mdp style. More... | |||
| const char * | enumValueToString (GpuAwareMpiStatus status) | ||
| Helper function to pretty-print GPU-aware status values. | |||
| bool | usingIntelMpi () | ||
| Return whether GROMACS is linked against an MPI library describing itself as Intel MPI. | |||
| GpuAwareMpiStatus | checkMpiCudaAwareSupport () | ||
Wrapper on top of MPIX_Query_cuda_support() For MPI implementations which don't support this function, it returns NotSupported. Even when an MPI implementation does support this function, MPI library might not be robust enough to detect CUDA-aware support at runtime correctly e.g. when UCX PML is used or CUDA is disabled at runtime. More... | |||
| GpuAwareMpiStatus | checkMpiHipAwareSupport () | ||
Wrapper on top of MPIX_Query_hip_support() or MPIX_Query_rocm_support(). For MPI implementations which don't support this function, it returns NotSupported. More... | |||
| GpuAwareMpiStatus | checkMpiZEAwareSupport () | ||
Wrapper on top of MPIX_Query_ze_support() (for MPICH) or custom logic (for IntelMPI). More... | |||
|
std::unordered_map < std::string, std::string > | mpiDescriptions () | ||
| Returns information for describing the MPI support. | |||
| void | niceHeader (TextWriter *writer, const char *fn, char commentChar) | ||
| Prints creation time stamp and user information into a string as comments, and returns it. More... | |||
| std::vector < std::filesystem::path > | splitPathEnvironment (const std::string &pathEnv) | ||
| Split PATH environment variable into search paths. More... | |||
|
std::vector < std::filesystem::path > | getSystemExecutablePaths () | ||
| Get collection of possible executable paths. | |||
| std::string | stripSourcePrefix (const char *path) | ||
| Strip source prefix from path. | |||
| std::filesystem::path | concatenateBeforeExtension (const std::filesystem::path &path, const std::string &addition) | ||
| Concatenate before extension. | |||
| std::filesystem::path | stripExtension (const std::filesystem::path &path) | ||
| Remove extension from file path. | |||
| bool | extensionMatches (const std::filesystem::path &path, std::string_view extension) | ||
Check if file extension of path without final '.' matches extension. | |||
| void | MPI_Comm_free_wrapper (MPI_Comm *comm) | ||
| Wrapper function for RAII-style cleanup. More... | |||
| bool | boolFromString (const char *str) | ||
| Parses a boolean from a string. More... | |||
| int | intFromString (const char *str) | ||
| Parses an integer from a string. More... | |||
| unsigned int | uintFromString (const char *str) | ||
| Parses an unsigned integer from a string. More... | |||
| int64_t | int64FromString (const char *str) | ||
| Parses a 64-bit integer from a string. More... | |||
| uint64_t | uint64FromString (const char *str) | ||
| Parses a 64-bit unsigned integer from a string. More... | |||
| float | floatFromString (const char *str) | ||
| Parses a float value from a string. More... | |||
| double | doubleFromString (const char *str) | ||
| Parses a double value from a string. More... | |||
| template<typename T > | |||
| static T | fromString (const char *str) | ||
| Parses a value from a string to a given type. More... | |||
| template<typename T > | |||
| static T | fromString (const std::string &str) | ||
| Parses a value from a string to a given type. More... | |||
| template<typename T > | |||
| static T | fromStdString (const std::string &str) | ||
| Parses a value from a string to a given type. More... | |||
| template<> | |||
| bool | fromString< bool > (const char *str) | ||
| Implementation for boolean values. | |||
| template<> | |||
| int | fromString< int > (const char *str) | ||
| Implementation for integer values. | |||
| template<> | |||
| unsigned int | fromString< unsigned int > (const char *str) | ||
| Implementation for unsigned integer values. | |||
| template<> | |||
| int64_t | fromString< int64_t > (const char *str) | ||
| Implementation for 64-bit integer values. | |||
| template<> | |||
| uint64_t | fromString< uint64_t > (const char *str) | ||
| Implementation for 64-bit unsigned integer values. | |||
| template<> | |||
| float | fromString< float > (const char *str) | ||
| Implementation for float values. | |||
| template<> | |||
| double | fromString< double > (const char *str) | ||
| Implementation for double values. | |||
| static const char * | boolToString (bool value) | ||
| Converts a boolean to a "true"/"false" string. More... | |||
| static std::string | intToString (int t) | ||
Returns a string containing the value of t. More... | |||
| static std::string | uintToString (unsigned int t) | ||
Returns a string containing the value of t. More... | |||
| static std::string | int64ToString (int64_t t) | ||
Returns a string containing the value of t. More... | |||
| static std::string | uint64ToString (uint64_t t) | ||
Returns a string containing the value of t. More... | |||
| static std::string | doubleToString (double t) | ||
Returns a string containing the value of t. More... | |||
| static std::string | unsignedCharToString (unsigned char t) | ||
Returns a string containing the value of t. More... | |||
| template<typename ValueType , int NumExpectedValues> | |||
| static std::optional < std::array< ValueType, NumExpectedValues > > | parsedArrayFromInputString (const std::string &str) | ||
| Convert a string into an array of values. More... | |||
| template<typename ValueType , int NumExpectedValues> | |||
| static std::string | stringIdentityTransformWithArrayCheck (const std::string &toConvert, const std::string &errorContextMessage) | ||
| Returns the input string, throwing an exception if the demanded conversion to an array will not succeed. More... | |||
| template<class Function > | |||
| auto | dispatchTemplatedFunction (Function &&f) | ||
| bool | checkIfAvailable (TextWriter *writer, const char *description, const void *p) | ||
Returns true if p is non-null, otherwise prints a message to writer and returns false. | |||
| void | printTitleAndSize (TextWriter *writer, const char *title, const int n) | ||
Prints a title from the description and number of values n. | |||
| const IProgramContext & | getProgramContext () | ||
| Returns the global IProgramContext instance. More... | |||
| void | setProgramContext (const IProgramContext *context) | ||
| Sets the global IProgramContext instance. More... | |||
| std::size_t | countWords (const char *s) | ||
| Returns number of space-separated words in zero-terminated char ptr. More... | |||
| std::size_t | countWords (const std::string &str) | ||
| Returns the number of space-separated words in a string object. More... | |||
| bool | endsWith (const char *str, const char *suffix) | ||
| Tests whether a string ends with another string. More... | |||
| std::string | stripSuffixIfPresent (const std::string &str, const char *suffix) | ||
| Removes a suffix from a string. More... | |||
| std::string | stripString (const std::string &str) | ||
| Removes leading and trailing whitespace from a string. More... | |||
| std::string | formatString (gmx_fmtstr const char *fmt,...) | ||
| std::string | formatStringV (const char *fmt, std::va_list ap) | ||
| Formats a string (vsnprintf() wrapper). More... | |||
| std::vector< std::string > | splitString (const std::string &str) | ||
| Splits a string to whitespace separated tokens. More... | |||
| std::vector< std::string > | splitDelimitedString (const std::string &str, char delim) | ||
| Splits a string to tokens separated by a given delimiter. More... | |||
| std::vector< std::string > | splitAndTrimDelimitedString (const std::string &str, char delim) | ||
Splits str to tokens separated by delimiter delim. Removes leading and trailing whitespace from those strings with std::isspace. More... | |||
| std::string | replaceAll (const std::string &input, const char *from, const char *to) | ||
| Replace all occurrences of a string with another string. More... | |||
| std::string | replaceAll (const std::string &input, const std::string &from, const std::string &to) | ||
| Replace all occurrences of a string with another string. More... | |||
| std::string | replaceAllWords (const std::string &input, const char *from, const char *to) | ||
| Replace whole words with others. More... | |||
| std::string | replaceAllWords (const std::string &input, const std::string &from, const std::string &to) | ||
| Replace whole words with others. More... | |||
| bool | equalCaseInsensitive (const std::string &source, const std::string &target) | ||
| Return whether two strings are equal, ignoring case. More... | |||
| bool | equalIgnoreDash (const std::string &source, const std::string &target) | ||
| Return whether too strings are case sensitive equal, ignoring dashes. | |||
| bool | equalCaseInsensitive (const std::string &source, const std::string &target, size_t maxLengthOfComparison) | ||
Checks if at most maxLengthOfComparison characters of two strings match case insensitive. More... | |||
| std::string | toUpperCase (const std::string &text) | ||
| Makes the string uppercase. More... | |||
| std::string | toLowerCase (const std::string &text) | ||
| Makes the string lowercase. More... | |||
| std::string | prettyPrintListAsRange (ArrayRef< const int > list) | ||
| Formats a range of integers using taskset-style notation when possible. More... | |||
| int | gmx_mdrun (int argc, char *argv[]) | ||
| Implements C-style main function for mdrun. More... | |||
| int | gmx_mdrun (MPI_Comm communicator, const gmx_hw_info_t &hwinfo, int argc, char *argv[]) | ||
| Implements C-style main function for mdrun. More... | |||
| AnalysisHistogramSettingsInitializer | histogramFromRange (real min, real max) | ||
| Initializes a histogram using a range and a bin width. More... | |||
| AnalysisHistogramSettingsInitializer | histogramFromBins (real start, size_t nbins, real binwidth) | ||
| Initializes a histogram using bin width and the number of bins. More... | |||
| static float | invsqrt (float x) | ||
| Calculate 1.0/sqrt(x) in single precision. More... | |||
| static double | invsqrt (double x) | ||
| Calculate 1.0/sqrt(x) in double precision, but single range. More... | |||
| static double | invsqrt (int x) | ||
| Calculate 1.0/sqrt(x) for integer x in double precision. More... | |||
| static float | invcbrt (float x) | ||
| Calculate inverse cube root of x in single precision. More... | |||
| static double | invcbrt (double x) | ||
| Calculate inverse sixth root of x in double precision. More... | |||
| static double | invcbrt (int x) | ||
| Calculate inverse sixth root of integer x in double precision. More... | |||
| static float | sixthroot (float x) | ||
| Calculate sixth root of x in single precision. More... | |||
| static double | sixthroot (double x) | ||
| Calculate sixth root of x in double precision. More... | |||
| static double | sixthroot (int x) | ||
| Calculate sixth root of integer x, return double. More... | |||
| static float | invsixthroot (float x) | ||
| Calculate inverse sixth root of x in single precision. More... | |||
| static double | invsixthroot (double x) | ||
| Calculate inverse sixth root of x in double precision. More... | |||
| static double | invsixthroot (int x) | ||
| Calculate inverse sixth root of integer x in double precision. More... | |||
| template<typename T > | |||
| T | square (T x) | ||
| calculate x^2 More... | |||
| template<typename T > | |||
| T | power3 (T x) | ||
| calculate x^3 More... | |||
| template<typename T > | |||
| T | power4 (T x) | ||
| calculate x^4 More... | |||
| template<typename T > | |||
| T | power5 (T x) | ||
| calculate x^5 More... | |||
| template<typename T > | |||
| T | power6 (T x) | ||
| calculate x^6 More... | |||
| template<typename T > | |||
| T | power12 (T x) | ||
| calculate x^12 More... | |||
| static real | series_sinhx (real x) | ||
| Maclaurin series for sinh(x)/x. More... | |||
| constexpr int32_t | exactDiv (int32_t a, int32_t b) | ||
| Exact integer division, 32bit. More... | |||
| constexpr int64_t | exactDiv (int64_t a, int64_t b) | ||
| Exact integer division, 64bit. | |||
| static int | roundToInt (float x) | ||
| Round float to int. More... | |||
| static int | roundToInt (double x) | ||
| Round double to int. | |||
| static int64_t | roundToInt64 (float x) | ||
| Round float to int64_t. | |||
| static int64_t | roundToInt64 (double x) | ||
| Round double to int64_t. | |||
| template<typename T , typename = std::enable_if_t<std::is_integral_v<T>>> | |||
| static constexpr bool | isPowerOfTwo (const T v) | ||
Check whether v is an integer power of 2. | |||
| template<typename T > | |||
| constexpr T | divideRoundUp (T numerator, T denominator) | ||
Return numerator divided by denominator rounded up to the next integer. More... | |||
| template<typename T > | |||
| T | makePeriodic (const T x, const T period) | ||
Return x modulo period such that it is within the interval [-0.5*period, 0.5*period]. More... | |||
| template<typename T > | |||
| ArrayRef< std::conditional_t < std::is_const_v< T >, const typename T::value_type, typename T::value_type > > | makeArrayRef (T &c) | ||
| Create ArrayRef from container with type deduction. More... | |||
| template<typename T > | |||
| ArrayRef< const typename T::value_type > | makeConstArrayRef (const T &c) | ||
| Create ArrayRef to const T from container with type deduction. More... | |||
| template<typename T > | |||
| void | swap (ArrayRef< T > &a, ArrayRef< T > &b) noexcept | ||
| Simple swap method for ArrayRef objects. More... | |||
| template<typename T > | |||
| std::vector< T > | copyOf (const ArrayRef< const T > &arrayRef) | ||
| Return a vector that is a copy of an ArrayRef. More... | |||
| template<typename T > | |||
| Index | ssize (const T &t) | ||
| Return signed size of container. | |||
| template<typename EnumerationArrayType > | |||
| EnumerationArrayType::EnumerationWrapperType | keysOf (const EnumerationArrayType &) | ||
Returns an object that provides iterators over the keys associated with EnumerationArrayType. More... | |||
| template<class Exception , class Tag , class T > | |||
| std::enable_if_t < std::is_base_of_v < GromacsException, Exception > , Exception > | operator<< (Exception ex, const ExceptionInfo< Tag, T > &item) | ||
| Associates extra information with an exception. More... | |||
| void | fclose_wrapper (FILE *fp) | ||
| fclose wrapper to be used as unique_ptr deleter | |||
| static bool | isNullOrEmpty (const char *str) | ||
| Tests whether a string is null or empty. More... | |||
| static bool | startsWith (const std::string &str, const std::string &prefix) | ||
| Tests whether a string starts with another string. More... | |||
| static bool | startsWith (const char *str, const char *prefix) | ||
| Tests whether a string starts with another string. More... | |||
| static bool | endsWith (const std::string &str, const char *suffix) | ||
| Tests whether a string ends with another string. More... | |||
| static bool | contains (const std::string &str, const char *substr) | ||
| Tests whether a string contains another as a substring. More... | |||
| static bool | contains (const std::string &str, const std::string &substr) | ||
| Tests whether a string contains another as a substring. More... | |||
| static bool | endsWith (const std::string &str, const std::string &suffix) | ||
| Tests whether a string ends with another string. More... | |||
| std::string | formatString (const char *fmt,...) | ||
| Formats a string (snprintf() wrapper). More... | |||
| template<typename InputIterator , typename FormatterType > | |||
| std::string | formatAndJoin (InputIterator begin, InputIterator end, const char *separator, const FormatterType &formatter) | ||
| Formats all the range as strings, and then joins them with a separator in between. More... | |||
| template<typename ContainerType , typename FormatterType > | |||
| std::string | formatAndJoin (const ContainerType &container, const char *separator, const FormatterType &formatter) | ||
| Formats all elements of the container as strings, and then joins them with a separator in between. More... | |||
| template<typename InputIterator > | |||
| std::string | joinStrings (InputIterator begin, InputIterator end, const char *separator) | ||
| Joins strings from a range with a separator in between. More... | |||
| template<typename ContainerType > | |||
| std::string | joinStrings (const ContainerType &container, const char *separator) | ||
| Joins strings from a container with a separator in between. More... | |||
| template<size_t count> | |||
| std::string | joinStrings (const char *const (&array)[count], const char *separator) | ||
| Joins strings from an array with a separator in between. More... | |||
| template<class T > | |||
| void | free_wrapper (T *p) | ||
| Wrapper of standard library free(), to be used as unique_cptr deleter for memory allocated by malloc, e.g. by an external library such as TNG. | |||
| template<class T > | |||
| void | sfree_wrapper (T *p) | ||
| sfree wrapper to be used as unique_cptr deleter | |||
| template<typename T , typename D > | |||
| std::unique_ptr< T, D > | create_unique_with_deleter (T *t, D d) | ||
| Create unique_ptr with any deleter function or lambda. | |||
| template<typename ValueType > | |||
| constexpr BasicVector< ValueType > | operator* (const BasicVector< ValueType > &basicVector, const ValueType &scalar) | ||
| Allow vector scalar multiplication. | |||
| template<typename ValueType > | |||
| constexpr BasicVector< ValueType > | operator* (const ValueType &scalar, const BasicVector< ValueType > &basicVector) | ||
| Allow scalar vector multiplication. | |||
| template<typename VectorType > | |||
| static constexpr VectorType | unitVector (const VectorType &v) | ||
| unitv for gmx::BasicVector | |||
| template<typename ValueType > | |||
| static constexpr ValueType | norm (BasicVector< ValueType > v) | ||
| norm for gmx::BasicVector | |||
| template<typename ValueType > | |||
| static constexpr ValueType | norm2 (BasicVector< ValueType > v) | ||
| Square of the vector norm for gmx::BasicVector. | |||
| template<typename VectorType > | |||
| static constexpr VectorType | cross (const VectorType &a, const VectorType &b) | ||
| cross product for gmx::BasicVector | |||
| template<typename ValueType > | |||
| static constexpr ValueType | dot (BasicVector< ValueType > a, BasicVector< ValueType > b) | ||
| dot product for gmx::BasicVector | |||
| template<typename VectorType > | |||
| static constexpr VectorType | scaleByVector (const VectorType &a, const VectorType &b) | ||
| Multiply two vectors element by element and return the result. | |||
| template<typename VectorType > | |||
| static constexpr VectorType | elementWiseMin (const VectorType &a, const VectorType &b) | ||
| Return the element-wise minimum of two vectors. | |||
| template<typename VectorType > | |||
| static constexpr VectorType | elementWiseMax (const VectorType &a, const VectorType &b) | ||
| Return the element-wise maximum of two vectors. | |||
| template<typename ValueType > | |||
| static BasicVector< ValueType > ::RawArray * | as_vec_array (BasicVector< ValueType > *x) | ||
| Casts a gmx::BasicVector array into an equivalent raw C array. | |||
| template<typename ValueType > | |||
| static const BasicVector < ValueType >::RawArray * | as_vec_array (const BasicVector< ValueType > *x) | ||
| Casts a gmx::BasicVector array into an equivalent raw C array. | |||
| static rvec * | as_rvec_array (RVec *x) | ||
Casts a gmx::RVec array into an rvec array. | |||
| static const rvec * | as_rvec_array (const RVec *x) | ||
Casts a gmx::RVec array into an rvec array. | |||
| static dvec * | as_dvec_array (DVec *x) | ||
Casts a gmx::DVec array into an Dvec array. | |||
| static ivec * | as_ivec_array (IVec *x) | ||
Casts a gmx::IVec array into an ivec array. | |||
| static const dvec * | as_dvec_array (const DVec *x) | ||
Casts a gmx::DVec array into an dvec array. | |||
| static const ivec * | as_ivec_array (const IVec *x) | ||
Casts a gmx::IVec array into an ivec array. | |||
| template<typename ValueType , std::enable_if_t< std::is_arithmetic_v< ValueType >, bool > = true> | |||
| static DataSetDims | getFrameDims (const DataSetDims &dataSetDims) | ||
| Return the frame dimensions for the data set dimensions. | |||
| void | applyGlobalSimulationState (const SimulationInput &simulationInput, PartialDeserializedTprFile *partialDeserializedTpr, t_state *globalState, t_inputrec *inputrec, gmx_mtop_t *globalTopology) | ||
| Get the global simulation input. More... | |||
| std::unique_ptr< t_state > | globalSimulationState (const SimulationInput &) | ||
| void | applyGlobalInputRecord (const SimulationInput &, t_inputrec *) | ||
| void | applyGlobalTopology (const SimulationInput &, gmx_mtop_t *) | ||
Constant width-4 double precision SIMD types and instructions | |||
| static Simd4Double gmx_simdcall | load4 (const double *m) | ||
| Load 4 double values from aligned memory into SIMD4 variable. More... | |||
| static void gmx_simdcall | store4 (double *m, Simd4Double a) | ||
| Store the contents of SIMD4 double to aligned memory m. More... | |||
| static Simd4Double gmx_simdcall | load4U (const double *m) | ||
| Load SIMD4 double from unaligned memory. More... | |||
| static void gmx_simdcall | store4U (double *m, Simd4Double a) | ||
| Store SIMD4 double to unaligned memory. More... | |||
| static Simd4Double gmx_simdcall | simd4SetZeroD () | ||
| Set all SIMD4 double elements to 0. More... | |||
| static Simd4Double gmx_simdcall | operator& (Simd4Double a, Simd4Double b) | ||
| Bitwise and for two SIMD4 double variables. More... | |||
| static Simd4Double gmx_simdcall | andNot (Simd4Double a, Simd4Double b) | ||
| Bitwise andnot for two SIMD4 double variables. c=(~a) & b. More... | |||
| static Simd4Double gmx_simdcall | operator| (Simd4Double a, Simd4Double b) | ||
| Bitwise or for two SIMD4 doubles. More... | |||
| static Simd4Double gmx_simdcall | operator^ (Simd4Double a, Simd4Double b) | ||
| Bitwise xor for two SIMD4 double variables. More... | |||
| static Simd4Double gmx_simdcall | operator+ (Simd4Double a, Simd4Double b) | ||
| Add two double SIMD4 variables. More... | |||
| static Simd4Double gmx_simdcall | operator- (Simd4Double a, Simd4Double b) | ||
| Subtract two SIMD4 variables. More... | |||
| static Simd4Double gmx_simdcall | operator- (Simd4Double a) | ||
| SIMD4 floating-point negate. More... | |||
| static Simd4Double gmx_simdcall | operator* (Simd4Double a, Simd4Double b) | ||
| Multiply two SIMD4 variables. More... | |||
| static Simd4Double gmx_simdcall | fma (Simd4Double a, Simd4Double b, Simd4Double c) | ||
| SIMD4 Fused-multiply-add. Result is a*b+c. More... | |||
| static Simd4Double gmx_simdcall | fms (Simd4Double a, Simd4Double b, Simd4Double c) | ||
| SIMD4 Fused-multiply-subtract. Result is a*b-c. More... | |||
| static Simd4Double gmx_simdcall | fnma (Simd4Double a, Simd4Double b, Simd4Double c) | ||
| SIMD4 Fused-negated-multiply-add. Result is -a*b+c. More... | |||
| static Simd4Double gmx_simdcall | fnms (Simd4Double a, Simd4Double b, Simd4Double c) | ||
| SIMD4 Fused-negated-multiply-subtract. Result is -a*b-c. More... | |||
| static Simd4Double gmx_simdcall | rsqrt (Simd4Double x) | ||
| SIMD4 1.0/sqrt(x) lookup. More... | |||
| static Simd4Double gmx_simdcall | abs (Simd4Double a) | ||
| SIMD4 Floating-point abs(). More... | |||
| static Simd4Double gmx_simdcall | max (Simd4Double a, Simd4Double b) | ||
| Set each SIMD4 element to the largest from two variables. More... | |||
| static Simd4Double gmx_simdcall | min (Simd4Double a, Simd4Double b) | ||
| Set each SIMD4 element to the largest from two variables. More... | |||
| static Simd4Double gmx_simdcall | round (Simd4Double a) | ||
| SIMD4 Round to nearest integer value (in floating-point format). More... | |||
| static Simd4Double gmx_simdcall | trunc (Simd4Double a) | ||
| Truncate SIMD4, i.e. round towards zero - common hardware instruction. More... | |||
| static double gmx_simdcall | dotProduct (Simd4Double a, Simd4Double b) | ||
| Return dot product of two double precision SIMD4 variables. More... | |||
| static void gmx_simdcall | transpose (Simd4Double *v0, Simd4Double *v1, Simd4Double *v2, Simd4Double *v3) | ||
| SIMD4 double transpose. More... | |||
| static Simd4DBool gmx_simdcall | operator== (Simd4Double a, Simd4Double b) | ||
| a==b for SIMD4 double More... | |||
| static Simd4DBool gmx_simdcall | operator!= (Simd4Double a, Simd4Double b) | ||
| a!=b for SIMD4 double More... | |||
| static Simd4DBool gmx_simdcall | operator< (Simd4Double a, Simd4Double b) | ||
| a<b for SIMD4 double More... | |||
| static Simd4DBool gmx_simdcall | operator<= (Simd4Double a, Simd4Double b) | ||
| a<=b for SIMD4 double. More... | |||
| static Simd4DBool gmx_simdcall | operator&& (Simd4DBool a, Simd4DBool b) | ||
| Logical and on single precision SIMD4 booleans. More... | |||
| static Simd4DBool gmx_simdcall | operator|| (Simd4DBool a, Simd4DBool b) | ||
| Logical or on single precision SIMD4 booleans. More... | |||
| static bool gmx_simdcall | anyTrue (Simd4DBool a) | ||
| Returns non-zero if any of the boolean in SIMD4 a is True, otherwise 0. More... | |||
| static Simd4Double gmx_simdcall | selectByMask (Simd4Double a, Simd4DBool mask) | ||
| Select from single precision SIMD4 variable where boolean is true. More... | |||
| static Simd4Double gmx_simdcall | selectByNotMask (Simd4Double a, Simd4DBool mask) | ||
| Select from single precision SIMD4 variable where boolean is false. More... | |||
| static Simd4Double gmx_simdcall | blend (Simd4Double a, Simd4Double b, Simd4DBool sel) | ||
| Vector-blend SIMD4 selection. More... | |||
| static double gmx_simdcall | reduce (Simd4Double a) | ||
| Return sum of all elements in SIMD4 double variable. More... | |||
Constant width-4 single precision SIMD types and instructions | |||
| static Simd4Float gmx_simdcall | load4 (const float *m) | ||
| Load 4 float values from aligned memory into SIMD4 variable. More... | |||
| static void gmx_simdcall | store4 (float *m, Simd4Float a) | ||
| Store the contents of SIMD4 float to aligned memory m. More... | |||
| static Simd4Float gmx_simdcall | load4U (const float *m) | ||
| Load SIMD4 float from unaligned memory. More... | |||
| static void gmx_simdcall | store4U (float *m, Simd4Float a) | ||
| Store SIMD4 float to unaligned memory. More... | |||
| static Simd4Float gmx_simdcall | simd4SetZeroF () | ||
| Set all SIMD4 float elements to 0. More... | |||
| static Simd4Float gmx_simdcall | operator& (Simd4Float a, Simd4Float b) | ||
| Bitwise and for two SIMD4 float variables. More... | |||
| static Simd4Float gmx_simdcall | andNot (Simd4Float a, Simd4Float b) | ||
| Bitwise andnot for two SIMD4 float variables. c=(~a) & b. More... | |||
| static Simd4Float gmx_simdcall | operator| (Simd4Float a, Simd4Float b) | ||
| Bitwise or for two SIMD4 floats. More... | |||
| static Simd4Float gmx_simdcall | operator^ (Simd4Float a, Simd4Float b) | ||
| Bitwise xor for two SIMD4 float variables. More... | |||
| static Simd4Float gmx_simdcall | operator+ (Simd4Float a, Simd4Float b) | ||
| Add two float SIMD4 variables. More... | |||
| static Simd4Float gmx_simdcall | operator- (Simd4Float a, Simd4Float b) | ||
| Subtract two SIMD4 variables. More... | |||
| static Simd4Float gmx_simdcall | operator- (Simd4Float a) | ||
| SIMD4 floating-point negate. More... | |||
| static Simd4Float gmx_simdcall | operator* (Simd4Float a, Simd4Float b) | ||
| Multiply two SIMD4 variables. More... | |||
| static Simd4Float gmx_simdcall | fma (Simd4Float a, Simd4Float b, Simd4Float c) | ||
| SIMD4 Fused-multiply-add. Result is a*b+c. More... | |||
| static Simd4Float gmx_simdcall | fms (Simd4Float a, Simd4Float b, Simd4Float c) | ||
| SIMD4 Fused-multiply-subtract. Result is a*b-c. More... | |||
| static Simd4Float gmx_simdcall | fnma (Simd4Float a, Simd4Float b, Simd4Float c) | ||
| SIMD4 Fused-negated-multiply-add. Result is -a*b+c. More... | |||
| static Simd4Float gmx_simdcall | fnms (Simd4Float a, Simd4Float b, Simd4Float c) | ||
| SIMD4 Fused-negated-multiply-subtract. Result is -a*b-c. More... | |||
| static Simd4Float gmx_simdcall | rsqrt (Simd4Float x) | ||
| SIMD4 1.0/sqrt(x) lookup. More... | |||
| static Simd4Float gmx_simdcall | abs (Simd4Float a) | ||
| SIMD4 Floating-point fabs(). More... | |||
| static Simd4Float gmx_simdcall | max (Simd4Float a, Simd4Float b) | ||
| Set each SIMD4 element to the largest from two variables. More... | |||
| static Simd4Float gmx_simdcall | min (Simd4Float a, Simd4Float b) | ||
| Set each SIMD4 element to the largest from two variables. More... | |||
| static Simd4Float gmx_simdcall | round (Simd4Float a) | ||
| SIMD4 Round to nearest integer value (in floating-point format). More... | |||
| static Simd4Float gmx_simdcall | trunc (Simd4Float a) | ||
| Truncate SIMD4, i.e. round towards zero - common hardware instruction. More... | |||
| static float gmx_simdcall | dotProduct (Simd4Float a, Simd4Float b) | ||
| Return dot product of two single precision SIMD4 variables. More... | |||
| static void gmx_simdcall | transpose (Simd4Float *v0, Simd4Float *v1, Simd4Float *v2, Simd4Float *v3) | ||
| SIMD4 float transpose. More... | |||
| static Simd4FBool gmx_simdcall | operator== (Simd4Float a, Simd4Float b) | ||
| a==b for SIMD4 float More... | |||
| static Simd4FBool gmx_simdcall | operator!= (Simd4Float a, Simd4Float b) | ||
| a!=b for SIMD4 float More... | |||
| static Simd4FBool gmx_simdcall | operator< (Simd4Float a, Simd4Float b) | ||
| a<b for SIMD4 float More... | |||
| static Simd4FBool gmx_simdcall | operator<= (Simd4Float a, Simd4Float b) | ||
| a<=b for SIMD4 float. More... | |||
| static Simd4FBool gmx_simdcall | operator&& (Simd4FBool a, Simd4FBool b) | ||
| Logical and on single precision SIMD4 booleans. More... | |||
| static Simd4FBool gmx_simdcall | operator|| (Simd4FBool a, Simd4FBool b) | ||
| Logical or on single precision SIMD4 booleans. More... | |||
| static bool gmx_simdcall | anyTrue (Simd4FBool a) | ||
| Returns non-zero if any of the boolean in SIMD4 a is True, otherwise 0. More... | |||
| static Simd4Float gmx_simdcall | selectByMask (Simd4Float a, Simd4FBool mask) | ||
| Select from single precision SIMD4 variable where boolean is true. More... | |||
| static Simd4Float gmx_simdcall | selectByNotMask (Simd4Float a, Simd4FBool mask) | ||
| Select from single precision SIMD4 variable where boolean is false. More... | |||
| static Simd4Float gmx_simdcall | blend (Simd4Float a, Simd4Float b, Simd4FBool sel) | ||
| Vector-blend SIMD4 selection. More... | |||
| static float gmx_simdcall | reduce (Simd4Float a) | ||
| Return sum of all elements in SIMD4 float variable. More... | |||
SIMD implementation load/store operations for double precision floating point | |||
| static SimdDouble gmx_simdcall | simdLoad (const double *m, SimdDoubleTag={}) | ||
| Load GMX_SIMD_DOUBLE_WIDTH numbers from aligned memory. More... | |||
| static void gmx_simdcall | store (double *m, SimdDouble a) | ||
| Store the contents of SIMD double variable to aligned memory m. More... | |||
| static SimdDouble gmx_simdcall | simdLoadU (const double *m, SimdDoubleTag={}) | ||
| Load SIMD double from unaligned memory. More... | |||
| static void gmx_simdcall | storeU (double *m, SimdDouble a) | ||
| Store SIMD double to unaligned memory. More... | |||
| static SimdDouble gmx_simdcall | setZeroD () | ||
| Set all SIMD double variable elements to 0.0. More... | |||
SIMD implementation load/store operations for integers (corresponding to double) | |||
| static SimdDInt32 gmx_simdcall | simdLoad (const std::int32_t *m, SimdDInt32Tag) | ||
| Load aligned SIMD integer data, width corresponds to gmx::SimdDouble. More... | |||
| static void gmx_simdcall | store (std::int32_t *m, SimdDInt32 a) | ||
| Store aligned SIMD integer data, width corresponds to gmx::SimdDouble. More... | |||
| static SimdDInt32 gmx_simdcall | simdLoadU (const std::int32_t *m, SimdDInt32Tag) | ||
| Load unaligned integer SIMD data, width corresponds to gmx::SimdDouble. More... | |||
| static void gmx_simdcall | storeU (std::int32_t *m, SimdDInt32 a) | ||
| Store unaligned SIMD integer data, width corresponds to gmx::SimdDouble. More... | |||
| static SimdDInt32 gmx_simdcall | setZeroDI () | ||
| Set all SIMD (double) integer variable elements to 0. More... | |||
| template<int index> | |||
| static std::int32_t gmx_simdcall | extract (SimdDInt32 a) | ||
| Extract element with index i from gmx::SimdDInt32. More... | |||
SIMD implementation double precision floating-point bitwise logical operations | |||
| static SimdDouble gmx_simdcall | operator& (SimdDouble a, SimdDouble b) | ||
| Bitwise and for two SIMD double variables. More... | |||
| static SimdDouble gmx_simdcall | andNot (SimdDouble a, SimdDouble b) | ||
| Bitwise andnot for SIMD double. More... | |||
| static SimdDouble gmx_simdcall | operator| (SimdDouble a, SimdDouble b) | ||
| Bitwise or for SIMD double. More... | |||
| static SimdDouble gmx_simdcall | operator^ (SimdDouble a, SimdDouble b) | ||
| Bitwise xor for SIMD double. More... | |||
SIMD implementation double precision floating-point arithmetics | |||
| static SimdDouble gmx_simdcall | operator+ (SimdDouble a, SimdDouble b) | ||
| Add two double SIMD variables. More... | |||
| static SimdDouble gmx_simdcall | operator- (SimdDouble a, SimdDouble b) | ||
| Subtract two double SIMD variables. More... | |||
| static SimdDouble gmx_simdcall | operator- (SimdDouble a) | ||
| SIMD double precision negate. More... | |||
| static SimdDouble gmx_simdcall | operator* (SimdDouble a, SimdDouble b) | ||
| Multiply two double SIMD variables. More... | |||
| static SimdDouble gmx_simdcall | fma (SimdDouble a, SimdDouble b, SimdDouble c) | ||
| SIMD double Fused-multiply-add. Result is a*b+c. More... | |||
| static SimdDouble gmx_simdcall | fms (SimdDouble a, SimdDouble b, SimdDouble c) | ||
| SIMD double Fused-multiply-subtract. Result is a*b-c. More... | |||
| static SimdDouble gmx_simdcall | fnma (SimdDouble a, SimdDouble b, SimdDouble c) | ||
| SIMD double Fused-negated-multiply-add. Result is -a*b+c. More... | |||
| static SimdDouble gmx_simdcall | fnms (SimdDouble a, SimdDouble b, SimdDouble c) | ||
| SIMD double Fused-negated-multiply-subtract. Result is -a*b-c. More... | |||
| static SimdDouble gmx_simdcall | rsqrt (SimdDouble x) | ||
| double SIMD 1.0/sqrt(x) lookup. More... | |||
| static SimdDouble gmx_simdcall | rcp (SimdDouble x) | ||
| SIMD double 1.0/x lookup. More... | |||
| static SimdDouble gmx_simdcall | maskAdd (SimdDouble a, SimdDouble b, SimdDBool m) | ||
| Add two double SIMD variables, masked version. More... | |||
| static SimdDouble gmx_simdcall | maskzMul (SimdDouble a, SimdDouble b, SimdDBool m) | ||
| Multiply two double SIMD variables, masked version. More... | |||
| static SimdDouble gmx_simdcall | maskzFma (SimdDouble a, SimdDouble b, SimdDouble c, SimdDBool m) | ||
| SIMD double fused multiply-add, masked version. More... | |||
| static SimdDouble gmx_simdcall | maskzRsqrt (SimdDouble x, SimdDBool m) | ||
| SIMD double 1.0/sqrt(x) lookup, masked version. More... | |||
| static SimdDouble gmx_simdcall | maskzRcp (SimdDouble x, SimdDBool m) | ||
| SIMD double 1.0/x lookup, masked version. More... | |||
| static SimdDouble gmx_simdcall | abs (SimdDouble a) | ||
| SIMD double floating-point fabs(). More... | |||
| static SimdDouble gmx_simdcall | max (SimdDouble a, SimdDouble b) | ||
| Set each SIMD double element to the largest from two variables. More... | |||
| static SimdDouble gmx_simdcall | min (SimdDouble a, SimdDouble b) | ||
| Set each SIMD double element to the smallest from two variables. More... | |||
| static SimdDouble gmx_simdcall | round (SimdDouble a) | ||
| SIMD double round to nearest integer value (in floating-point format). More... | |||
| static SimdDouble gmx_simdcall | trunc (SimdDouble a) | ||
| Truncate SIMD double, i.e. round towards zero - common hardware instruction. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static SimdDouble gmx_simdcall | frexp (SimdDouble value, SimdDInt32 *exponent) | ||
| Extract (integer) exponent and fraction from double precision SIMD. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static SimdDouble gmx_simdcall | ldexp (SimdDouble value, SimdDInt32 exponent) | ||
| Multiply a SIMD double value by the number 2 raised to an exp power. More... | |||
| static double gmx_simdcall | reduce (SimdDouble a) | ||
| Return sum of all elements in SIMD double variable. More... | |||
SIMD implementation double precision floating-point comparison, boolean, selection. | |||
| static SimdDBool gmx_simdcall | operator== (SimdDouble a, SimdDouble b) | ||
| SIMD a==b for double SIMD. More... | |||
| static SimdDBool gmx_simdcall | operator!= (SimdDouble a, SimdDouble b) | ||
| SIMD a!=b for double SIMD. More... | |||
| static SimdDBool gmx_simdcall | operator< (SimdDouble a, SimdDouble b) | ||
| SIMD a<b for double SIMD. More... | |||
| static SimdDBool gmx_simdcall | operator<= (SimdDouble a, SimdDouble b) | ||
| SIMD a<=b for double SIMD. More... | |||
| static SimdDBool gmx_simdcall | testBits (SimdDouble a) | ||
| Return true if any bits are set in the single precision SIMD. More... | |||
| static SimdDBool gmx_simdcall | operator&& (SimdDBool a, SimdDBool b) | ||
| Logical and on double precision SIMD booleans. More... | |||
| static SimdDBool gmx_simdcall | operator|| (SimdDBool a, SimdDBool b) | ||
| Logical or on double precision SIMD booleans. More... | |||
| static bool gmx_simdcall | anyTrue (SimdDBool a) | ||
| Returns non-zero if any of the boolean in SIMD a is True, otherwise 0. More... | |||
| static SimdDouble gmx_simdcall | selectByMask (SimdDouble a, SimdDBool mask) | ||
| Select from double precision SIMD variable where boolean is true. More... | |||
| static SimdDouble gmx_simdcall | selectByNotMask (SimdDouble a, SimdDBool mask) | ||
| Select from double precision SIMD variable where boolean is false. More... | |||
| static SimdDouble gmx_simdcall | blend (SimdDouble a, SimdDouble b, SimdDBool sel) | ||
| Vector-blend SIMD double selection. More... | |||
SIMD implementation integer (corresponding to double) bitwise logical operations | |||
| static SimdDInt32 gmx_simdcall | operator& (SimdDInt32 a, SimdDInt32 b) | ||
| Integer SIMD bitwise and. More... | |||
| static SimdDInt32 gmx_simdcall | andNot (SimdDInt32 a, SimdDInt32 b) | ||
| Integer SIMD bitwise not/complement. More... | |||
| static SimdDInt32 gmx_simdcall | operator| (SimdDInt32 a, SimdDInt32 b) | ||
| Integer SIMD bitwise or. More... | |||
| static SimdDInt32 gmx_simdcall | operator^ (SimdDInt32 a, SimdDInt32 b) | ||
| Integer SIMD bitwise xor. More... | |||
SIMD implementation integer (corresponding to double) arithmetics | |||
| static SimdDInt32 gmx_simdcall | operator+ (SimdDInt32 a, SimdDInt32 b) | ||
| Add SIMD integers. More... | |||
| static SimdDInt32 gmx_simdcall | operator- (SimdDInt32 a, SimdDInt32 b) | ||
| Subtract SIMD integers. More... | |||
| static SimdDInt32 gmx_simdcall | operator* (SimdDInt32 a, SimdDInt32 b) | ||
| Multiply SIMD integers. More... | |||
SIMD implementation integer (corresponding to double) comparisons, boolean selection | |||
| static SimdDIBool gmx_simdcall | operator== (SimdDInt32 a, SimdDInt32 b) | ||
| Equality comparison of two integers corresponding to double values. More... | |||
| static SimdDIBool gmx_simdcall | operator< (SimdDInt32 a, SimdDInt32 b) | ||
| Less-than comparison of two SIMD integers corresponding to double values. More... | |||
| static SimdDIBool gmx_simdcall | testBits (SimdDInt32 a) | ||
| Check if any bit is set in each element. More... | |||
| static SimdDIBool gmx_simdcall | operator&& (SimdDIBool a, SimdDIBool b) | ||
| Logical AND on SimdDIBool. More... | |||
| static SimdDIBool gmx_simdcall | operator|| (SimdDIBool a, SimdDIBool b) | ||
| Logical OR on SimdDIBool. More... | |||
| static bool gmx_simdcall | anyTrue (SimdDIBool a) | ||
| Returns true if any of the boolean in x is True, otherwise 0. More... | |||
| static SimdDInt32 gmx_simdcall | selectByMask (SimdDInt32 a, SimdDIBool mask) | ||
| Select from gmx::SimdDInt32 variable where boolean is true. More... | |||
| static SimdDInt32 gmx_simdcall | selectByNotMask (SimdDInt32 a, SimdDIBool mask) | ||
| Select from gmx::SimdDInt32 variable where boolean is false. More... | |||
| static SimdDInt32 gmx_simdcall | blend (SimdDInt32 a, SimdDInt32 b, SimdDIBool sel) | ||
| Vector-blend SIMD integer selection. More... | |||
SIMD implementation conversion operations | |||
| static SimdDInt32 gmx_simdcall | cvtR2I (SimdDouble a) | ||
| Round double precision floating point to integer. More... | |||
| static SimdDInt32 gmx_simdcall | cvttR2I (SimdDouble a) | ||
| Truncate double precision floating point to integer. More... | |||
| static SimdDouble gmx_simdcall | cvtI2R (SimdDInt32 a) | ||
| Convert integer to double precision floating point. More... | |||
| static SimdDIBool gmx_simdcall | cvtB2IB (SimdDBool a) | ||
| Convert from double precision boolean to corresponding integer boolean. More... | |||
| static SimdDBool gmx_simdcall | cvtIB2B (SimdDIBool a) | ||
| Convert from integer boolean to corresponding double precision boolean. More... | |||
| static SimdDouble gmx_simdcall | cvtF2D (SimdFloat gmx_unused f) | ||
| Convert SIMD float to double. More... | |||
| static SimdFloat gmx_simdcall | cvtD2F (SimdDouble gmx_unused d) | ||
| Convert SIMD double to float. More... | |||
| static void gmx_simdcall | cvtF2DD (SimdFloat gmx_unused f, SimdDouble gmx_unused *d0, SimdDouble gmx_unused *d1) | ||
| Convert SIMD float to double. More... | |||
| static SimdFloat gmx_simdcall | cvtDD2F (SimdDouble gmx_unused d0, SimdDouble gmx_unused d1) | ||
| Convert SIMD double to float. More... | |||
| static SimdFInt32 gmx_simdcall | cvtR2I (SimdFloat a) | ||
| Round single precision floating point to integer. More... | |||
| static SimdFInt32 gmx_simdcall | cvttR2I (SimdFloat a) | ||
| Truncate single precision floating point to integer. More... | |||
| static SimdFloat gmx_simdcall | cvtI2R (SimdFInt32 a) | ||
| Convert integer to single precision floating point. More... | |||
| static SimdFIBool gmx_simdcall | cvtB2IB (SimdFBool a) | ||
| Convert from single precision boolean to corresponding integer boolean. More... | |||
| static SimdFBool gmx_simdcall | cvtIB2B (SimdFIBool a) | ||
| Convert from integer boolean to corresponding single precision boolean. More... | |||
SIMD implementation load/store operations for single precision floating point | |||
| static SimdFloat gmx_simdcall | simdLoad (const float *m, SimdFloatTag={}) | ||
| Load GMX_SIMD_FLOAT_WIDTH float numbers from aligned memory. More... | |||
| static void gmx_simdcall | store (float *m, SimdFloat a) | ||
| Store the contents of SIMD float variable to aligned memory m. More... | |||
| static SimdFloat gmx_simdcall | simdLoadU (const float *m, SimdFloatTag={}) | ||
| Load SIMD float from unaligned memory. More... | |||
| static void gmx_simdcall | storeU (float *m, SimdFloat a) | ||
| Store SIMD float to unaligned memory. More... | |||
| static SimdFloat gmx_simdcall | setZeroF () | ||
| Set all SIMD float variable elements to 0.0. More... | |||
SIMD implementation load/store operations for integers (corresponding to float) | |||
| static SimdFInt32 gmx_simdcall | simdLoad (const std::int32_t *m, SimdFInt32Tag) | ||
| Load aligned SIMD integer data, width corresponds to gmx::SimdFloat. More... | |||
| static void gmx_simdcall | store (std::int32_t *m, SimdFInt32 a) | ||
| Store aligned SIMD integer data, width corresponds to gmx::SimdFloat. More... | |||
| static SimdFInt32 gmx_simdcall | simdLoadU (const std::int32_t *m, SimdFInt32Tag) | ||
| Load unaligned integer SIMD data, width corresponds to gmx::SimdFloat. More... | |||
| static void gmx_simdcall | storeU (std::int32_t *m, SimdFInt32 a) | ||
| Store unaligned SIMD integer data, width corresponds to gmx::SimdFloat. More... | |||
| static SimdFInt32 gmx_simdcall | setZeroFI () | ||
| Set all SIMD (float) integer variable elements to 0. More... | |||
| template<int index> | |||
| static std::int32_t gmx_simdcall | extract (SimdFInt32 a) | ||
| Extract element with index i from gmx::SimdFInt32. More... | |||
SIMD implementation single precision floating-point bitwise logical operations | |||
| static SimdFloat gmx_simdcall | operator& (SimdFloat a, SimdFloat b) | ||
| Bitwise and for two SIMD float variables. More... | |||
| static SimdFloat gmx_simdcall | andNot (SimdFloat a, SimdFloat b) | ||
| Bitwise andnot for SIMD float. More... | |||
| static SimdFloat gmx_simdcall | operator| (SimdFloat a, SimdFloat b) | ||
| Bitwise or for SIMD float. More... | |||
| static SimdFloat gmx_simdcall | operator^ (SimdFloat a, SimdFloat b) | ||
| Bitwise xor for SIMD float. More... | |||
SIMD implementation single precision floating-point arithmetics | |||
| static SimdFloat gmx_simdcall | operator+ (SimdFloat a, SimdFloat b) | ||
| Add two float SIMD variables. More... | |||
| static SimdFloat gmx_simdcall | operator- (SimdFloat a, SimdFloat b) | ||
| Subtract two float SIMD variables. More... | |||
| static SimdFloat gmx_simdcall | operator- (SimdFloat a) | ||
| SIMD single precision negate. More... | |||
| static SimdFloat gmx_simdcall | operator* (SimdFloat a, SimdFloat b) | ||
| Multiply two float SIMD variables. More... | |||
| static SimdFloat gmx_simdcall | fma (SimdFloat a, SimdFloat b, SimdFloat c) | ||
| SIMD float Fused-multiply-add. Result is a*b+c. More... | |||
| static SimdFloat gmx_simdcall | fms (SimdFloat a, SimdFloat b, SimdFloat c) | ||
| SIMD float Fused-multiply-subtract. Result is a*b-c. More... | |||
| static SimdFloat gmx_simdcall | fnma (SimdFloat a, SimdFloat b, SimdFloat c) | ||
| SIMD float Fused-negated-multiply-add. Result is -a*b+c. More... | |||
| static SimdFloat gmx_simdcall | fnms (SimdFloat a, SimdFloat b, SimdFloat c) | ||
| SIMD float Fused-negated-multiply-subtract. Result is -a*b-c. More... | |||
| static SimdFloat gmx_simdcall | rsqrt (SimdFloat x) | ||
| SIMD float 1.0/sqrt(x) lookup. More... | |||
| static SimdFloat gmx_simdcall | rcp (SimdFloat x) | ||
| SIMD float 1.0/x lookup. More... | |||
| static SimdFloat gmx_simdcall | maskAdd (SimdFloat a, SimdFloat b, SimdFBool m) | ||
| Add two float SIMD variables, masked version. More... | |||
| static SimdFloat gmx_simdcall | maskzMul (SimdFloat a, SimdFloat b, SimdFBool m) | ||
| Multiply two float SIMD variables, masked version. More... | |||
| static SimdFloat gmx_simdcall | maskzFma (SimdFloat a, SimdFloat b, SimdFloat c, SimdFBool m) | ||
| SIMD float fused multiply-add, masked version. More... | |||
| static SimdFloat gmx_simdcall | maskzRsqrt (SimdFloat x, SimdFBool m) | ||
| SIMD float 1.0/sqrt(x) lookup, masked version. More... | |||
| static SimdFloat gmx_simdcall | maskzRcp (SimdFloat x, SimdFBool m) | ||
| SIMD float 1.0/x lookup, masked version. More... | |||
| static SimdFloat gmx_simdcall | abs (SimdFloat a) | ||
| SIMD float Floating-point abs(). More... | |||
| static SimdFloat gmx_simdcall | max (SimdFloat a, SimdFloat b) | ||
| Set each SIMD float element to the largest from two variables. More... | |||
| static SimdFloat gmx_simdcall | min (SimdFloat a, SimdFloat b) | ||
| Set each SIMD float element to the smallest from two variables. More... | |||
| static SimdFloat gmx_simdcall | round (SimdFloat a) | ||
| SIMD float round to nearest integer value (in floating-point format). More... | |||
| static SimdFloat gmx_simdcall | trunc (SimdFloat a) | ||
| Truncate SIMD float, i.e. round towards zero - common hardware instruction. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static SimdFloat gmx_simdcall | frexp (SimdFloat value, SimdFInt32 *exponent) | ||
| Extract (integer) exponent and fraction from single precision SIMD. More... | |||
| template<MathOptimization opt = MathOptimization::Safe> | |||
| static SimdFloat gmx_simdcall | ldexp (SimdFloat value, SimdFInt32 exponent) | ||
| Multiply a SIMD float value by the number 2 raised to an exp power. More... | |||
| static float gmx_simdcall | reduce (SimdFloat a) | ||
| Return sum of all elements in SIMD float variable. More... | |||
SIMD implementation single precision floating-point comparisons, boolean, selection. | |||
| static SimdFBool gmx_simdcall | operator== (SimdFloat a, SimdFloat b) | ||
| SIMD a==b for single SIMD. More... | |||
| static SimdFBool gmx_simdcall | operator!= (SimdFloat a, SimdFloat b) | ||
| SIMD a!=b for single SIMD. More... | |||
| static SimdFBool gmx_simdcall | operator< (SimdFloat a, SimdFloat b) | ||
| SIMD a<b for single SIMD. More... | |||
| static SimdFBool gmx_simdcall | operator<= (SimdFloat a, SimdFloat b) | ||
| SIMD a<=b for single SIMD. More... | |||
| static SimdFBool gmx_simdcall | testBits (SimdFloat a) | ||
| Return true if any bits are set in the single precision SIMD. More... | |||
| static SimdFBool gmx_simdcall | operator&& (SimdFBool a, SimdFBool b) | ||
| Logical and on single precision SIMD booleans. More... | |||
| static SimdFBool gmx_simdcall | operator|| (SimdFBool a, SimdFBool b) | ||
| Logical or on single precision SIMD booleans. More... | |||
| static bool gmx_simdcall | anyTrue (SimdFBool a) | ||
| Returns non-zero if any of the boolean in SIMD a is True, otherwise 0. More... | |||
| static SimdFloat gmx_simdcall | selectByMask (SimdFloat a, SimdFBool mask) | ||
| Select from single precision SIMD variable where boolean is true. More... | |||
| static SimdFloat gmx_simdcall | selectByNotMask (SimdFloat a, SimdFBool mask) | ||
| Select from single precision SIMD variable where boolean is false. More... | |||
| static SimdFloat gmx_simdcall | blend (SimdFloat a, SimdFloat b, SimdFBool sel) | ||
| Vector-blend SIMD float selection. More... | |||
SIMD implementation integer (corresponding to float) bitwise logical operations | |||
| static SimdFInt32 gmx_simdcall | operator& (SimdFInt32 a, SimdFInt32 b) | ||
| Integer SIMD bitwise and. More... | |||
| static SimdFInt32 gmx_simdcall | andNot (SimdFInt32 a, SimdFInt32 b) | ||
| Integer SIMD bitwise not/complement. More... | |||
| static SimdFInt32 gmx_simdcall | operator| (SimdFInt32 a, SimdFInt32 b) | ||
| Integer SIMD bitwise or. More... | |||
| static SimdFInt32 gmx_simdcall | operator^ (SimdFInt32 a, SimdFInt32 b) | ||
| Integer SIMD bitwise xor. More... | |||
SIMD implementation integer (corresponding to float) arithmetics | |||
| static SimdFInt32 gmx_simdcall | operator+ (SimdFInt32 a, SimdFInt32 b) | ||
| Add SIMD integers. More... | |||
| static SimdFInt32 gmx_simdcall | operator- (SimdFInt32 a, SimdFInt32 b) | ||
| Subtract SIMD integers. More... | |||
| static SimdFInt32 gmx_simdcall | operator* (SimdFInt32 a, SimdFInt32 b) | ||
| Multiply SIMD integers. More... | |||
SIMD implementation integer (corresponding to float) comparisons, boolean, selection | |||
| static SimdFIBool gmx_simdcall | operator== (SimdFInt32 a, SimdFInt32 b) | ||
| Equality comparison of two integers corresponding to float values. More... | |||
| static SimdFIBool gmx_simdcall | operator< (SimdFInt32 a, SimdFInt32 b) | ||
| Less-than comparison of two SIMD integers corresponding to float values. More... | |||
| static SimdFIBool gmx_simdcall | testBits (SimdFInt32 a) | ||
| Check if any bit is set in each element. More... | |||
| static SimdFIBool gmx_simdcall | operator&& (SimdFIBool a, SimdFIBool b) | ||
| Logical AND on SimdFIBool. More... | |||
| static SimdFIBool gmx_simdcall | operator|| (SimdFIBool a, SimdFIBool b) | ||
| Logical OR on SimdFIBool. More... | |||
| static bool gmx_simdcall | anyTrue (SimdFIBool a) | ||
| Returns true if any of the boolean in x is True, otherwise 0. More... | |||
| static SimdFInt32 gmx_simdcall | selectByMask (SimdFInt32 a, SimdFIBool mask) | ||
| Select from gmx::SimdFInt32 variable where boolean is true. More... | |||
| static SimdFInt32 gmx_simdcall | selectByNotMask (SimdFInt32 a, SimdFIBool mask) | ||
| Select from gmx::SimdFInt32 variable where boolean is false. More... | |||
| static SimdFInt32 gmx_simdcall | blend (SimdFInt32 a, SimdFInt32 b, SimdFIBool sel) | ||
| Vector-blend SIMD integer selection. More... | |||
Higher-level SIMD utilities accessing partial (half-width) SIMD doubles. | |||
See the single-precision versions for documentation. Since double precision is typically half the width of single, this double version is likely only useful with 512-bit and larger implementations. | |||
| static SimdDouble gmx_simdcall | loadDualHsimd (const double *m0, const double *m1) | ||
| Load low & high parts of SIMD double from different locations. More... | |||
| static SimdDouble gmx_simdcall | loadDuplicateHsimd (const double *m) | ||
| Load half-SIMD-width double data, spread to both halves. More... | |||
| static SimdDouble gmx_simdcall | loadU1DualHsimd (const double *m) | ||
| Load two doubles, spread 1st in low half, 2nd in high half. More... | |||
| static void gmx_simdcall | storeDualHsimd (double *m0, double *m1, SimdDouble a) | ||
| Store low & high parts of SIMD double to different locations. More... | |||
| static void gmx_simdcall | incrDualHsimd (double *m0, double *m1, SimdDouble a) | ||
| Add each half of SIMD variable to separate memory adresses. More... | |||
| static void gmx_simdcall | decr3Hsimd (double *m, SimdDouble a0, SimdDouble a1, SimdDouble a2) | ||
| Add the two halves of three SIMD doubles, subtract the sum from three half-SIMD-width consecutive doubles in memory. More... | |||
| template<int align> | |||
| static void gmx_simdcall | gatherLoadTransposeHsimd (const double *base0, const double *base1, const std::int32_t offset[], SimdDouble *v0, SimdDouble *v1) | ||
| Load 2 consecutive doubles from each of GMX_SIMD_DOUBLE_WIDTH/2 offsets, transpose into SIMD double (low half from base0, high from base1). More... | |||
| static double gmx_simdcall | reduceIncr4ReturnSumHsimd (double *m, SimdDouble v0, SimdDouble v1) | ||
| Reduce the 4 half-SIMD-with doubles in 2 SIMD variables (sum halves), increment four consecutive doubles in memory, return sum. More... | |||
| static SimdDouble gmx_simdcall | loadUNDuplicate4 (const double *m) | ||
| Load N doubles and duplicate them 4 times each. More... | |||
| static SimdDouble gmx_simdcall | load4DuplicateN (const double *m) | ||
| Load 4 doubles and duplicate them N times each. More... | |||
| static SimdDouble gmx_simdcall | loadU4NOffset (const double *m, int offset) | ||
| Load doubles in blocks of 4 at fixed offsets. More... | |||
Higher-level SIMD utilities accessing partial (half-width) SIMD floats. | |||
These functions are optional. The are only useful for SIMD implementation where the width is 8 or larger, and where it would be inefficient to process 4*8, 8*8, or more, interactions in parallel. Currently, only Intel provides very wide SIMD implementations, but these also come with excellent support for loading, storing, accessing and shuffling parts of the register in so-called 'lanes' of 4 bytes each. We can use this to load separate parts into the low/high halves of the register in the inner loop of the nonbonded kernel, which e.g. makes it possible to process 4*4 nonbonded interactions as a pattern of 2*8. We can also use implementations with width 16 or greater. To make this more generic, when GMX_SIMD_HAVE_HSIMD_UTIL_REAL is 1, the SIMD implementation provides seven special routines that:
Remember: this is ONLY used when the native SIMD width is large. You will just waste time if you implement it for normal 16-byte SIMD architectures. This is part of the new C++ SIMD interface, so these functions are only available when using C++. Since some Gromacs code reliying on the SIMD module is still C (not C++), we have kept the C-style naming for now - this will change once we are entirely C++. | |||
| static SimdFloat gmx_simdcall | loadDualHsimd (const float *m0, const float *m1) | ||
| Load low & high parts of SIMD float from different locations. More... | |||
| static SimdFloat gmx_simdcall | loadDuplicateHsimd (const float *m) | ||
| Load half-SIMD-width float data, spread to both halves. More... | |||
| static SimdFloat gmx_simdcall | loadU1DualHsimd (const float *m) | ||
| Load two floats, spread 1st in low half, 2nd in high half. More... | |||
| static void gmx_simdcall | storeDualHsimd (float *m0, float *m1, SimdFloat a) | ||
| Store low & high parts of SIMD float to different locations. More... | |||
| static void gmx_simdcall | incrDualHsimd (float *m0, float *m1, SimdFloat a) | ||
| Add each half of SIMD variable to separate memory adresses. More... | |||
| static void gmx_simdcall | decr3Hsimd (float *m, SimdFloat a0, SimdFloat a1, SimdFloat a2) | ||
| Add the two halves of three SIMD floats, subtract the sum from three half-SIMD-width consecutive floats in memory. More... | |||
| template<int align> | |||
| static void gmx_simdcall | gatherLoadTransposeHsimd (const float *base0, const float *base1, const std::int32_t offset[], SimdFloat *v0, SimdFloat *v1) | ||
| Load 2 consecutive floats from each of GMX_SIMD_FLOAT_WIDTH/2 offsets, transpose into SIMD float (low half from base0, high from base1). More... | |||
| static float gmx_simdcall | reduceIncr4ReturnSumHsimd (float *m, SimdFloat v0, SimdFloat v1) | ||
| Reduce the 4 half-SIMD-with floats in 2 SIMD variables (sum halves), increment four consecutive floats in memory, return sum. More... | |||
| static SimdFloat gmx_simdcall | loadUNDuplicate4 (const float *m) | ||
| Load N floats and duplicate them 4 times each. More... | |||
| static SimdFloat gmx_simdcall | load4DuplicateN (const float *m) | ||
| Load 4 floats and duplicate them N times each. More... | |||
| static SimdFloat gmx_simdcall | loadU4NOffset (const float *m, int offset) | ||
| Load floats in blocks of 4 at fixed offsets. More... | |||
Overloads for converting a value of a given type to a string.
| |||
| static std::string | toString (bool t) | ||
| static std::string | toString (int t) | ||
| static std::string | toString (unsigned int t) | ||
| static std::string | toString (int64_t t) | ||
| static std::string | toString (uint64_t t) | ||
| static std::string | toString (float t) | ||
| static std::string | toString (double t) | ||
| static std::string | toString (unsigned char t) | ||
| static std::string | toString (std::string t) | ||
| void | dumpIntArrayRef (TextWriter *writer, const char *description, ArrayRef< const int > values, bool showIndices) | ||
Dump the formatted values to writer along with a description and/or indices. | |||
| void | dumpFloatArrayRef (TextWriter *writer, const char *description, ArrayRef< const float > values, bool showIndices) | ||
| void | dumpDoubleArrayRef (TextWriter *writer, const char *description, ArrayRef< const double > values, bool showIndices) | ||
| void | dumpRealArrayRef (TextWriter *writer, const char *description, ArrayRef< const real > values, bool showIndices) | ||
| void | dumpRvecArrayRef (TextWriter *writer, const char *description, ArrayRef< const RVec > values) | ||
| template<typename T > | |||
| std::remove_const_t< T > | norm (T *v) | ||
| Forward operations on C Array style vectors to C implementations. More... | |||
| template<typename T > | |||
| std::remove_const_t< T > | norm2 (T *v) | ||
Variables | |
| const gmx::EnumerationArray < XvgFormat, const char * > | c_xvgFormatNames |
| Names for XvgFormat. More... | |
| static const int | c_linewidth = 80 - 2 |
| Linewidth used for warning output. | |
| static const int | c_biasMaxNumDim = 4 |
| The maximum dimensionality of the AWH coordinate. | |
| static const std::string | colvarsConfig = "colvars_sample.dat" |
| static const EnumerationArray < DensitySimilarityMeasureMethod, const char * > | c_densitySimilarityMeasureMethodNames |
| Name the methods that may be used to evaluate similarity between densities. More... | |
| static const EnumerationArray < DensityFittingAmplitudeMethod, const char * > | c_densityFittingAmplitudeMethodNames |
| The names of the methods to determine the amplitude of the atoms to be spread on a grid. More... | |
| box_ { { 0.0, 0.0, 0.0 }, { 0.0, 0.0, 0.0 }, { 0.0, 0.0, 0.0 } } | |
| static constexpr auto | torchRealType = GMX_DOUBLE ? torch::kFloat64 : torch::kFloat32 |
| Define the torch datatype according to GMX_DOUBLE. More... | |
| static const EnumerationArray < QMMMQMMethod, const char * > | c_qmmmQMMethodNames |
| The names of the supported QM methods. More... | |
| const std::vector< std::string > | periodic_system |
| symbols of the elements in periodic table More... | |
| static const EnumerationArray < ChangeSettingType, const char * > | c_changeSettingTypeNames |
| Mapping for enums from ChangeSettingType. More... | |
| static const EnumerationArray < ChangeAtomsType, const char * > | c_changeAtomsTypeNames |
| Mapping for enums from ChangeAtomsType. More... | |
| static const ivec | sc_ddZoneOrder [sc_maxNumZones] |
| The DD zone order. More... | |
| static const int | ddNonbondedZonePairRanges [sc_maxNumIZones][3] |
| The non-bonded zone-pair setup for domain decomposition. More... | |
| static constexpr int | sc_maxNumZones = 8 |
| The maximum possible number of zones, 2 along each dimension in the eighth shell method. | |
| static constexpr int | sc_maxNumIZones = sc_maxNumZones / 2 |
| The maximum possible number of i-zones, half of the zones are needed to cover all pairs. | |
| const int | PMETunePeriod = 50 |
| After 50 nstlist periods of not observing imbalance: never tune PME. | |
| const real | loadBalanceTriggerFactor = 1.05 |
| Trigger PME load balancing at more than 5% PME overload. | |
| const real | c_maxSpacingScaling = 1.7 |
| Scale the grid by a most at factor 1.7. More... | |
| const real | gridpointsScaleFactor = 0.8 |
| In the initial scan, step by grids that are at least a factor 0.8 coarser. | |
| const real | relativeEfficiencyFactor = 1.05 |
| In the initial scan, try to skip grids with uneven x/y/z spacing, checking if the "efficiency" is more than 5% worse than the previous grid. | |
| const real | maxRelativeSlowdownAccepted = 1.12 |
| Rerun until a run is 12% slower setups than the fastest run so far. | |
| const real | maxFluctuationAccepted = 1.02 |
| If setups get more than 2% faster, do another round to avoid choosing a slower setup due to acceleration or fluctuations. | |
| const int | c_numFirstTuningIntervalSkip = 5 |
| Number of nstlist long tuning intervals to skip before starting. | |
| const int | c_numFirstTuningIntervalSkipWithSepPme = 3 |
| Number of nstlist long tuning intervals to skip before starting. | |
| const int | c_numPostSwitchTuningIntervalSkip = 1 |
| Number of nstlist long tuning intervals to skip after switching to a new setting. | |
| const double | c_startupTimeDelay = 5.0 |
| Number of seconds to delay the tuning at startup to allow processors clocks to ramp up. | |
| realGrid_ | realGrid |
| pmeStream | |
| static constexpr int64_t | sc_checkpointMaxAtomCount = std::numeric_limits<unsigned int>::max() / 3 |
| The maximum number of atoms that can be stored in a checkpoint file. | |
| constexpr char | c_unitAttributeKey [] = "unit" |
| constexpr int | c_h5mdDeflateCompressionLevel = 1 |
| constexpr char | c_valueName [] = "value" |
| Name of value data set inside block group per the H5md specification. | |
| constexpr char | c_stepName [] = "step" |
| Name of step data set inside block group per the H5md specification. | |
| constexpr char | c_timeName [] = "time" |
| Name of time data set inside block group per the H5md specification. | |
| constexpr char | c_timeDataSetUnit [] = "ps" |
| Unit for time data for simulations produced by mdrun. | |
| constexpr H5mdCompression | c_stepAndTimeCompression = H5mdCompression::LosslessShuffle |
| Compression algorithm used for step and time data sets. | |
| constexpr int | c_h5mdInternalTopologyVersionMajor = 0 |
| The major version of the GROMACS internal topology. | |
| constexpr int | c_h5mdInternalTopologyVersionMinor = 1 |
| The minor version of the GROMACS internal topology. | |
| constexpr char | c_massUnit [] = "u" |
| Unit for mass data in GROMACS. | |
| constexpr char | c_elementaryChargeUnit [] = "e" |
| Unit for electric charge data in GROMACS. | |
| constexpr char | c_particleIdName [] = "id" |
| Name of dataset for the identifier for the particles. | |
| constexpr char | c_particleMassName [] = "mass" |
| Name of dataset for the mass of the particles. | |
| constexpr char | c_particleChargeName [] = "charge" |
| Name of dataset for the charge of the particles. | |
| constexpr char | c_particleSpeciesName [] = "species" |
| Name of dataset for the species (atomic number) of the particles. | |
| constexpr char | c_particleNameIndicesName [] = "particle_name" |
| Name of dataset for the names of the particles. | |
| constexpr char | c_particleNameTableName [] = "particle_name_table" |
| Name of dataset for the particle name lookup table. | |
| constexpr char | c_numParticlesAttributeKey [] = "nr_particles" |
| Name of attribute for the number of the particles. | |
| constexpr char | c_residueIdName [] = "residue_id" |
| Name of dataset for the residue identifier of the particles. | |
| constexpr char | c_residueNameIndicesName [] = "residue_name" |
| Name of dataset for the residue names of the particles. | |
| constexpr char | c_residueNameTableName [] = "residue_name_table" |
| Name of dataset for the residue name lookup table. | |
| constexpr char | c_residueSequenceName [] = "sequence" |
| Name of dataset for the residue sequence. | |
| constexpr char | c_numResiduesAttributeKey [] = "nr_residues" |
| Name of attribute for the number of the residues. | |
| constexpr char | c_bondsConnectivityName [] = "bonds" |
| Name of bond dataset inside connectivity group. | |
| constexpr char | c_numberOfBondsAttributeKey [] = "nr_bonds" |
| Name of the attribute storing number of bonds. | |
| constexpr char | c_disulfideBondsName [] = "disulfide_bonds" |
| Name of disulfide bonds within the special bonds group. | |
| constexpr char | c_h5mdInternalTopologyVersionAttributeKey [] = "version" |
| Name of attribute for the version of internal topology. | |
| constexpr char | c_h5mdInternalTopologyNameAttributeKey [] = "system_name" |
| Name of attribute for topology name. | |
| constexpr char | c_moleculeNamesAttributeKey [] = "molecule_names" |
| Name of attribute for the names of the molecule types. | |
| constexpr char | c_numMolBlocksAttributeKey [] = "nr_blocks" |
| Name of attribute for the number of blocks for each molecule types. | |
| constexpr char | c_positionRestraintsAName [] = "posres_xA" |
| Name of attribute for the position restraints of the molecules. | |
| constexpr char | c_positionRestraintsBName [] = "posres_xB" |
| static const EnumerationArray < FmmDirectProvider, const char * > | c_fmmDirectProviderNames |
| String names corresponding to FmmDirectProvider enum values. More... | |
| const std::string | c_fmmFMSolvrDirectRangeOptionName = "fmsolvr-direct-range" |
| MDP option name to configure the direct interaction range for FMSolvr (1 or 2) | |
| const std::string | c_fmmFMSolvrDirectProviderOptionName = "fmsolvr-direct-provider" |
| MDP option name to select the direct interaction provider for FMSolvr (GROMACS or FMM). | |
| const std::string | c_fmmFMSolvrDipoleCompensationOptionName = "fmsolvr-dipole-compensation" |
| MDP option name to enable dipole compensation for improved accuracy in FMSolvr. | |
| const std::string | c_fmmFMSolvrSparseOptionName = "fmsolvr-sparse" |
| MDP option name to enable sparse tree representation in FMSolvr for memory optimization. | |
| static const EnumerationArray < ActiveFmmBackend, const char * > | c_activeFmmBackendNames |
| String names corresponding to ActiveFmmBackend enum values. More... | |
| const std::string | c_fmmActiveOptionName = "backend" |
| MDP option name to enable one of the FMM backends (e.g., ExaFMM). | |
| static const EnumerationArray < ExaFmmTreeType, const char * > | c_exaFmmTreeTypeNames |
| String names corresponding to ExaFmmTreeType enum values. More... | |
| const std::string | c_fmmExaFmmDirectRangeOptionName = "exafmm-direct-range" |
| MDP option name to configure the direct interaction range for ExaFMM (1 or 2) | |
| const std::string | c_fmmExaFmmDirectProviderOptionName = "exafmm-direct-provider" |
| MDP option name to select the direct interaction provider for ExaFMM (GROMACS or FMM) | |
| const std::string | c_fmmExaFmmOrderOptionName = "exafmm-order" |
| MDP option name to set the multipole expansion order for ExaFMM. | |
| const std::string | c_fmmExaFmmTreeTypeOptionName = "exafmm-tree-type" |
| MDP option name to choose the tree type for ExaFMM (uniform or adaptive) More... | |
| const std::string | c_fmmExaFmmTreeDepthOptionName = "exafmm-tree-depth" |
| MDP option name to set the tree depth for ExaFMM. More... | |
| const std::string | c_fmmExaFmmMaxParticlesPerCellOptionName = "exafmm-max-particles-per-cell" |
| MDP option name to set the maximum number of particles per cell for ExaFMM. More... | |
| const std::string | c_fmmFMSolvrOrderOptionName = "fmsolvr-order" |
| MDP option name to set the multipole expansion order for FMSolvr. | |
| const std::string | c_fmmFMSolvrTreeDepthOptionName = "fmsolvr-tree-depth" |
| MDP option name to set the tree depth for FMSolvr (controls spatial subdivision granularity) | |
| static constexpr Architecture | c_architecture |
| Constant that tells what the architecture is. More... | |
| constexpr int | c_loopWait = 1 |
| How long shall we wait in seconds until we check for a connection again? | |
| constexpr int | c_connectWait = 1 |
| How long shall we check for the IMD_GO? | |
| constexpr int | c_headerSize = 8 |
| IMD Header Size. | |
| constexpr int | c_protocolVersion = 2 |
| IMD Protocol Version. | |
| static const char | IMDstr [] = "IMD:" |
| Tag output from the IMD module with this string. More... | |
| constexpr int | c_maxConnections = 1 |
| Currently only 1 client connection is supported. | |
| static constexpr int | numFTypesOnGpu = 8 |
| The number on bonded function types supported on GPUs. | |
| constexpr std::array < InteractionFunction, numFTypesOnGpu > | fTypesOnGpu |
| List of all bonded function types supported on GPUs. More... | |
| BondedGpuKernelBuffers | kernelBuffers |
| BondedGpuKernelBuffers float4 * | gm_xq_in |
|
BondedGpuKernelBuffers float4 float3 * | gm_f |
| BondedGpuKernelBuffers float4 float3 float3 * | gm_fShift |
| const int | tid = blockIdx.x * blockDim.x + threadIdx.x |
| float | vtot_loc = 0.0F |
| float | vtotElec_loc = 0.0F |
| __shared__ float3 | sm_dynamicShmem [] |
| float3 * | sm_fShiftLoc = sm_dynamicShmem |
| DeviceFloat4 * | gm_xq = reinterpret_cast<DeviceFloat4*>(gm_xq_in) |
| InteractionFunction | fType |
| bool | threadComputedPotential = false |
| static const int | simd_width = 1 |
| Define simd_width for memory allocation used for SIMD code. | |
| static constexpr int | c_threadsPerBlock = 256 |
| Number of threads in a GPU block. | |
| static constexpr int | sc_workGroupSize = 256 |
| Number of work-items in a work-group. | |
| static const bool | c_disableAlternatingWait = (std::getenv("GMX_DISABLE_ALTERNATING_GPU_WAIT") != nullptr) |
| static const EnumerationArray < IncompatibilityReasons, std::string > | reasonStrings |
| Strings explaining why the system is incompatible with update groups. More... | |
| static constexpr InteractionFunction | c_ftypeVsiteStart = InteractionFunction::VirtualSite1 |
| The start value of the vsite indices in the ftype enum. More... | |
| static constexpr InteractionFunction | c_ftypeVsiteEnd |
| The start and end value of the vsite indices in the ftype enum. More... | |
| static constexpr int | numFtypes = static_cast<int>(c_ftypeVsiteEnd) - static_cast<int>(c_ftypeVsiteStart) |
| const std::array < InteractionFunction, numFtypes > | vSiteFunctionTypes |
| const std::array < InteractionFunction, numFtypes > | vSiteFunctionTypesReversed |
| static constexpr real | sc_bU_bin_limit = 50 |
| The limit in kT for the histogram of insertion energies. | |
| static constexpr real | sc_bU_logV_bin_limit = sc_bU_bin_limit + 10 |
| The limit in kT for the histogram of insertion energies including the log(volume) term. | |
| static constexpr int32_t | sc_atomInfo_EnergyGroupIdMask = 0b11111111 |
| The first 8 bits are reserved for energy-group ID. | |
| static const gmx::EnumerationArray < MtsForceGroups, std::string > | mtsForceGroupNames |
| Names for the MTS force groups. More... | |
| static constexpr int | s_maxNumThreadsForReduction = 256 |
| The max thread number is arbitrary, we used a fixed number to avoid memory management. Using more than 16 threads is probably never useful performance wise. | |
|
static constexpr EnumerationArray< NhcUsage, const char * > | nhcUsageNames = { "System", "Barostat" } |
| boxVelocity_ { { 0 } } | |
| previousBox_ { { 0 } } | |
| static constexpr int | STRIDE_XYZ = 3 |
| Stride for coordinate/force arrays with xyz coordinate storage. | |
| static constexpr int | STRIDE_XYZQ = 4 |
| Stride for coordinate/force arrays with xyzq coordinate storage. | |
| static constexpr int | c_packX4 = 4 |
| Size of packs of x, y or z with SIMD 4-grouped packed coordinates/forces. | |
| static constexpr int | c_packX8 = 8 |
| Size of packs of x, y or z with SIMD 8-grouped packed coordinates/forces. | |
| static constexpr int | STRIDE_P4 = DIM * c_packX4 |
| Stridefor a pack of 4 coordinates/forces. | |
| static constexpr int | STRIDE_P8 = DIM * c_packX8 |
| Stridefor a pack of 8 coordinates/forces. | |
| static constexpr int | c_numBoundingBoxBounds1D = 2 |
| The number of bounds along one dimension of a bounding box. | |
| constexpr real | c_minDistanceSquared = 1.0e-12_real |
| Lower limit for square interaction distances in nonbonded kernels. More... | |
| constexpr real | c_maxRInvSix = 1.0e15_real |
| Higher limit for r^-6 used for Lennard-Jones interactions. More... | |
| static constexpr int | c_sciHistogramSize = 8192 |
| Number of separate bins used during sorting of plist on gpu. More... | |
| static constexpr int | c_sciSortingThreadsPerBlock = 256 |
| Number of threads per block used by the gpu sorting kernel. More... | |
| static constexpr int | c_sciSortingItemsPerThread = 16 |
| static constexpr int | c_pruneKernelJPackedConcurrency = 4 |
| Default for the prune kernel's jPacked processing concurrency. | |
| static constexpr int | c_sortGridRatio = 4 |
| Ratio of grid cells to atoms. | |
| static constexpr int | c_sortGridMaxSizeFactor = c_sortGridRatio + 1 |
| Maximum ratio of holes used, in the worst case all particles end up in the last hole and we need num. atoms extra holes at the end. | |
| static const unsigned int | gpu_min_ci_balanced_factor = 44 |
| NBParamGpu | nbparam |
| NBParamGpu GpuPairlist | plist |
| template<PairlistType pairlistType> | |
| __device__ constexpr int | c_subWarp = sc_gpuParallelExecutionWidth(pairlistType) |
| template<PairlistType pairlistType> | |
| __device__ constexpr int | c_clSizeLog2 = StaticLog2<sc_gpuClusterSize(pairlistType)>::value |
| Log of the i and j cluster size. change this together with c_clSize ! | |
| template<PairlistType pairlistType> | |
| __device__ constexpr int | c_clSizeSq = sc_gpuClusterSize(pairlistType) * sc_gpuClusterSize(pairlistType) |
| Square of cluster size. | |
| template<PairlistType pairlistType> | |
| static __device__ constexpr int | c_fbufStride = c_clSizeSq<pairlistType> |
| static constexpr auto | refPairlistLayoutType = PairlistType::Hierarchical8x8x8 |
| static constexpr int | c_clSize = sc_gpuClusterSize(refPairlistLayoutType) |
| constexpr int | c_numElecTypes = static_cast<int>(ElecType::Count) |
| Number of possible ElecType values. | |
| constexpr int | c_numVdwTypes = static_cast<int>(VdwType::Count) |
| Number of possible VdwType values. | |
| static constexpr real | c_nbnxnRlistIncreaseOutsideFactor = 0.6 |
| static const float | epsilon |
| const float | sigma6 = sigma2 * sigma2 * sigma2 |
| const float | c6 = epsilon * sigma6 |
| const float | c12 = c6 * sigma6 |
| return { c6, c12 } | |
| static const shift_consts_t | repulsionShift |
|
static const shift_consts_t const float | rVdwSwitch |
|
static const shift_consts_t const float const float const float const float | rInv |
|
static const shift_consts_t const float const float const float const float const float | r2 |
|
static const shift_consts_t const float const float const float const float const float float * | f |
| static const shift_consts_t const float const float const float const float const float float float * | eLJ |
| const float | dispShiftV3 = dispersionShift.c3 |
| const float | repuShiftV2 = repulsionShift.c2 |
| const float | repuShiftV3 = repulsionShift.c3 |
| const float | r = r2 * rInv |
| const float | rSwitch = gmxGpuFDim(r, rVdwSwitch) |
| else | |
| static const int | typeI |
| static const char * | nb_kfunc_noener_noprune_ptr [c_numElecTypes][c_numVdwTypes] |
| Force-only kernel function names. | |
| static const char * | nb_kfunc_ener_noprune_ptr [c_numElecTypes][c_numVdwTypes] |
| Force + energy kernel function pointers. | |
| static const char * | nb_kfunc_noener_prune_ptr [c_numElecTypes][c_numVdwTypes] |
| Force + pruning kernel function pointers. | |
| static const char * | nb_kfunc_ener_prune_ptr [c_numElecTypes][c_numVdwTypes] |
| Force + energy + pruning kernel function pointers. | |
| static unsigned int | gpu_min_ci_balanced_factor = 50 |
| This parameter should be determined heuristically from the kernel execution times. More... | |
| static const char * | kernel_electrostatic_family_definitions [] |
| Array of the defines needed to generate a specific eel flavour. More... | |
| static const char * | kernel_VdW_family_definitions [] |
| Array of the defines needed to generate a specific vdw flavour. More... | |
| constexpr bool | c_pbcShiftBackward = true |
| const int | max_nrj_fep = 40 |
| static constexpr auto | sc_layoutType = PairlistType::Hierarchical8x8x8 |
| Currently hard coded default GPU pairlist layout. | |
| constexpr float | c_nbnxnMinDistanceSquared = 3.82e-07F |
| Lower limit for square interaction distances in nonbonded kernels. More... | |
| static const int | nbnxnReferenceNstlist = 10 |
| Cost of non-bonded kernels. More... | |
| const int | nstlist_try [] = { 20, 25, 40, 50, 80, 100 } |
| The values to try when switching. | |
| static const float | c_nbnxnListSizeFactorCpu = 1.25 |
| Target pair-list size increase ratio for CPU. | |
| static const float | c_nbnxnListSizeFactorGPU = 1.4 |
| Target pair-list size increase ratio for GPU. | |
| static const float | c_nbnxnListSizeFactorMargin = 0.1 |
| Never increase the size of the pair-list more than the factor above plus this margin. | |
| static constexpr int | c_nbnxnGpuRollingListPruningInterval = 2 |
| The interval in steps at which we perform dynamic, rolling pruning on a GPU. More... | |
| static const int | c_nbnxnCpuDynamicListPruningMinLifetime = 5 |
| The minimum nstlist for dynamic pair list pruning on CPUs. More... | |
| static constexpr int | c_nbnxnGpuDynamicListPruningMinLifetime = 4 |
| The minimum nstlist for dynamic pair list pruning om GPUs. More... | |
| static constexpr gmx::EnumerationArray < PairlistType, int > | IClusterSizePerListType |
| Gives the i-cluster size for each pairlist type. More... | |
| static constexpr gmx::EnumerationArray < PairlistType, int > | JClusterSizePerListType |
| Gives the j-cluster size for each pairlist type. More... | |
| static constexpr bool | sc_calculateShiftForces = true |
| Whether we calculate shift forces, always true, because it's cheap anyhow. | |
| static constexpr int | c_syclPruneKernelJPackedConcurrency = c_pruneKernelJPackedConcurrency |
| Prune kernel's jPacked processing concurrency. More... | |
| constexpr int | c_centralShiftIndex = detail::c_numIvecs / 2 |
| constexpr int | c_numShiftVectors = detail::c_numIvecs |
| static const int | sc_indentationIncrement = 3 |
| constexpr double | c_angstrom = 1e-10 |
| constexpr double | c_kilo = 1e3 |
| constexpr double | c_nano = 1e-9 |
| constexpr double | c_pico = 1e-12 |
| constexpr double | c_nm2A = c_nano / c_angstrom |
| constexpr double | c_cal2Joule = 4.184 |
| constexpr double | c_electronCharge = 1.602176634e-19 |
| constexpr double | c_amu = 1.66053906660e-27 |
| constexpr double | c_boltzmann = 1.380649e-23 |
| constexpr double | c_avogadro = 6.02214076e23 |
| constexpr double | c_universalGasConstant = c_boltzmann * c_avogadro |
| constexpr double | c_boltz = c_universalGasConstant / c_kilo |
| constexpr double | c_faraday = c_electronCharge * c_avogadro |
| constexpr double | c_planck1 = 6.62607015e-34 |
| constexpr double | c_planck = (c_planck1 * c_avogadro / (c_pico * c_kilo)) |
| constexpr double | c_epsilon0Si = 8.8541878128e-12 |
| constexpr double | c_epsilon0 |
| constexpr double | c_speedOfLight = 2.99792458e05 |
| constexpr double | c_rydberg = 1.0973731568160e-02 |
| constexpr double | c_one4PiEps0 = (1.0 / (4.0 * 3.14159265358979323846 * c_epsilon0)) |
| constexpr double | c_barMdunits = (1e5 * c_nano * c_pico * c_pico / c_amu) |
| constexpr double | c_presfac = 1.0 / c_barMdunits |
| constexpr double | c_debye2Enm = (1e-15 / (c_speedOfLight * c_electronCharge)) |
| constexpr double | c_enm2Debye = 1.0 / c_debye2Enm |
| constexpr double | c_fieldfac = c_faraday / c_kilo |
| constexpr double | c_hartree2Kj = ((2.0 * c_rydberg * c_planck * c_speedOfLight) / c_avogadro) |
| constexpr double | c_bohr2Nm = 0.0529177210903 |
| constexpr double | c_hartreeBohr2Md = (c_hartree2Kj * c_avogadro / c_bohr2Nm) |
| constexpr double | c_rad2Deg = 180.0 / 3.14159265358979323846 |
| constexpr double | c_deg2Rad = 3.14159265358979323846 / 180.0 |
| template<std::string_view const &... inputStrings> | |
| static constexpr auto | CompileTimeStringJoin_v = CompileTimeStringJoin<inputStrings...>::value |
| static constexpr int32_t | sc_atomInfo_FreeEnergyPerturbation = 1 << 8 |
| Constants whose bit describes a property of an atom in AtomInfoWithinMoleculeBlock.atomInfo. More... | |
| static constexpr int32_t | sc_atomInfo_HasPerturbedCharge = 1 << 9 |
| static constexpr int32_t | sc_atomInfo_Exclusion = 1 << 10 |
| static constexpr int32_t | sc_atomInfo_Constraint = 1 << 11 |
| static constexpr int32_t | sc_atomInfo_Settle = 1 << 12 |
| static constexpr int32_t | sc_atomInfo_BondCommunication = 1 << 13 |
| static constexpr int32_t | sc_atomInfo_HasVdw = 1 << 14 |
| static constexpr int32_t | sc_atomInfo_HasCharge = 1 << 15 |
| static constexpr int32_t | sc_atomInfo_IsFillerParticle = 1 << 16 |
| template<enum VdwType vdwType> | |
| constexpr bool | ljComb = EnergyFunctionProperties<ElecType::Count, vdwType>().vdwComb |
| Templated constants to shorten kernel function declaration. | |
| template<enum ElecType elecType> | |
| constexpr bool | elecEwald = EnergyFunctionProperties<elecType, VdwType::Count>().elecEwald |
| template<enum ElecType elecType> | |
| constexpr bool | elecEwaldTab = EnergyFunctionProperties<elecType, VdwType::Count>().elecEwaldTab |
| template<enum VdwType vdwType> | |
| constexpr bool | ljEwald = EnergyFunctionProperties<ElecType::Count, vdwType>().vdwEwald |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJ_F_ref |
| All the different CPU reference kernel functions. | |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJFsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJPsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombGeom_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombLB_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJ_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJFsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJPsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombGeom_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombLB_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJ_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJFsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJPsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombGeom_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombLB_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJ_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJFsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJPsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombGeom_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombLB_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJ_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJFsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJPsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombGeom_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombLB_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJ_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJFsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJPsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombGeom_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombLB_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJ_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJFsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJPsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombGeom_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecRF_VdwLJEwCombLB_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJ_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJFsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJPsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombGeom_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTab_VdwLJEwCombLB_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJ_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJFsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJPsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombGeom_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_1x1_ElecQSTabTwinCut_VdwLJEwCombLB_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJ_F_ref |
| All the different CPU reference kernel functions. | |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJFsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJPsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombGeom_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombLB_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJ_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJFsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJPsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombGeom_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombLB_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJ_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJFsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJPsw_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombGeom_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombLB_F_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJ_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJFsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJPsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombGeom_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombLB_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJ_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJFsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJPsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombGeom_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombLB_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJ_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJFsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJPsw_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombGeom_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombLB_VF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJ_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJFsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJPsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombGeom_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecRF_VdwLJEwCombLB_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJ_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJFsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJPsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombGeom_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTab_VdwLJEwCombLB_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJ_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJFsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJPsw_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombGeom_VgrpF_ref |
| NbnxmKernelFunc | nbnxn_kernel_4x4_ElecQSTabTwinCut_VdwLJEwCombLB_VgrpF_ref |
| constexpr unsigned int | NBNXN_INTERACTION_MASK_ALL = 0xffffffffU |
| Cluster-pair Interaction masks. More... | |
| constexpr int | c_dBoxZ = 1 |
| Maximum dimensions of grid expressing shifts across PBC. | |
| constexpr int | c_dBoxY = 1 |
| constexpr int | c_dBoxX = 2 |
Higher-level SIMD utility functions, double precision. | |
These include generic functions to work with triplets of data, typically coordinates, and a few utility functions to load and update data in the nonbonded kernels. These functions should be available on all implementations. | |
| static const int | c_simdBestPairAlignmentDouble = 2 |
| Best alignment to use for aligned pairs of double data. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadTranspose (const double *base, const std::int32_t offset[], SimdDouble *v0, SimdDouble *v1, SimdDouble *v2, SimdDouble *v3) |
| Load 4 consecutive double from each of GMX_SIMD_DOUBLE_WIDTH offsets, and transpose into 4 SIMD double variables. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadTranspose (const double *base, const std::int32_t offset[], SimdDouble *v0, SimdDouble *v1) |
| Load 2 consecutive double from each of GMX_SIMD_DOUBLE_WIDTH offsets, and transpose into 2 SIMD double variables. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadUTranspose (const double *base, const std::int32_t offset[], SimdDouble *v0, SimdDouble *v1, SimdDouble *v2) |
| Load 3 consecutive doubles from each of GMX_SIMD_DOUBLE_WIDTH offsets, and transpose into 3 SIMD double variables. More... | |
| template<int align> | |
| static void gmx_simdcall | transposeScatterStoreU (double *base, const std::int32_t offset[], SimdDouble v0, SimdDouble v1, SimdDouble v2) |
| Transpose and store 3 SIMD doubles to 3 consecutive addresses at GMX_SIMD_DOUBLE_WIDTH offsets. More... | |
| template<int align> | |
| static void gmx_simdcall | transposeScatterIncrU (double *base, const std::int32_t offset[], SimdDouble v0, SimdDouble v1, SimdDouble v2) |
| Transpose and add 3 SIMD doubles to 3 consecutive addresses at GMX_SIMD_DOUBLE_WIDTH offsets. More... | |
| template<int align> | |
| static void gmx_simdcall | transposeScatterDecrU (double *base, const std::int32_t offset[], SimdDouble v0, SimdDouble v1, SimdDouble v2) |
| Transpose and subtract 3 SIMD doubles to 3 consecutive addresses at GMX_SIMD_DOUBLE_WIDTH offsets. More... | |
| static void gmx_simdcall | expandScalarsToTriplets (SimdDouble scalar, SimdDouble *triplets0, SimdDouble *triplets1, SimdDouble *triplets2) |
| Expand each element of double SIMD variable into three identical consecutive elements in three SIMD outputs. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadBySimdIntTranspose (const double *base, SimdDInt32 offset, SimdDouble *v0, SimdDouble *v1, SimdDouble *v2, SimdDouble *v3) |
| Load 4 consecutive doubles from each of GMX_SIMD_DOUBLE_WIDTH offsets specified by a SIMD integer, transpose into 4 SIMD double variables. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadUBySimdIntTranspose (const double *base, SimdDInt32 offset, SimdDouble *v0, SimdDouble *v1) |
| Load 2 consecutive doubles from each of GMX_SIMD_DOUBLE_WIDTH offsets (unaligned) specified by SIMD integer, transpose into 2 SIMD doubles. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadBySimdIntTranspose (const double *base, SimdDInt32 offset, SimdDouble *v0, SimdDouble *v1) |
| Load 2 consecutive doubles from each of GMX_SIMD_DOUBLE_WIDTH offsets specified by a SIMD integer, transpose into 2 SIMD double variables. More... | |
| static double gmx_simdcall | reduceIncr4ReturnSum (double *m, SimdDouble v0, SimdDouble v1, SimdDouble v2, SimdDouble v3) |
| Reduce each of four SIMD doubles, add those values to four consecutive doubles in memory, return sum. More... | |
Higher-level SIMD utility functions, single precision. | |
These include generic functions to work with triplets of data, typically coordinates, and a few utility functions to load and update data in the nonbonded kernels. These functions should be available on all implementations, although some wide SIMD implementations (width>=8) also provide special optional versions to work with half or quarter registers to improve the performance in the nonbonded kernels. | |
| static const int | c_simdBestPairAlignmentFloat = 2 |
| Best alignment to use for aligned pairs of float data. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadTranspose (const float *base, const std::int32_t offset[], SimdFloat *v0, SimdFloat *v1, SimdFloat *v2, SimdFloat *v3) |
| Load 4 consecutive floats from each of GMX_SIMD_FLOAT_WIDTH offsets, and transpose into 4 SIMD float variables. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadTranspose (const float *base, const std::int32_t offset[], SimdFloat *v0, SimdFloat *v1) |
| Load 2 consecutive floats from each of GMX_SIMD_FLOAT_WIDTH offsets, and transpose into 2 SIMD float variables. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadUTranspose (const float *base, const std::int32_t offset[], SimdFloat *v0, SimdFloat *v1, SimdFloat *v2) |
| Load 3 consecutive floats from each of GMX_SIMD_FLOAT_WIDTH offsets, and transpose into 3 SIMD float variables. More... | |
| template<int align> | |
| static void gmx_simdcall | transposeScatterStoreU (float *base, const std::int32_t offset[], SimdFloat v0, SimdFloat v1, SimdFloat v2) |
| Transpose and store 3 SIMD floats to 3 consecutive addresses at GMX_SIMD_FLOAT_WIDTH offsets. More... | |
| template<int align> | |
| static void gmx_simdcall | transposeScatterIncrU (float *base, const std::int32_t offset[], SimdFloat v0, SimdFloat v1, SimdFloat v2) |
| Transpose and add 3 SIMD floats to 3 consecutive addresses at GMX_SIMD_FLOAT_WIDTH offsets. More... | |
| template<int align> | |
| static void gmx_simdcall | transposeScatterDecrU (float *base, const std::int32_t offset[], SimdFloat v0, SimdFloat v1, SimdFloat v2) |
| Transpose and subtract 3 SIMD floats to 3 consecutive addresses at GMX_SIMD_FLOAT_WIDTH offsets. More... | |
| static void gmx_simdcall | expandScalarsToTriplets (SimdFloat scalar, SimdFloat *triplets0, SimdFloat *triplets1, SimdFloat *triplets2) |
| Expand each element of float SIMD variable into three identical consecutive elements in three SIMD outputs. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadBySimdIntTranspose (const float *base, SimdFInt32 offset, SimdFloat *v0, SimdFloat *v1, SimdFloat *v2, SimdFloat *v3) |
| Load 4 consecutive floats from each of GMX_SIMD_FLOAT_WIDTH offsets specified by a SIMD integer, transpose into 4 SIMD float variables. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadUBySimdIntTranspose (const float *base, SimdFInt32 offset, SimdFloat *v0, SimdFloat *v1) |
| Load 2 consecutive floats from each of GMX_SIMD_FLOAT_WIDTH offsets (unaligned) specified by SIMD integer, transpose into 2 SIMD floats. More... | |
| template<int align> | |
| static void gmx_simdcall | gatherLoadBySimdIntTranspose (const float *base, SimdFInt32 offset, SimdFloat *v0, SimdFloat *v1) |
| Load 2 consecutive floats from each of GMX_SIMD_FLOAT_WIDTH offsets specified by a SIMD integer, transpose into 2 SIMD float variables. More... | |
| static float gmx_simdcall | reduceIncr4ReturnSum (float *m, SimdFloat v0, SimdFloat v1, SimdFloat v2, SimdFloat v3) |
| Reduce each of four SIMD floats, add those values to four consecutive floats in memory, return sum. More... | |
SIMD data types | |
The actual storage of these types is implementation dependent. The documentation is generated from the reference implementation, but for normal usage this will likely not be what you are using. | |
| typedef SimdFloat | SimdReal |
| Real precision floating-point SIMD datatype. More... | |
| typedef SimdFBool | SimdBool |
| Boolean SIMD type for usage with SimdReal. More... | |
| typedef SimdFInt32 | SimdInt32 |
| 32-bit integer SIMD type. More... | |
| typedef SimdFIBool | SimdIBool |
| Boolean SIMD type for usage with SimdInt32. More... | |
| typedef Simd4Float | Simd4Real |
| Real precision floating-point SIMD4 datatype. More... | |
| typedef Simd4FBool | Simd4Bool |
| Boolean SIMD4 type for usage with SimdReal. More... | |
| const int | c_simdBestPairAlignment = c_simdBestPairAlignmentFloat |
High-level SIMD proxy objects to disambiguate load/set operations | |
| using | Simd4NFloat = SimdFloat |
| using | Simd4NDouble = SimdDouble |
| using | Simd4NReal = Simd4NFloat |
| template<typename T > | |
| static std::remove_const_t< T > | load (const internal::SimdTraitsT< T > *m) |
| Load function that returns SIMD or scalar. More... | |
| template<typename T > | |
| static T | load (const std::enable_if_t< std::is_arithmetic_v< T >, T > *m) |
| template<typename T , size_t N> | |
| static T gmx_simdcall | load (const AlignedArray< internal::SimdTraitsT< T >, N > &m) |
| template<typename T > | |
| static T | loadU (const internal::SimdTraitsT< T > *m) |
| Load function that returns SIMD or scalar based on template argument. More... | |
| template<typename T > | |
| static T | loadU (const std::enable_if_t< std::is_arithmetic_v< T >, T > *m) |
| template<typename T , size_t N> | |
| static T gmx_simdcall | loadU (const AlignedArray< internal::SimdTraitsT< T >, N > &m) |
| static SimdSetZeroProxy gmx_simdcall | setZero () |
| Helper function to set any SIMD or scalar variable to zero. More... | |
| template<typename T > | |
| T | load (const internal::Simd4TraitsT< T > *m) |
| template<typename T > | |
| T | loadU (const internal::Simd4TraitsT< T > *m) |
| static Simd4NFloat gmx_simdcall | loadUNDuplicate4 (const float *f) |
| static Simd4NFloat gmx_simdcall | load4DuplicateN (const float *f) |
| static Simd4NFloat gmx_simdcall | loadU4NOffset (const float *f, int) |
| static Simd4NDouble gmx_simdcall | loadUNDuplicate4 (const double *f) |
| static Simd4NDouble gmx_simdcall | load4DuplicateN (const double *f) |
| static Simd4NDouble gmx_simdcall | loadU4NOffset (const double *f, int) |
| using gmx::AlignedAllocator = typedef Allocator<T, AlignedAllocationPolicy> |
Aligned memory allocator.
| T | Type of objects to allocate |
This convenience partial specialization can be used for the optional allocator template parameter in standard library containers, which is necessary e.g. to use SIMD aligned load and store operations on data in those containers. The memory will always be aligned according to the behavior of AlignedAllocationPolicy.
| using gmx::BoxMatrix = typedef std::array<std::array<real, DIM>, DIM> |
A 3x3 matrix data type useful for simulation boxes.
| typedef std::vector< hsize_t > gmx::DataSetDims |
Dimensions of a HDF5 data set.
Dimensions of HDF5 data sets and spaces.
Default fast and accurate random engine in Gromacs.
This engine will return 2*2^64 random results using the default gmx::RandomDomain::Other stream, and can be initialized with a single seed argument without having to remember empty template angle brackets.
| using gmx::HostAllocator = typedef Allocator<T, HostAllocationPolicy> |
Memory allocator that uses HostAllocationPolicy.
| T | Type of objects to allocate |
This convenience partial specialization can be used for the optional allocator template parameter in standard library containers whose memory may be used for e.g. GPU transfers. The memory will always be allocated according to the behavior of HostAllocationPolicy.
| using gmx::Index = typedef std::ptrdiff_t |
Integer type for indexing into arrays or vectors.
Same as ptrdiff_t.
| using gmx::Matrix3x3 = typedef BasicMatrix3x3<real> |
Three-by-three real number matrix.
| using gmx::PageAlignedAllocator = typedef Allocator<T, PageAlignedAllocationPolicy> |
PageAligned memory allocator.
| T | Type of objects to allocate |
This convenience partial specialization can be used for the optional allocator template parameter in standard library containers, which is necessary for locking memory pages for asynchronous transfer between a GPU device and the host. The memory will always be aligned according to the behavior of PageAlignedAllocationPolicy.
| using gmx::PairlistEntry = typedef std::pair<std::pair<int, int>, int> |
For compatibility with pairlist data structure in MDModulesPairlistConstructedSignal. Contains pairs like ((atom1, atom2), shiftIndex).
| typedef std::random_device gmx::RandomDevice |
Random device.
For now this is identical to the standard library, but since we use the GROMACS random module for all other random engines and distributions it is convenient to have this too in the same module.
| typedef Simd4FBool gmx::Simd4Bool |
Boolean SIMD4 type for usage with SimdReal.
This type is only available if GMX_SIMD4_HAVE_REAL is 1.
If GMX_DOUBLE is 1, this will be set to Simd4DBool internally, otherwise Simd4FBool. This is necessary since some SIMD implementations use bitpatterns for marking truth, so single- vs. double precision booleans are not necessarily exchangable. As long as you just use this type you will not have to worry about precision.
| typedef Simd4Float gmx::Simd4Real |
Real precision floating-point SIMD4 datatype.
This type is only available if GMX_SIMD4_HAVE_REAL is 1.
Simd4Double if GMX_DOUBLE is 1, otherwise Simd4Float.
| typedef SimdFBool gmx::SimdBool |
Boolean SIMD type for usage with SimdReal.
This type is only available if GMX_SIMD_HAVE_REAL is 1.
If GMX_DOUBLE is 1, this will be set to SimdDBool internally, otherwise SimdFBool. This is necessary since some SIMD implementations use bitpatterns for marking truth, so single- vs. double precision booleans are not necessarily exchangable. As long as you just use this type you will not have to worry about precision.
See SimdIBool for an explanation of real vs. integer booleans.
| typedef SimdFIBool gmx::SimdIBool |
Boolean SIMD type for usage with SimdInt32.
This type is only available if GMX_SIMD_HAVE_INT32_ARITHMETICS is 1.
If GMX_DOUBLE is 1, this will be set to SimdDIBool internally, otherwise SimdFIBool. This is necessary since some SIMD implementations use bitpatterns for marking truth, so single- vs. double precision booleans are not necessarily exchangable, and while a double-precision boolean might be represented with a 64-bit mask, the corresponding integer might only use a 32-bit mask.
We provide conversion routines for these cases, so the only thing you need to keep in mind is to use SimdBool when working with SimdReal while you pick SimdIBool when working with SimdInt32 .
To convert between them, use cvtB2IB and cvtIB2B.
| typedef SimdFInt32 gmx::SimdInt32 |
32-bit integer SIMD type.
If GMX_DOUBLE is 1, this will be set to SimdDInt32 internally, otherwise SimdFInt32. This might seem a strange implementation detail, but it is because some SIMD implementations use different types/widths of integers registers when converting from double vs. single precision floating point. As long as you just use this type you will not have to worry about precision.
| typedef SimdFloat gmx::SimdReal |
Real precision floating-point SIMD datatype.
This type is only available if GMX_SIMD_HAVE_REAL is 1.
SimdDouble if GMX_DOUBLE is 1, otherwise SimdFloat.
| anonymous enum |
Kinds of Van der Waals treatments in NBNxM SIMD kernels.
The LJCUT_COMB refers to the LJ combination rule for the short range. The EWALDCOMB refers to the combination rule for the grid part. vdwktNR is the number of VdW treatments for the SIMD kernels. vdwktNR_ref is the number of VdW treatments for the C reference kernels. These two numbers differ, because currently only the reference kernels support LB combination rules for the LJ-Ewald grid part.
|
strong |
Indicates which FMM backend is active based on MDP configuration.
Only one FMM backend should be active at a time. This enum reflects the active backend as determined by user-specified MDP options.
| Enumerator | |
|---|---|
| Inactive |
No FMM backend is active. |
| ExaFmm |
ExaFMM backend is active. |
| FMSolvr |
FMSolvr backend is active. |
|
strong |
|
strong |
|
strong |
|
strong |
Enum with the AWH variables to write.
|
strong |
|
strong |
Checkpoint signals.
Signals set and read by CheckpointHandler. Possible signals include
|
strong |
The types of kernel for calculating the distance between pairs of atom clusters.
|
strong |
Options for checking bonded interactions.
These values must match the bool false and true used for mdrun -ddcheck
| Enumerator | |
|---|---|
| ExcludeZeroLimit |
Do not check bonded interactions that go to 0 for large distances. |
| All |
Check all bonded interactions. |
|
strong |
The options for the domain decomposition MPI task ordering.
|
strong |
|
strong |
The methods that determine how two densities are compared to one another.
|
strong |
Class enum to describe the different logical streams used for GPU work.
Whether the actual streams differ is an implementation detail of the manager class.
|
strong |
|
strong |
Nbnxm electrostatic GPU kernel flavors.
Types of electrostatics implementations available in the GPU non-bonded force kernels. These represent both the electrostatics types implemented by the kernels (cut-off, RF, and Ewald - a subset of what's defined in enums.h) as well as encode implementation details analytical/tabulated and single or twin cut-off (for Ewald kernels). Note that the cut-off and RF kernels have only analytical flavor and unlike in the CPU kernels, the tabulated kernels are ATM Ewald-only. The None option is used when Coulomb interactions are handled by an MD module, such as FMM.
The row-order of pointers to different electrostatic kernels defined in nbnxn_cuda.cu by the nb_*_kfunc_ptr function pointer table should match the order of enumerated types below.
|
strong |
|
strong |
|
strong |
|
strong |
|
strong |
|
strong |
|
strong |
Enum describing GPU-aware support in underlying MPI library.
Ordinal, so that the lowest value can represent the minimal level of support found across a set of devices, perhaps across nodes or ranks.
| Enumerator | |
|---|---|
| NotSupported |
GPU-aware support NOT available or not known. |
| Forced |
GPU-aware support forced using env variable. |
| Supported |
GPU-aware support available. |
| Count |
Conventional final enum value. |
|
strong |
|
strong |
State of graph.
|
strong |
|
strong |
|
strong |
|
strong |
|
strong |
Enum for types of IMD messages.
We use the same records as the NAMD/VMD IMD implementation.
|
strong |
|
strong |
List of type of Nbnxm kernel coulomb type implementations.
|
strong |
|
strong |
|
strong |
The type of density data stored in an mrc file. As named in "EMDB Map Distribution Format Description Version 1.01 (c) emdatabank.org 2014" Modes 0-4 are defined by the standard. NOTE only mode 2 is currently implemented and used.
|
strong |
Force group available for selection for multiple time step integration.
|
strong |
|
strong |
|
strong |
|
strong |
Sets the number of different temperature coupling values.
This is needed to template the kernel
| Enumerator | |
|---|---|
| None |
No temperature coupling. |
| Single |
Single T-scaling value (one group) |
| Multiple |
Multiple T-scaling values, need to use T-group indices. |
| Count |
Number of valid values. |
|
strong |
| enum gmx::OptionFlag : uint64_t |
Flags for options.
These flags are not part of the public interface, even though they are in an installed header. They are needed in a few template class implementations.
| Enumerator | |
|---|---|
| efOption_Set |
Option has been set. |
| efOption_HasDefaultValue |
The current value of the option is a programmatic default value. |
| efOption_ExplicitDefaultValue |
An explicit default value has been provided for the option. |
| efOption_ClearOnNextSet |
Next assignment to the option clears old values. This flag is set when a new option source starts, such that values from the new source will overwrite old ones. |
| efOption_Required |
Option is required to be set. |
| efOption_MultipleTimes |
Option can be specified multiple times. |
| efOption_Hidden |
Option is hidden from standard help. |
| efOption_Vector |
Option value is a vector, but a single value is also accepted.
|
| efOption_DefaultValueIfSetExists |
Option has a defaultValueIfSet() specified. |
| efOption_NoDefaultValue |
Option does not support default values. |
| efOption_DontCheckMinimumCount |
Storage object does its custom checking for minimum value count. If this flag is set, the class derived from OptionStorageTemplate should implement processSetValues(), processAll(), and possible other functions it provides such that it always fails if not enough values are provided. This is useful to override the default check, which is done in OptionStorageTemplate::processSet(). |
|
strong |
|
strong |
Helper enum for pinning policy of the allocation of HostAllocationPolicy.
For an efficient non-blocking transfer (e.g. to a GPU), the memory pages for a buffer need to be pinned to a physical page. Aligning such buffers to a physical page should miminize the number of pages that need to be pinned. However, some buffers that may be used for such transfers may also be used in either GROMACS builds or run paths that cannot use such a device, so the policy can be configured so that the resource consumption is no higher than required for correct, efficient operation in all cases.
|
strong |
|
strong |
Enumerated values for fixed part of random seed (domain)
Random numbers are used in many places in GROMACS, and to avoid identical streams the random seeds should be different. Instead of keeping track of several different user-provided seeds, it is better to use the fact that generators like ThreeFry take two 64-bit keys, and combine a general user-provided 64-bit random seed with a second constant value from this list to make each stream guaranteed unique.
|
strong |
Control whether reduction is required soon.
| Enumerator | |
|---|---|
| Soon |
Reduce whenever the runner next checks with the ObservablesReducer. |
| Eventually |
Reduce whenever the runner next checks with the ObservablesReducer after some module requires reduction Soon. |
|
strong |
Reset signals.
Signals set and read by ResetHandler. Possible signals include
|
strong |
|
strong |
Enumerated options for SIMD architectures.
|
strong |
|
strong |
Enumeration for describing how mdrun is (re)starting.
|
strong |
Stop signals.
Signals that stop conditions can send to all ranks. Possible signals include
|
strong |
Enum class for whether StringToEnumValueConverter will strip strings of leading and trailing whitespace before comparison.
| Enumerator | |
|---|---|
| No |
Do not strip strings. |
| Yes |
Strip strings. |
|
strong |
Nbnxm VdW GPU kernel flavors.
The enumerates values correspond to the LJ implementations in the GPU non-bonded kernels.
The column-order of pointers to different electrostatic kernels defined in nbnxn_cuda_ocl.cpp/.cu by the nb_*_kfunc_ptr function pointer table should match the order of enumerated types below.
|
strong |
|
strong |
|
inlinestatic |
Convert sigma and epsilon VdW parameters to c6,c12 pair.
Fetch C6 grid contribution coefficients and return the product of these.
Calculate force and energy for a pair of atoms, VdW force-switch flavor.
| gmx::__launch_bounds__ | ( | threadsPerBlock | ) |
HIP bucket sci sort kernel.
Sorts sci in order from most to least neighbours, using the count sort algorithm
Unlike the cpu version of sci sort, this kernel uses counts which only contain pairs which have not been masked out, giving an ordering which more accurately represents the work which will be done in the non bonded force kernel. The counts themselves are generated in the prune kernel.
Inputs:
| gmx::__launch_bounds__ | ( | c_clSizeSq< pairlistType > * | threadZ, |
| minBlocksPp | |||
| ) |
Prune-only kernel for NBNXM.
The number of threads per block is always c_clSizeSq, so we can use it here without having to pass another template argument. The remaining multipliers are architecture and kernel flavor specific and need to be passed in.
| gmx::__launch_bounds__ | ( | c_clSizeSq< pairlistType > * | nthreadZ, |
| minBlocksPerMp | |||
| ) |
Main kernel for NBNXM.
|
inlinestatic |
Float Floating-point abs().
| a | any floating point values |
|
inlinestatic |
double doubleing-point abs().
| a | any doubleing point values |
|
inlinestatic |
Float acos.
| x | The argument to evaluate acos for |
|
inlinestatic |
Double acos.
| x | The argument to evaluate acos for |
|
inlinestatic |
Double acos, but with single accuracy.
| x | The argument to evaluate acos for |
| void gmx::addEmbeddedNBExclusions | ( | gmx_mtop_t * | mtop, |
| const std::set< int > & | embeddedIndices, | ||
| const MDLogger & | logger | ||
| ) |
Build exclusion list for non-bonded interactions between embedded atoms.
Adds embedded atoms to mtop->intermolecularExclusionGroup
| [in,out] | mtop | topology to be modified |
| [in] | embeddedIndices | set with global indices of embedded atoms |
| [in] | logger | MDLogger for logging info about modifications |
|
inline |
Add a comment for an mdp value with a module-prefixed name.
| [in] | builder | Builder for KVT output |
| [in] | moduleName | Module name prefix |
| [in] | optionName | Suffix of the mdp option name |
| [in] | comment | Comment text to write |
| void gmx::addMdpOutputValue | ( | KeyValueTreeObjectBuilder * | builder, |
| std::string_view | moduleName, | ||
| std::string_view | optionName, | ||
| const ValueType & | optionValue | ||
| ) |
Add an mdp value to output KVT with a module-prefixed name.
| ValueType | Type of the value described by the option |
| [in] | builder | Builder for KVT output |
| [in] | moduleName | Module name prefix |
| [in] | optionName | Suffix of the mdp option name |
| [in] | optionValue | Value to write |
| void gmx::addMdpTransformFromString | ( | IKeyValueTreeTransformRules * | rules, |
| TransformWithFunctionType | transformationFunction, | ||
| std::string_view | moduleName, | ||
| std::string_view | optionName | ||
| ) |
Helper to declare mdp transform rules.
Enforces uniform mdp option transformation for a given module.
| ToType | type to be transformed to |
| TransformWithFunctionType | type of transformation function from std::string to ToType |
| [in] | rules | KVT transformation rules |
| [in] | transformationFunction | function to transform string to ToType |
| [in] | moduleName | module name prepended to the option name |
| [in] | optionName | suffix of the mdp option name |
|
static |
Adds forces in SIMD packed layout to an RVec array.
| packSize | The stride of the packs in out |
| [in] | out | Nbnxm thread output data containing the forces to be added |
| [in] | a0 | The start of the atom range to add forces for |
| [in] | a1 | The end of the atom range to add forces for |
| [in] | cellIndices | List of NBNxM cell indices, when nullptr the identity mapping is used |
| [in,out] | forces | The force buffer to add into |
|
static |
Creates a new container object with the user requested IOutputAdapter derived methods attached to it.
| [in] | requirements | Specifications for modules to add. |
| [in] | atoms | Local copy of atom information to use. |
| [in] | sel | Selection to use for choosing atoms to write out. |
| [in] | abilities | Specifications for what the output method can do. |
|
inline |
Add constraint to splitMap with all constraints coupled to it.
Adds the constraint c from the constrain list iatoms to the map splitMap if it was not yet added. Then goes through all the constraints coupled to c and calls itself recursively. This ensures that all the coupled constraints will be added to neighboring locations in the final data structures on the device, hence mapping all coupled constraints to the same thread block. A value of -1 in the splitMap is used to flag that constraint was not yet added to the splitMap.
| [in] | iatoms | The list of constraints. |
| [in] | stride | Number of elements per constraint in iatoms. |
| [in] | atomsAdjacencyList | Information about connections between atoms. |
| [out] | splitMap | Map of sequential constraint indexes to indexes to be on the device |
| [in] | c | Sequential index for constraint to consider adding. |
| [in,out] | currentMapIndex | The rolling index for the constraints mapping. |
|
static |
Modify atoms information in coordinate frame to fit output selection.
Changes the information contained in the coordinate frame t_atoms struct to match the selection provided to the module.
| [in] | atoms | Pointer to original t_atoms. |
| [in] | selectionAtoms | Pointer to local atoms. |
| [in] | sel | Reference to selection. |
| bool gmx::advancePointInSubgrid | ( | const BiasGrid & | grid, |
| const awh_ivec | subgridOrigin, | ||
| const awh_ivec | subgridNpoints, | ||
| int * | gridPointIndex | ||
| ) |
Find the next grid point in the sub-part of the grid given a starting point.
The given grid point index is updated to the next valid grid point index by traversing the sub-part of the grid, here termed the subgrid. Since the subgrid range might extend beyond the actual size of the grid, the subgrid is traversed until a point both in the subgrid and grid is found. If no point is found, the function returns false and the index is not modified. The starting point needs to be inside of the subgrid. However, if this index is not given, meaning < 0, then the search is initialized at the subgrid origin, i.e. in this case the "next" grid point index is defined to be the first common grid/subgrid point.
| [in] | grid | The grid. |
| [in] | subgridOrigin | Vector locating the subgrid origin relative to the grid origin. |
| [in] | subgridNpoints | Number of points along each subgrid dimension. |
| [in,out] | gridPointIndex | Pointer to the starting/next grid point index. |
|
static |
Polling wait for either of the PME or nonbonded GPU tasks.
Instead of a static order in waiting for GPU tasks, this function polls checking which of the two tasks completes first, and does the associated force buffer reduction overlapped with the other task. By doing that, unlike static scheduling order, it can always overlap one of the reductions, regardless of the GPU task completion order.
| [in] | nbv | Nonbonded verlet structure |
| [in,out] | pmedata | PME module data |
| [in,out] | forceOutputsNonbonded | Force outputs for the non-bonded forces and shift forces |
| [in,out] | forceOutputsPme | Force outputs for the PME forces and virial |
| [in,out] | enerd | Energy data structure results are reduced into |
| [in] | lambdaQ | The Coulomb lambda of the current system state. |
| [in] | stepWork | Step schedule flags |
| [in] | simulationWork | Simulation schedule flags |
| [in] | wcycle | The wallcycle structure |
|
inlinestatic |
Bitwise andnot for two scalar float variables.
| a | data1 |
| b | data2 |
|
inlinestatic |
Bitwise andnot for two scalar double variables.
| a | data1 |
| b | data2 |
|
inlinestatic |
Bitwise andnot for two scalar integer variables.
| a | data1 |
| b | data2 |
|
static |
Checks whether any bias scales the target distribution based on the AWH friction metric.
| [in] | awhParams | The AWH params to check. |
|
static |
Checks whether any dimension uses the given coordinate provider type.
| [in] | awhBiasParams | The bias params to check. |
| [in] | awhCoordProvider | The type of coordinate provider |
|
static |
Checks whether any dimension uses the given coordinate provider type.
| [in] | awhParams | The AWH params to check. |
| [in] | awhCoordProvider | The type of coordinate provider |
|
inlinestatic |
Returns if the boolean is true.
| a | Logical variable. |
| void gmx::applyGlobalSimulationState | ( | const SimulationInput & | simulationInput, |
| PartialDeserializedTprFile * | partialDeserializedTpr, | ||
| t_state * | globalState, | ||
| t_inputrec * | inputrec, | ||
| gmx_mtop_t * | globalTopology | ||
| ) |
Get the global simulation input.
Acquire global simulation data structures from the SimulationInput handle. Note that global data is returned in the calling thread. In parallel computing contexts, the client is responsible for calling only where needed.
Example: if (SIMMAIN(cr)) { // Only the main rank has the global state globalState = globalSimulationState(simulationInput);
// Read (nearly) all data required for the simulation applyGlobalInputRecord(simulationInput, inputrec); applyGlobalTopology(simulationInput, &mtop); }
| void gmx::applyLocalState | ( | const SimulationInput & | simulationInput, |
| t_fileio * | logfio, | ||
| const MpiComm & | mpiCommSimulation, | ||
| t_inputrec * | ir, | ||
| t_state * | state, | ||
| ObservablesHistory * | observablesHistory, | ||
| bool | reproducibilityRequested, | ||
| const MDModulesNotifiers & | notifiers, | ||
| gmx::ReadCheckpointDataHolder * | modularSimulatorCheckpointData, | ||
| bool | useModularSimulator | ||
| ) |
Initialize local stateful simulation data.
Establish an invariant for the simulator at a trajectory point. Call on all ranks (after domain decomposition and task assignments).
After this call, the simulator has all of the information it will receive in order to advance a trajectory from the current step. Checkpoint information has been applied, if applicable, and stateful data has been (re)initialized.
|
inlinestatic |
float asin.
| x | The argument to evaluate asin for |
|
inlinestatic |
Double asin.
| x | The argument to evaluate asin for |
|
inlinestatic |
Double asin, but with single accuracy.
| x | The argument to evaluate asin for |
|
inlinestatic |
Assert that the matrix m describes a simulation box.
The GROMACS convention is that all simulation box descriptions are normalized to have zero entries in the upper triangle. This function asserts if that is not true.
|
inlinestatic |
Assert that the matrix m describes a simulation box.
The GROMACS convention is that all simulation box descriptions are normalized to have zero entries in the upper triangle. This function asserts if that is not true.
|
static |
Here we try to assign all vsites that are in our local range.
Our task local atom range is tData->rangeStart - tData->rangeEnd. Vsites that depend only on local atoms, as indicated by taskIndex[]==thread, are assigned to task tData->ilist. Vsites that depend on non-local atoms but not on other vsites are assigned to task tData->id_task.ilist. taskIndex[] is set for all vsites in our range, either to our local tasks or to the single last task as taskIndex[]=2*nthreads.
|
inlinestatic |
Float atan.
| x | The argument to evaluate atan for |
|
inlinestatic |
Double atan.
| x | The argument to evaluate atan for |
|
inlinestatic |
Float atan2(y,x).
| y | Y component of vector, any quartile |
| x | X component of vector, any quartile |
|
inlinestatic |
Double atan2(y,x).
| y | Y component of vector, any quartile |
| x | X component of vector, any quartile |
|
inlinestatic |
Double atan2(y,x), but with single accuracy.
| y | Y component of vector, any quartile |
| x | X component of vector, any quartile |
|
inlinestatic |
Double atan, but with single accuracy.
| x | The argument to evaluate atan for |
|
inlinestatic |
Convert atom locality to interaction locality.
In the current implementation the this is straightforward conversion: local to local, non-local to non-local.
| [in] | atomLocality | Atom locality specifier |
|
static |
Return an estimate of the average kinetic energy or 0 when unreliable.
| groupOptions | Group options, containing T-coupling options |
| constexpr std::enable_if_t<BasicMdspan::is_always_contiguous(), typename BasicMdspan::pointer> gmx::begin | ( | const BasicMdspan & | basicMdspan | ) |
Free begin function addressing memory of a contiguously laid out basic_mdspan.
| void gmx::bench | ( | int | sizeFactor, |
| const NbnxmKernelBenchOptions & | options | ||
| ) |
Sets up and runs one or more Nbnxm kernel benchmarks.
The simulated system is a box of 1000 SPC/E water molecules scaled by the factor sizeFactor, which has to be a power of 2. One or more benchmarks are run, as specified by options. Benchmark settings and timings are printed to stdout.
| [in] | sizeFactor | How much should the system size be increased. |
| [in] | options | How the benchmark will be run. |
| void gmx::biasesAreCompatibleForSharingBetweenSimulations | ( | const AwhParams & | awhParams, |
| ArrayRef< const size_t > | pointSize, | ||
| const BiasSharing & | biasSharing | ||
| ) |
Checks whether biases are compatible for sharing between simulations, throws when not.
Should be called simultaneously on the main rank of every simulation. Note that this only checks for technical compatibility. It is up to the user to check that the sharing physically makes sense. Throws an exception when shared biases are not compatible.
| [in] | awhParams | The AWH parameters. |
| [in] | pointSize | Vector of grid-point sizes for each bias. |
| [in] | biasSharing | Object for communication for sharing bias data over simulations. |
|
inlinestatic |
Blend float selection.
| a | First source |
| b | Second source |
| sel | Boolean selector |
|
inlinestatic |
Blend double selection.
| a | First source |
| b | Second source |
| sel | Boolean selector |
|
inlinestatic |
Blend integer selection.
| a | First source |
| b | Second source |
| sel | Boolean selector |
| void gmx::blockaToExclusionBlocks | ( | const t_blocka * | b, |
| gmx::ArrayRef< ExclusionBlock > | b2 | ||
| ) |
Convert the exclusions.
Convert t_blocka exclusions in b into ExclusionBlock form and include them in b2.
| [in] | b | Exclusions in t_blocka form. |
| [in,out] | b2 | ExclusionBlocks to populate with t_blocka exclusions. |
| std::unique_ptr< BoxDeformation > gmx::buildBoxDeformation | ( | const Matrix3x3 & | initialBox, |
| DDRole | ddRole, | ||
| NumRanks | numRanks, | ||
| MPI_Comm | communicator, | ||
| const t_inputrec & | inputrec | ||
| ) |
Factory function for box deformation module.
If the inputrec specifies the use of box deformation during the update phase, communicates the initialBox from SIMMAIN to other ranks, and constructs and returns an object to manage that update.
| NotImplementedError | if the inputrec specifies an unsupported combination. |
| std::vector< int > gmx::buildEmbeddedAtomNumbers | ( | const gmx_mtop_t & | mtop | ) |
Builds and returns a vector of atom numbers for all atoms in mtop.
| [in] | mtop | topology to be processed |
| std::vector< LinkFrontierAtom > gmx::buildLinkFrontier | ( | gmx_mtop_t * | mtop, |
| const std::set< int > & | embeddedIndices, | ||
| const std::vector< bool > & | isEmbeddedBlock, | ||
| const MDLogger & | logger | ||
| ) |
Builds link frontier vector with pairs of atoms indicting broken embedded - MM chemical bonds.
Also performs search of constrained bonds within embedded subsystem.
| [in,out] | mtop | topology to be modified |
| [in] | embeddedIndices | set with global indices of embedded atoms |
| [in] | isEmbeddedBlock | vector with flags for embedded atom-containing blocks |
| [in] | logger | MDLogger for logging info about modifications |
| bool gmx::buildSupportsListedForcesGpu | ( | std::string * | error | ) |
Checks whether the GROMACS build allows to compute bonded interactions on a GPU.
| [out] | error | If non-null, the diagnostic message when bondeds cannot run on a GPU. |
| std::bad_alloc | when out of memory. |
| constexpr bool gmx::c_avoidFloatingPointAtomics | ( | PairlistType | layoutType | ) |
Should we avoid FP atomics to the same location from the same work-group?
Intel GPUs without native floating-point operations emulate them via CAS-loop, which is very, very slow when two threads from the same group write to the same global location. We don't specialize the kernels by vendor, so we use c_clSize == 4 as a proxy to detect such devices.
|
inlinestatic |
Calculates the amount of shared memory required by the prune kernel.
Note that for the sake of simplicity we use the CUDA terminology "shared memory" for OpenCL local memory.
| [in] | num_threads_z | cjPacked concurrency equal to the number of threads/work items in the 3-rd dimension. |
|
static |
Computes the whole plus half bounding boxes for packed coordinates.
| packSize | The pack size for the coordinates, also the number of atoms per cell |
| [in] | numAtoms | The actual number of atoms in this cell |
| [in] | x | Packed coodinates |
| [out] | bb | Pointer to the bounding box for the whole cell |
| [out] | bbj | Pointer to the bounding boxes for the two halves of the cell |
|
static |
Computes the bounding box for packed coordinates.
| packSize | The pack size for the coordinates, also the number of atoms per cell |
| [in] | numAtoms | The actual number of atoms in this cell |
| [in] | x | Packed coodinates |
| [out] | bb | Pointer to the bounding box |
|
static |
Wrapper for calcVerletBufferSize() for determining the pruning cut-off.
| [in] | params | References to most parameters for calcVerletBufferSize() |
| [in] | nstlist | The pruning interval, also used for setting the list lifetime |
| real gmx::calculateAcceptanceWeight | ( | LambdaWeightCalculation | calculationMode, |
| real | lambdaEnergyDifference | ||
| ) |
Calculates the acceptance weight for a lambda state transition.
| [in] | calculationMode | How the lambda weights are calculated |
| [in] | lambdaEnergyDifference | The difference in energy between the two states |
|
inlinestatic |
An early return condition for empty NB GPU workloads.
This is currently used for non-local kernels/transfers only. Skipping the local kernel is more complicated, since the local part of the force array also depends on the non-local kernel. The skip of the local kernel is taken care of separately.
|
inlinestatic |
Float cbrt(x). This is the cubic root.
| x | Argument, should be >= 0. |
|
inlinestatic |
Double cbrt(x). This is the cubic root.
| x | Argument, should be >= 0. |
|
static |
Center positions of NN and MM atoms in the box.
For treatment of the NNP-MM interactions, we assume that the embedding model expects all atom positions to be centered around the NNP region.
| const char * gmx::centerTypeNames | ( | CenteringType | type | ) |
Get names for the different centering types.
| [in] | type | What name needs to be provided. |
| void gmx::changePinningPolicy | ( | PinnableVector * | v, |
| PinningPolicy | pinningPolicy | ||
| ) |
Helper function for changing the pinning policy of a pinnable vector.
If the vector has contents, then a full reallocation and buffer copy are needed if the policy change requires tighter restrictions, and desirable even if the policy change requires looser restrictions. That cost is OK, because GROMACS will do this operation very rarely (e.g. when auto-tuning and deciding to switch whether a task will run on a GPU, or not).
| void gmx::checkAwhParams | ( | const AwhParams & | awhParams, |
| const t_inputrec & | inputrec, | ||
| WarningHandler * | wi | ||
| ) |
Check the AWH parameters.
| [in] | awhParams | The AWH parameters. |
| [in] | inputrec | Input parameter struct. |
| [in,out] | wi | Struct for bookeeping warnings. |
| void gmx::checkConstrainedBonds | ( | gmx_mtop_t * | mtop, |
| const std::set< int > & | embeddedIndices, | ||
| const std::vector< bool > & | isEmbeddedBlock, | ||
| WarningHandler * | wi | ||
| ) |
Checks for constrained bonds within embedded subsystem.
Provides warnings via WarningHandler if any are found. Separated from buildLinkFrontier for better modularity.
| [in,out] | mtop | topology to be modified |
| [in] | embeddedIndices | set with global indices of embedded atoms |
| [in] | isEmbeddedBlock | vector with flags for embedded atom-containing blocks |
| [in] | wi | WarningHandler for handling warnings |
|
inline |
Check if API returned an error and throw an exception with information on it.
| [in] | deviceError | The error to assert hipSuccess on. |
| [in] | errorMessage | Undecorated error message. |
| InternalError | if deviceError is not a success. |
|
static |
Check whether the ocl_gpu_device is suitable for use by mdrun.
Runs sanity checks: checking that the runtime can compile a dummy kernel and this can be executed; Runs compatibility checks verifying the device OpenCL version requirement and vendor/OS support.
| [in] | deviceId | The runtime-reported numeric ID of the device. |
| [in] | deviceInfo | The device info pointer. |
|
static |
Check if the RDRAND random device functioning correctly.
Due to a bug in AMD Ryzen microcode, RDRAND may always return -1 (0xFFFFFFFF). To avoid that, fall back to using PRNG instead of RDRAND if this happens.
|
static |
Check if the starting configuration is consistent with the given interval.
| [in] | awhParams | AWH parameters. |
| [in,out] | wi | Struct for bookeeping warnings. |
|
static |
Checks the kernel setup.
Returns an error string when the kernel is not available.
| GpuAwareMpiStatus gmx::checkMpiCudaAwareSupport | ( | ) |
Wrapper on top of MPIX_Query_cuda_support() For MPI implementations which don't support this function, it returns NotSupported. Even when an MPI implementation does support this function, MPI library might not be robust enough to detect CUDA-aware support at runtime correctly e.g. when UCX PML is used or CUDA is disabled at runtime.
| GpuAwareMpiStatus gmx::checkMpiHipAwareSupport | ( | ) |
Wrapper on top of MPIX_Query_hip_support() or MPIX_Query_rocm_support(). For MPI implementations which don't support this function, it returns NotSupported.
Currently, this function is only supported by MPICH and OpenMPI 5.0-rc, and is not very reliable.
| GpuAwareMpiStatus gmx::checkMpiZEAwareSupport | ( | ) |
Wrapper on top of MPIX_Query_ze_support() (for MPICH) or custom logic (for IntelMPI).
For other MPI implementations which perhaps don't support the above function, it returns NotSupported.
| std::vector< std::string > gmx::checkMtsRequirements | ( | const t_inputrec & | ir | ) |
Checks whether the MTS requirements on other algorithms and output frequencies are met.
Note: exits with an assertion failure when ir.useMts == true && haveValidMtsSetup(ir) == false
| [in] | ir | Complete input record |
| VersionEnum gmx::checkpointVersion | ( | const ReadCheckpointData * | checkpointData, |
| const std::string & | key, | ||
| const VersionEnum | programVersion | ||
| ) |
Read a checkpoint version enum variable.
This reads the checkpoint version from file. The read version is returned.
If the read version is more recent than the code version, this throws an error, since we cannot know what has changed in the meantime. Using newer checkpoint files with old code is not a functionality we can offer. Note, however, that since the checkpoint version is saved by module, older checkpoint files of all simulations that don't use that specific module can still be used.
Allowing backwards compatibility of files (i.e., reading an older checkpoint file with a newer version of the code) is in the responsibility of the caller module. They can use the returned file checkpoint version to do that:
const auto fileVersion = checkpointVersion(checkpointData, "version", c_currentVersion);
if (fileVersion >= CheckpointVersion::AddedX)
{
checkpointData->scalar("x", &x_));
}
| VersionEnum | The type of the checkpoint version enum |
| checkpointData | A reading checkpoint data object |
| key | The key under which the version is saved - also used for error output |
| programVersion | The checkpoint version of the current code |
| VersionEnum gmx::checkpointVersion | ( | WriteCheckpointData * | checkpointData, |
| const std::string & | key, | ||
| const VersionEnum | programVersion | ||
| ) |
Write the current code checkpoint version enum variable.
Write the current program checkpoint version to the checkpoint data object. Returns the written checkpoint version to mirror the signature of the reading version.
| VersionEnum | The type of the checkpoint version enum |
| checkpointData | A writing checkpoint data object |
| key | The key under which the version is saved |
| programVersion | The checkpoint version of the current code |
|
static |
This routine checks that the potential energy is finite.
Always checks that the potential energy is finite. If step equals inputrec.init_step also checks that the magnitude of the potential energy is reasonable. Terminates with a fatal error when a check fails. Note that passing this check does not guarantee finite forces, since those use slightly different arithmetics. But in most cases there is just a narrow coordinate range where forces are not finite and energies are finite.
| [in] | step | The step number, used for checking and printing |
| [in] | enerd | The energy data; the non-bonded group energies need to be added to enerd.term[InteractionFunction::PotentialEnergy] before calling this routine |
| [in] | inputrec | The input record |
| void gmx::checkUserGpuIds | ( | ArrayRef< const std::unique_ptr< DeviceInformation >> | deviceInfoList, |
| ArrayRef< const int > | compatibleGpus, | ||
| ArrayRef< const int > | gpuIds | ||
| ) |
Check that all user-selected GPUs are compatible.
Given the gpuIds and hardwareInfo, throw if any selected GPUs is not compatible.
The error is given with a suitable descriptive message, which will have context if this check is done after the hardware detection results have been reported to the user. However, note that only the GPUs detected on the main rank are reported, because of the existing limitations of that reporting.
| [in] | deviceInfoList | Information on the GPUs on this physical node. |
| [in] | compatibleGpus | Vector of GPUs that are compatible |
| [in] | gpuIds | The GPU IDs selected by the user. |
| std::bad_alloc | If out of memory InconsistentInputError If the assigned GPUs are not valid |
|
inlinestatic |
Returns the j-cluster index for the given i-cluster index.
| clusterRatio | The ratio of cluster size, supported are 0.5,1,2, checked at compile time |
| iCluster | The index of the i-cluster |
iCluster
|
inlinestatic |
Returns the j-cluster index given the i-cluster index.
| kernelType | The kernel type |
| jSubClusterIndex | The j-sub-cluster index (0/1), used when size(j-cluster) < size(i-cluster) |
| [in] | ci | The i-cluster index |
|
static |
Clears elements of size and stride numComponentsPerElement.
Only elements with flags in nbat set for index outputIndex are cleared.
|
inlinestatic |
Returns the distance^2 between two bounding boxes.
Uses 4-wide SIMD operations when available.
| [in] | bb_i | First bounding box, has to be aligned for 4-wide SIMD |
| [in] | bb_j | Second bounding box, has to be aligned for 4-wide SIMD |
|
static |
Combines MTS level0 and level1 force buffers into a full and MTS-combined force buffer.
| [in] | numAtoms | The number of atoms to combine forces for |
| [in,out] | forceMtsLevel0 | Input: F_level0, output: F_level0 + F_level1 |
| [in,out] | forceMts | Input: F_level1, output: F_level0 + mtsFactor * F_level1 |
| [in] | mtsFactor | The factor between the level0 and level1 time step |
|
static |
Calculates and returns the derivative of a transformation pull coordinate from a dependent coordinate.
Note #1: this requires that getTransformationPullCoordinateValue() has been called before with the current coordinates.
Note #2: this method will not compute inner derivates. That is taken care of in the regular pull code
| [in] | coord | The (transformation) coordinate to compute the value for |
| [in] | variablePcrdIndex | Pull coordinate index of a variable. |
|
static |
Compute the total bonded interaction count.
| [in] | mtop | The global system topology |
| [in] | ddBondedChecking | Which interactions to check |
| [in] | useUpdateGroups | Whether update groups are in use |
When using domain decomposition without update groups, constraint-type interactions can be split across domains, and so we do not consider them in this correctness check. Otherwise, we include them.
| int gmx::computeFepPeriod | ( | const t_inputrec & | inputrec, |
| const ReplicaExchangeParameters & | replExParams | ||
| ) |
Compute the period at which FEP calculation is performed.
This harmonizes the free energy calculation period specified by nstdhdl with the periods specified by expanded ensemble, replica exchange, and AWH.
| inputrec | The input record |
| replExParams | The replica exchange parameters |
| real gmx::computeMaxUpdateGroupRadius | ( | const gmx_mtop_t & | mtop, |
| ArrayRef< const RangePartitioning > | updateGroupingPerMoleculeType, | ||
| real | temperature | ||
| ) |
Returns the maximum update group radius.
updateGroups is empty, 0 is returned.| [in] | mtop | The system topology |
| [in] | updateGroupingPerMoleculeType | List of update group, size should match the number of moltypes in mtop or be 0 |
| [in] | temperature | The maximum reference temperature, pass -1 when unknown or not applicable |
| RVec gmx::computeQMBoxVec | ( | const RVec & | a, |
| const RVec & | b, | ||
| const RVec & | c, | ||
| real | h, | ||
| real | minNorm, | ||
| real | maxNorm | ||
| ) |
Transforms vector a such as distance from it to the plane defined by vectors b and c will be h minimum length will be milL and maximum length maxL.
| [in] | a | Vector which should be scaled |
| [in] | b | First vector that forms the plane |
| [in] | c | Second vector that forms the plane |
| [in] | h | Distance from the end of a to the plane of (b,c) |
| [in] | minNorm | Minimum norm of vector |
| [in] | maxNorm | Maximum norm of vector |
|
static |
Compute forces and/or energies for special algorithms.
The intention is to collect all calls to algorithms that compute forces on local atoms only and that do not contribute to the local virial sum (but add their virial contribution separately). Eventually these should likely all become ForceProviders. Within this function the intention is to have algorithms that do global communication at the end, so global barriers within the MD loop are as close together as possible.
| [in] | fplog | The log file |
| [in] | mpiComm | The communication object for my group |
| [in] | dd | Pointer to the domdec object, is nullptr when DD is not in use |
| [in] | inputrec | The input record |
| [in] | awh | The Awh module (nullptr if none in use). |
| [in] | enforcedRotation | Enforced rotation module. |
| [in] | imdSession | The IMD session |
| [in] | pull_work | The pull work structure. |
| [in] | step | The current MD step |
| [in] | t | The current time |
| [in,out] | wcycle | Wallcycle accounting struct |
| [in,out] | forceProviders | Pointer to a list of force providers |
| [in] | box | The unit cell |
| [in] | x | The coordinates |
| [in] | mdatoms | Per atom properties |
| [in] | lambda | Array of free-energy lambda values |
| [in] | stepWork | Step schedule flags |
| [in,out] | forceWithVirialMtsLevel0 | Force and virial for MTS level0 forces |
| [in,out] | forceWithVirialMtsLevel1 | Force and virial for MTS level1 forces, can be nullptr |
| [in,out] | enerd | Energy buffer |
| [in,out] | ed | Essential dynamics pointer |
| [in] | didNeighborSearch | Tells if we did neighbor searching this step, used for ED sampling |
Remove didNeighborSearch, which is used incorrectly.
Convert all other algorithms called here to ForceProviders.
| void gmx::constrain_coordinates | ( | gmx::Constraints * | constr, |
| bool | computeRmsd, | ||
| int64_t | step, | ||
| t_state * | state, | ||
| ArrayRefWithPadding< RVec > | xp, | ||
| real * | dhdlambda, | ||
| bool | computeVirial, | ||
| tensor | constraintsVirial | ||
| ) |
Constrain the coordinates.
Constrain the coordinates xp using reference coordinates in state. When present, the velocities in state are also constrained. The dhdlambda contribution has to be added to the bonded interactions.
| [in,out] | constr | The constraints object |
| [in] | computeRmsd | Tells whether the constraint RMS deviation should be computed |
| [in] | step | The integration step index |
| [in,out] | state | The state, x is read and halo data updated, v is constrained |
| [in,out] | xp | The coordinates to constrain |
| [out] | dhdlambda | The dHdlambda contraint contribution is returned in this |
| [in] | computeVirial | Whether the constraint virial contribution should be computed |
| [out] | constraintsVirial | The constraint virial is returned in this |
| bool gmx::constrain_lincs | ( | bool | computeRmsd, |
| const t_inputrec & | ir, | ||
| int64_t | step, | ||
| Lincs * | lincsd, | ||
| ArrayRef< const real > | invmass, | ||
| gmx_domdec_t * | dd, | ||
| const gmx_multisim_t * | ms, | ||
| ArrayRefWithPadding< const RVec > | x, | ||
| ArrayRefWithPadding< RVec > | xprime, | ||
| ArrayRef< RVec > | min_proj, | ||
| const matrix | box, | ||
| t_pbc * | pbc, | ||
| bool | hasMassPerturbed, | ||
| real | lambda, | ||
| real * | dvdlambda, | ||
| real | invdt, | ||
| ArrayRef< RVec > | v, | ||
| bool | bCalcVir, | ||
| tensor | vir_r_m_dr, | ||
| ConstraintVariable | econq, | ||
| t_nrnb * | nrnb, | ||
| int | maxwarn, | ||
| int * | warncount, | ||
| gmx_wallcycle * | wcycle | ||
| ) |
Applies LINCS constraints.
| void gmx::constrain_velocities | ( | gmx::Constraints * | constr, |
| bool | computeRmsd, | ||
| int64_t | step, | ||
| t_state * | state, | ||
| real * | dhdlambda, | ||
| bool | computeVirial, | ||
| tensor | constraintsVirial | ||
| ) |
Constrain the velocities only.
The dhdlambda contribution has to be added to the bonded interactions
| [in,out] | constr | The constraints object |
| [in] | computeRmsd | Tells whether the constraint RMS deviation should be computed |
| [in] | step | The integration step index |
| [in,out] | state | The state, x is read and halo data updated, v is constrained |
| [out] | dhdlambda | The dHdlambda contraint contribution is returned in this |
| [in] | computeVirial | Whether the constraint virial contribution should be computed |
| [out] | constraintsVirial | The constraint virial is returned in this |
|
static |
When possible, computes the maximum radius of constrained atom in an update group.
Supports groups with 2 or 3 atoms where all partner atoms are connected to each other by angle potentials. The temperature is used to compute a radius that is not exceeded with a chance of 10^-9. Note that this computation assumes there are no other strong forces working on these angular degrees of freedom. The return value is -1 when all partners are not connected to each other by one angle potential, when a potential is perturbed or when an angle could reach more than 180 degrees.
|
static |
Dispatch the vsite construction tasks for all threads.
| [in] | threadingInfo | Used to divide work over threads when != nullptr |
| [in,out] | x | Coordinates to construct vsites for |
| [in,out] | v | When not empty, velocities are generated for virtual sites |
| [in] | ip | Interaction parameters for all interaction, only vsite parameters are used |
| [in] | ilist | The interaction lists, only vsites are usesd |
| [in] | domainInfo | Information about PBC and DD |
| [in] | box | Used for PBC when PBC is set in domainInfo |
|
static |
Executes the vsite construction task for a single thread.
| calculatePosition | Whether we are calculating positions |
| calculateVelocity | Whether we are calculating velocities |
| [in,out] | x | Coordinates to construct vsites for |
| [in,out] | v | Velocities are generated for virtual sites if calculateVelocity is true |
| [in] | ip | Interaction parameters for all interaction, only vsite parameters are used |
| [in] | ilist | The interaction lists, only vsites are usesd |
| [in] | pbc_null | PBC struct, used for PBC distance calculations when !=nullptr |
| void gmx::constructVirtualSites | ( | ArrayRef< RVec > | x, |
| ArrayRef< const t_iparams > | ip, | ||
| const gmx::EnumerationArray< InteractionFunction, InteractionList > * | ilist | ||
| ) |
Create positions of vsite atoms based for the local system.
| [in,out] | x | The coordinates |
| [in] | ip | Interaction parameters |
| [in] | ilist | The interaction list |
| void gmx::constructVirtualSitesGlobal | ( | const gmx_mtop_t & | mtop, |
| ArrayRef< RVec > | x | ||
| ) |
Create positions of vsite atoms for the whole system assuming all molecules are wholex.
| [in] | mtop | The global topology |
| [in,out] | x | The global coordinates |
|
inlinestatic |
Convert signed char (as used by SimulationSignal) to CheckpointSignal enum.
Expected values are sig == 0 – no signal sig >= 1 – signal received
|
inlinestatic |
Convert signed char (as used by SimulationSignal) to ResetSignal enum.
Expected values are sig == 0 – no signal sig >= 1 – signal received
|
inlinestatic |
Convert signed char (as used by SimulationSignal) to StopSignal enum.
sig == 0 – no signal sig >= 1 – stop at next NS sig <= -1 – stop asap | auto gmx::coordinateExceptionHandling | ( | MPI_Comm | communicator, |
| Callable | callable | ||
| ) | -> typename std::invoke_result_t<Callable> |
Call the callable and then make sure all MPI ranks of communicator have consistent exception-throwing behaviour.
Any rank that threw an exception in callable will re-throw it. If so, any other rank will throw ParallelConsistencyError. Otherwise, does not throw.
Note that the callable must not require any arguments to be passed, so judicious use of a function object, lambda or std::function may be required.
| [in] | communicator | The MPI communicator over which exception-throwing behaviour should be coordinated |
| [in] | callable | The "callable," which can be a function, function object, lambda, or std::function object. It may return a value, but is not required to do so. |
| void gmx::copy_gpu_fepparams | ( | NbnxmGpu gmx_unused * | nb, |
| bool gmx_unused | bFepGpuNonBonded, | ||
| float gmx_unused | alphaCoul, | ||
| float gmx_unused | alphaVdw, | ||
| int gmx_unused | lambdaPower, | ||
| float gmx_unused | sigma6WithInvalidSigma, | ||
| float gmx_unused | sigma6Minimum, | ||
| float gmx_unused | lambdaCoul, | ||
| float gmx_unused | lambdaVdw, | ||
| int gmx_unused | nLambda, | ||
| const EnumerationArray< FreeEnergyPerturbationCouplingType, std::vector< double >> gmx_unused & | all_lambda | ||
| ) |
Copy FEP parameters to GPU.
|
static |
Copies coordinates with RVec layout to SIMD layout with X/Y/Z packs.
| packSize | The stride of the packs in xnb |
| [in] | numAtoms | The number of atoms to copy coordinates for |
| [in] | x | The coordinates to copy |
| [in,out] | xnb | The NBNxM coordainate buffer |
| [in] | a0 | The index of the first atom to copy coordinates for |
|
inlinestatic |
Composes single value with the magnitude of x and the sign of y.
| x | Value to set sign for |
| y | Value used to set sign |
|
inlinestatic |
Composes double value with the magnitude of x and the sign of y.
| x | Value to set sign for |
| y | Value used to set sign |
|
inlinestatic |
Float cos.
| x | The argument to evaluate cos for |
|
inlinestatic |
Double cos.
| x | The argument to evaluate cos for |
|
inlinestatic |
Double cos, but with single accuracy.
| x | The argument to evaluate cos for |
| int gmx::count_triangle_constraints | ( | const InteractionLists & | ilist, |
| const ListOfLists< int > & | at2con | ||
| ) |
Counts the number of constraint triangles, i.e. triplets of atoms connected by three constraints.
| [in] | ilist | The interaction list to count constraints triangles for |
| [in] | at2con | The atom to constraints map |
| int gmx::countInterUpdategroupVsites | ( | const gmx_mtop_t & | mtop, |
| ArrayRef< const RangePartitioning > | updateGroupingsPerMoleculeType | ||
| ) |
Return the number of virtual sites that cross update groups.
| [in] | mtop | The global topology |
| [in] | updateGroupingsPerMoleculeType | Update grouping per molecule type, pass empty when not using update groups |
|
static |
Count pruning kernel time if either kernel has been triggered.
We do the accounting for either of the two pruning kernel flavors:
Note that the resetting of GpuTimers::didPrune and GpuTimers::didRollingPrune should happen after calling this function.
| [in] | timers | structs with GPU timer objects |
| [in,out] | timings | GPU task timing data |
| [in] | iloc | interaction locality |
|
static |
Count the total number of samples / sample weight over all grid points.
| [in] | pointState | The state of the points in a bias. |
|
static |
Count trailing data rows containing only zeros.
| [in] | data | 2D data array. |
| [in] | numRows | Number of rows in array. |
| [in] | numColumns | Number of cols in array. |
| std::string gmx::cpuFftDescription | ( | ) |
Construct a string that describes the library that provides CPU FFT support to this build.
Returns information for describing the CPU FFT support.
| bool gmx::cpuIsAmdZen1 | ( | const CpuInfo & | cpuInfo | ) |
Return true if the CPU is a first generation AMD Zen (produced by AMD or Hygon)
| cpuInfo | Object with cpu information |
| bool gmx::cpuIsNeoverseV2 | ( | const CpuInfo & | cpuInfo | ) |
Return true if the CPU has Neoverse V2 cores (including Grace and Graviton 4)
| cpuInfo | Object with cpu information |
| bool gmx::cpuIsX86Nehalem | ( | const CpuInfo & | cpuInfo | ) |
Return true if the CPU is an Intel x86 Nehalem.
| cpuInfo | Object with cpu information |
| hid_t gmx::createGroup | ( | const hid_t | container, |
| const char * | name | ||
| ) |
Create an H5MD group, and intermediate groups if they do not exist.
| [in] | container | The ID of the container where the group is located, or should be created. |
| [in] | name | The name of the group. |
| FileIOError | If the group cannot be created, such as if it already exists. |
| SimulationWorkload gmx::createSimulationWorkload | ( | const gmx::MDLogger & | mdlog, |
| const t_inputrec & | inputrec, | ||
| bool | haveDynamicBox, | ||
| bool | useReplicaExchange, | ||
| bool | disableNonbondedCalculation, | ||
| const DevelopmentFeatureFlags & | devFlags, | ||
| bool | haveFillerParticlesInLocalState, | ||
| bool | havePpDomainDecomposition, | ||
| bool | haveSeparatePmeRank, | ||
| bool | useGpuForNonbonded, | ||
| bool | useGpuForNonbondedFE, | ||
| PmeRunMode | pmeRunMode, | ||
| bool | useGpuForBonded, | ||
| bool | useGpuForUpdate, | ||
| bool | useGpuDirectHalo, | ||
| bool | canUseDirectGpuComm, | ||
| bool | useGpuPmeDecomposition | ||
| ) |
Build datastructure that contains decisions whether to run different workload task on GPUs.
| [in] | mdlog | Logger object. |
| [in] | inputrec | The input record |
| [in] | haveDynamicBox | Whether the simulation box is dynamic (ie. changes each step) |
| [in] | useReplicaExchange | Whether we are using replica exchange |
| [in] | disableNonbondedCalculation | Disable calculation of nonbonded forces |
| [in] | devFlags | The development feature flags |
| [in] | haveFillerParticlesInLocalState | Whether filler particles are part of the local state. |
| [in] | havePpDomainDecomposition | Whether PP domain decomposition is used in this run. |
| [in] | haveSeparatePmeRank | Whether separate PME rank(s) are used in this run. |
| [in] | useGpuForNonbonded | Whether we have short-range nonbonded interaction calculations on GPU(s). |
| [in] | useGpuForNonbondedFE | Whether we have nonbonded free-energy interaction calculations on GPU(s). |
| [in] | pmeRunMode | Run mode indicating what resource is PME executed on. |
| [in] | useGpuForBonded | Whether bonded interactions are calculated on GPU(s). |
| [in] | useGpuForUpdate | Whether coordinate update and constraint solving is performed on GPU(s). |
| [in] | useGpuDirectHalo | Whether halo exchange is performed directly between GPUs |
| [in] | canUseDirectGpuComm | Whether direct GPU communication can be used in this run. |
| [in] | useGpuPmeDecomposition | GPU based PME decomposition used. |
| std::unique_ptr< TrajectoryFrameWriter > gmx::createTrajectoryFrameWriter | ( | const gmx_mtop_t * | top, |
| const Selection & | sel, | ||
| const std::string & | filename, | ||
| AtomsDataPtr | atoms, | ||
| OutputRequirements | requirements | ||
| ) |
Factory function for TrajectoryFrameWriter.
Used to initialize a new instance of TrajectoryFrameWriter with the user supplied information for writing trajectory data to disk. Information needed is the file type, file name corresponding to the type, if available topology information and selection information.
If supplied, the modules contained within adapters are registered on the TrajectoryFrameWriter if possible.
The factory function is responsible for the initial santity checks concerning file types and availability of topology information, with the registration of modules being the second part.
| [in] | top | Pointer to full topology or null. |
| [in] | sel | Reference to global selection used to construct the object. |
| [in] | filename | Name of new output file, used to deduce file type. |
| [in] | atoms | Smart Pointer to atoms data or null. |
| [in] | requirements | Container for settings obtained to specify which OutputAdapters should be registered. |
| InconsistentInputError | When user input and requirements don't match. |
| void gmx::cshake | ( | const int | iatom[], |
| int | ncon, | ||
| int * | nnit, | ||
| int | maxnit, | ||
| ArrayRef< const real > | constraint_distance_squared, | ||
| ArrayRef< RVec > | positions, | ||
| const t_pbc * | pbc, | ||
| ArrayRef< const RVec > | initial_displacements, | ||
| ArrayRef< const real > | half_of_reduced_mass, | ||
| real | omega, | ||
| ArrayRef< const real > | invmass, | ||
| ArrayRef< const real > | distance_squared_tolerance, | ||
| ArrayRef< real > | scaled_lagrange_multiplier, | ||
| int * | nerror | ||
| ) |
Inner kernel for SHAKE constraints.
Regular iterative shake.
Original implementation from R.C. van Schaik and W.F. van Gunsteren (ETH Zuerich, June 1992), adapted for GROMACS by David van der Spoel November 1992.
The algorithm here is based section five of Ryckaert, Ciccotti and Berendsen, J Comp Phys, 23, 327, 1977.
| [in] | iatom | Mini-topology of triplets of constraint type (unused in this function) and indices of two atoms involved |
| [in] | ncon | Number of constraints |
| [out] | nnit | Number of iterations performed |
| [in] | maxnit | Maximum number of iterations permitted |
| [in] | constraint_distance_squared | The objective value for each constraint |
| [in,out] | positions | The initial (and final) values of the positions of all atoms |
| [in] | pbc | PBC information |
| [in] | initial_displacements | The initial displacements of each constraint |
| [in] | half_of_reduced_mass | Half of the reduced mass for each constraint |
| [in] | omega | SHAKE over-relaxation factor (set non-1.0 by using shake-sor=yes in the .mdp, but there is no documentation anywhere) |
| [in] | invmass | Inverse mass of each atom |
| [in] | distance_squared_tolerance | Multiplicative tolerance on the difference in the square of the constrained distance (see code) |
| [out] | scaled_lagrange_multiplier | Scaled Lagrange multiplier for each constraint (-2 * eta from p. 336 of the paper, divided by the constraint distance) |
| [out] | nerror | Zero upon success, returns one more than the index of the problematic constraint if the input was malformed |
| gmx::EnumerationArray< FreeEnergyPerturbationCouplingType, real > gmx::currentLambdas | ( | int64_t | step, |
| const t_lambda & | fepvals, | ||
| int | currentLambdaState | ||
| ) |
Evaluate the current lambdas.
| [in] | step | the current simulation step |
| [in] | fepvals | describing the lambda setup |
| [in] | currentLambdaState | the lambda state to use to set the lambdas, -1 if not set |
|
inlinestatic |
Just return a boolean (mimicks SIMD real-to-int bool conversions)
| a | boolean |
|
inlinestatic |
Convert double to float (mimicks SIMD conversion)
| a | double |
|
inlinestatic |
Convert float to double (mimicks SIMD conversion)
| a | float |
|
inlinestatic |
Return integer.
This function mimicks the SIMD integer-to-real conversion routines. By simply returning an integer, we let the compiler sort out whether the conversion should be to float or double rather than using proxy objects.
| a | integer |
|
inlinestatic |
Just return a boolean (mimicks SIMD int-to-real bool conversions)
| a | boolean |
|
inlinestatic |
Round single precision floating point to integer.
| a | float |
|
inlinestatic |
Round single precision doubleing point to integer.
| a | double |
|
inlinestatic |
Truncate single precision floating point to integer.
| a | float |
|
inlinestatic |
Truncate single precision doubleing point to integer.
| a | double |
| void gmx::dd_partition_system | ( | FILE * | fplog, |
| const gmx::MDLogger & | mdlog, | ||
| int64_t | step, | ||
| gmx_domdec_t * | dd, | ||
| bool | bMainState, | ||
| t_state * | state_global, | ||
| const gmx_mtop_t & | top_global, | ||
| const t_inputrec & | inputrec, | ||
| const MDModulesNotifiers & | mdModulesNotifiers, | ||
| gmx::ImdSession * | imdSession, | ||
| pull_t * | pull_work, | ||
| t_state * | state_local, | ||
| gmx::ForceBuffers * | f, | ||
| gmx::MDAtoms * | mdAtoms, | ||
| gmx_localtop_t * | top_local, | ||
| t_forcerec * | fr, | ||
| gmx::VirtualSitesHandler * | vsite, | ||
| gmx::Constraints * | constr, | ||
| t_nrnb * | nrnb, | ||
| gmx_wallcycle * | wcycle, | ||
| bool | bVerbose | ||
| ) |
TODO Remove fplog when group scheme and charge groups are gone.
Partition the system over the nodes.
step is only used for printing error messages. If bMainState==TRUE then state_global from the main node is used, else state_local is redistributed between the nodes. When f!=NULL, *f will be reallocated to the size of state_local.
| [in] | fplog | Pointer to the log file |
| [in] | mdlog | MD file logger |
| [in] | step | Current step |
| [in,out] | dd | The domain decomposition struct, can not be nullptr |
| [in] | bMainState | Is it a main state |
| [in] | state_global | Global state |
| [in] | top_global | Global topology |
| [in] | inputrec | Input record |
| [in] | mdModulesNotifiers | MDModules notifications handler |
| [in] | imdSession | IMD handle |
| [in] | pull_work | Pulling data |
| [in] | state_local | Local state |
| [in] | f | Force buffer |
| [in] | mdAtoms | MD atoms |
| [in] | top_local | Local topology |
| [in] | fr | Force record |
| [in] | vsite | Virtual sites handler |
| [in] | constr | Constraints |
| [in] | nrnb | Cycle counters |
| [in] | wcycle | Timers |
| [in] | bVerbose | Be verbose |
| bool gmx::decideWhetherDirectGpuCommunicationCanBeUsed | ( | gmx::GpuAwareMpiStatus | mpiStatus, |
| bool | haveMts, | ||
| bool | useReplicaExchange, | ||
| bool | haveSwapCoords, | ||
| bool | gpusWereDetected, | ||
| const gmx::MDLogger & | mdlog | ||
| ) |
Decide whether direct GPU communication can be used.
Takes into account the build type which determines feature support as well as GPU development feature flags, determines whether this run can use direct GPU communication. The final decision whether the run will use direct communication for either of the features which rely on it is made during task assignment / simulationWorkload initialization.
| [in] | mpiStatus | Information about GPU-aware availability |
| [in] | haveMts | Whether the simulation uses multiple time stepping |
| [in] | useReplicaExchange | Whether replica exchange is used |
| [in] | haveSwapCoords | Whether the swap-coords functionality is active |
| [in] | gpusWereDetected | Whether we have any GPUs |
| [in] | mdlog | MD logger. |
| bool gmx::decideWhetherToUseGpuForHalo | ( | bool | havePPDomainDecomposition, |
| bool | useGpuForNonbonded, | ||
| bool | canUseDirectGpuComm, | ||
| bool | useModularSimulator, | ||
| bool | doRerun, | ||
| bool | haveEnergyMinimization, | ||
| const gmx::MDLogger & | mdlog | ||
| ) |
Decide whether to use GPU for halo exchange.
| [in] | havePPDomainDecomposition | Whether PP domain decomposition is in use. |
| [in] | useGpuForNonbonded | Whether GPUs will be used for nonbonded interactions. |
| [in] | canUseDirectGpuComm | Whether direct GPU communication can be used. |
| [in] | useModularSimulator | Whether modularsimulator is in use. |
| [in] | doRerun | Whether this is a rerun. |
| [in] | haveEnergyMinimization | Whether energy minimization is in use. |
| [in] | mdlog | MD logger. |
| bool gmx::decideWhetherToUseGpuForUpdate | ( | bool | isDomainDecomposition, |
| bool | useUpdateGroups, | ||
| PmeRunMode | pmeRunMode, | ||
| bool | havePmeOnlyRank, | ||
| bool | useGpuForNonbonded, | ||
| TaskTarget | updateTarget, | ||
| bool | gpusWereDetected, | ||
| const t_inputrec & | inputrec, | ||
| const gmx_mtop_t & | mtop, | ||
| bool | useEssentialDynamics, | ||
| bool | doOrientationRestraints, | ||
| bool | haveFrozenAtoms, | ||
| bool | useModularSimulator, | ||
| bool | doRerun, | ||
| const gmx::MDLogger & | mdlog | ||
| ) |
Decide whether to use GPU for update.
| [in] | isDomainDecomposition | Whether there more than one domain. |
| [in] | useUpdateGroups | If the constraints can be split across domains. |
| [in] | pmeRunMode | PME running mode: CPU, GPU or mixed. |
| [in] | havePmeOnlyRank | If there is a PME-only rank in the simulation. |
| [in] | useGpuForNonbonded | Whether GPUs will be used for nonbonded interactions. |
| [in] | updateTarget | User choice for running simulation on GPU. |
| [in] | gpusWereDetected | Whether compatible GPUs were detected on any node. |
| [in] | inputrec | The user input. |
| [in] | mtop | The global topology. |
| [in] | useEssentialDynamics | If essential dynamics is active. |
| [in] | doOrientationRestraints | If orientation restraints are enabled. |
| [in] | haveFrozenAtoms | If this simulation has frozen atoms (see Issue #3920). |
| [in] | useModularSimulator | Whether the modular simulator is used |
| [in] | doRerun | It this is a rerun. |
| [in] | mdlog | MD logger. |
| std::bad_alloc | If out of memory InconsistentInputError If the user requirements are inconsistent. |
| bool gmx::decideWhetherToUseGpusForBonded | ( | bool | useGpuForNonbonded, |
| bool | useGpuForPme, | ||
| TaskTarget | bondedTarget, | ||
| const t_inputrec & | inputrec, | ||
| const gmx_mtop_t & | mtop, | ||
| int | numPmeRanksPerSimulation, | ||
| bool | gpusWereDetected | ||
| ) |
Decide whether the simulation will try to run bonded tasks on GPUs.
| [in] | useGpuForNonbonded | Whether GPUs will be used for nonbonded interactions. |
| [in] | useGpuForPme | Whether GPUs will be used for PME interactions. |
| [in] | bondedTarget | The user's choice for mdrun -bonded for where to assign tasks. |
| [in] | inputrec | The user input. |
| [in] | mtop | The global topology. |
| [in] | numPmeRanksPerSimulation | The number of PME ranks in each simulation, can be -1 for auto. |
| [in] | gpusWereDetected | Whether compatible GPUs were detected on any node. |
| std::bad_alloc | If out of memory InconsistentInputError If the user requirements are inconsistent. |
| bool gmx::decideWhetherToUseGpusForNonbonded | ( | TaskTarget | nonbondedTarget, |
| const std::vector< int > & | userGpuTaskAssignment, | ||
| EmulateGpuNonbonded | emulateGpuNonbonded, | ||
| bool | canUseNonbondedOnGpu, | ||
| bool | binaryReproducibilityRequested, | ||
| bool | gpusWereDetected | ||
| ) |
Decide whether the simulation will try to run nonbonded tasks on GPUs.
The final decision cannot be made until after the duty of the rank is known. But we need to know if nonbonded will run on GPUs for setting up DD (particularly rlist) and determining duty. If the user requires GPUs for the tasks of that duty, then it will be an error when none are found.
With thread-MPI, calls have been made to decideWhetherToUseGpusForNonbondedWithThreadMpi() and decideWhetherToUseGpusForPmeWithThreadMpi() to help determine the number of ranks and run some checks, but the final decision is made in this routine, along with many more consistency checks.
| [in] | nonbondedTarget | The user's choice for mdrun -nb for where to assign short-ranged nonbonded interaction tasks. |
| [in] | userGpuTaskAssignment | The user-specified assignment of GPU tasks to device IDs. |
| [in] | emulateGpuNonbonded | Whether we will emulate GPU calculation of nonbonded interactions. |
| [in] | canUseNonbondedOnGpu | Whether GROMACS was build with GPU support and simulation parameters are compatible. |
| [in] | binaryReproducibilityRequested | Whether binary reproducibility was requested |
| [in] | gpusWereDetected | Whether compatible GPUs were detected on any node. |
| std::bad_alloc | If out of memory InconsistentInputError If the user requirements are inconsistent. |
| bool gmx::decideWhetherToUseGpusForNonbondedFE | ( | bool | useGpuForNonbonded, |
| TaskTarget | nonBondedFeTarget | ||
| ) |
Decide whether the simulation will try to run nonbonde FE tasks on GPUs.
| [in] | useGpuForNonbonded | Whether GPUs will be used for nonbonded interactions. |
| [in] | nonBondedFeTarget | The user's choice for mdrun -nbfe for where to assign tasks. |
| std::bad_alloc | If out of memory InconsistentInputError If the user requirements are inconsistent. |
| bool gmx::decideWhetherToUseGpusForNonbondedWithThreadMpi | ( | TaskTarget | nonbondedTarget, |
| bool | haveAvailableDevices, | ||
| const std::vector< int > & | userGpuTaskAssignment, | ||
| EmulateGpuNonbonded | emulateGpuNonbonded, | ||
| bool | canUseNonbondedOnGpu, | ||
| bool | binaryReproducibilityRequested, | ||
| int | numRanksPerSimulation | ||
| ) |
Decide whether this thread-MPI simulation will run nonbonded tasks on GPUs.
The number of GPU tasks and devices influences both the choice of the number of ranks, and checks upon any such choice made by the user. So we need to consider this before any automated choice of the number of thread-MPI ranks.
| [in] | nonbondedTarget | The user's choice for mdrun -nb for where to assign short-ranged nonbonded interaction tasks. |
| [in] | haveAvailableDevices | Whether there are available devices. |
| [in] | userGpuTaskAssignment | The user-specified assignment of GPU tasks to device IDs. |
| [in] | emulateGpuNonbonded | Whether we will emulate GPU calculation of nonbonded interactions. |
| [in] | canUseNonbondedOnGpu | Whether GROMACS was built with GPU support and simulation parameters are compatible. |
| [in] | binaryReproducibilityRequested | Whether binary reproducibility was requested |
| [in] | numRanksPerSimulation | The number of ranks in each simulation. |
| std::bad_alloc | If out of memory InconsistentInputError If the user requirements are inconsistent. |
| bool gmx::decideWhetherToUseGpusForPme | ( | bool | useGpuForNonbonded, |
| TaskTarget | pmeTarget, | ||
| TaskTarget | pmeFftTarget, | ||
| const std::vector< int > & | userGpuTaskAssignment, | ||
| const t_inputrec & | inputrec, | ||
| int | numRanksPerSimulation, | ||
| int | numPmeRanksPerSimulation, | ||
| bool | gpusWereDetected | ||
| ) |
Decide whether the simulation will try to run tasks of different types on GPUs.
The final decision cannot be made until after the duty of the rank is known. But we need to know if nonbonded will run on GPUs for setting up DD (particularly rlist) and determining duty. If the user requires GPUs for the tasks of that duty, then it will be an error when none are found.
With thread-MPI, calls have been made to decideWhetherToUseGpusForNonbondedWithThreadMpi() and decideWhetherToUseGpusForPmeWithThreadMpi() to help determine the number of ranks and run some checks, but the final decision is made in this routine, along with many more consistency checks.
| [in] | useGpuForNonbonded | Whether GPUs will be used for nonbonded interactions. |
| [in] | pmeTarget | The user's choice for mdrun -pme for where to assign long-ranged PME nonbonded interaction tasks. |
| [in] | pmeFftTarget | The user's choice for mdrun -pmefft for where to do FFT for PME. |
| [in] | userGpuTaskAssignment | The user-specified assignment of GPU tasks to device IDs. |
| [in] | inputrec | The user input |
| [in] | numRanksPerSimulation | The number of ranks in each simulation. |
| [in] | numPmeRanksPerSimulation | The number of PME ranks in each simulation. |
| [in] | gpusWereDetected | Whether compatible GPUs were detected on any node. |
| std::bad_alloc | If out of memory InconsistentInputError If the user requirements are inconsistent. |
| bool gmx::decideWhetherToUseGpusForPmeWithThreadMpi | ( | bool | useGpuForNonbonded, |
| TaskTarget | pmeTarget, | ||
| TaskTarget | pmeFftTarget, | ||
| int | numDevicesToUse, | ||
| const std::vector< int > & | userGpuTaskAssignment, | ||
| const t_inputrec & | inputrec, | ||
| int | numRanksPerSimulation, | ||
| int | numPmeRanksPerSimulation | ||
| ) |
Decide whether this thread-MPI simulation will run PME tasks on GPUs.
The number of GPU tasks and devices influences both the choice of the number of ranks, and checks upon any such choice made by the user. So we need to consider this before any automated choice of the number of thread-MPI ranks.
| [in] | useGpuForNonbonded | Whether GPUs will be used for nonbonded interactions. |
| [in] | pmeTarget | The user's choice for mdrun -pme for where to assign long-ranged PME nonbonded interaction tasks. |
| [in] | pmeFftTarget | The user's choice for mdrun -pmefft for where to run FFT. |
| [in] | numDevicesToUse | The number of compatible GPUs that the user permitted us to use. |
| [in] | userGpuTaskAssignment | The user-specified assignment of GPU tasks to device IDs. |
| [in] | inputrec | The user input |
| [in] | numRanksPerSimulation | The number of ranks in each simulation. |
| [in] | numPmeRanksPerSimulation | The number of PME ranks in each simulation. |
| std::bad_alloc | If out of memory InconsistentInputError If the user requirements are inconsistent. |
|
static |
Create a deep copy of a t_trxframe input into copy.
When running the analysis tools and changing values with the outputadapters, a deep copy of the input coordinate frame has to be created first to ensure that the data is not changed if it is needed for other tools following with analysis later. Therefore, the data is passed to copy by performing a deep copy first.
The method allocates new storage for coordinates of the x, v, and f arrays in the new coordinate frame. This means that those arrays need to be free'd after the frame has been processed and been written to disk.
| [in] | input | Reference input coordinate frame. |
| [in,out] | copy | Pointer to new output frame that will receive the deep copy. |
| [in] | xvec | Pointer to local coordinate storage vector. |
| [in] | vvec | Pointer to local velocity storage vector. |
| [in] | fvec | Pointer to local force storage vector. |
| [in] | indexvec | Pointer to local index storage vector. |
| MrcDensityMapHeader gmx::deserializeMrcDensityMapHeader | ( | ISerializer * | serializer | ) |
Deserializes an MrcDensityMapHeader from a given serializer.
| [in] | serializer | the serializer |
|
static |
Detect GPUs when that makes sense to attempt.
| [in] | physicalNodeComm | The communicator across this physical node |
|
static |
Determine which device to use depending on GMX_NN_DEVICE environment variable.
Should be "gpu" or "cpu". "cuda" option is deprecated. Defaults to GPU if no environment variable is set. Throws an error if CUDA/HIP is requested but no compatible device is available. Also throws an error if the environment variable is set to an invalid value.
| PmeRunMode gmx::determinePmeRunMode | ( | bool | useGpuForPme, |
| const TaskTarget & | pmeFftTarget, | ||
| const t_inputrec & | inputrec | ||
| ) |
Determine PME run mode.
Given the PME task assignment in useGpuForPme and the user-provided FFT task target in pmeFftTarget, returns a PME run mode for the current run. It also checks the compatibility of the two.
useGpuForPme and pmeFftTarget.| [in] | useGpuForPme | PME task assignment, true if PME task is mapped to the GPU. |
| [in] | pmeFftTarget | The user's choice for -pmefft for where to assign the FFT work of the PME task. |
| [in] | inputrec | The user input record |
| constexpr std::array<T, jClusterSize / iClusterSize> gmx::diagonalMaskJLargerI | ( | ) |
Returns a diagonal interaction mask with atoms j>i masked out.
| T | Integer type, should have at least iClusterSize*jClusterSize bits |
| iClusterSize | The i-cluster size |
| jClusterSize | The j-cluster size |
Condition: jClusterSize >= iClusterSize
| constexpr std::array<T, iClusterSize / jClusterSize> gmx::diagonalMaskJSmallerI | ( | ) |
Returns a diagonal interaction mask with atoms j<i masked out.
| T | Integer type, should have at least iClusterSize*jClusterSize bits |
| iClusterSize | The i-cluster size |
| jClusterSize | The j-cluster size |
Condition: jClusterSize <= iClusterSize
| BasicMatrix3x3<ElementType> gmx::diagonalMatrix | ( | const ElementType | value | ) |
Create a diagonal matrix of ElementType.
| ElementType | type of matrix elements |
| value | The value that fills the leading diagonal |
value where row equals column index and null where row does not equal column index | void gmx::distributeTransformationPullCoordForce | ( | pull_coord_work_t * | pcrd, |
| gmx::ArrayRef< pull_coord_work_t > | variableCoords | ||
| ) |
Distributes the force on a transformation pull coordinates to the involved coordinates of lower rank.
Note: There is no recursion applied here, which means that this function needs to be called in a reverse loop over the pull coordinates to ensure that forces on recursive transformation coordinates are distributed correctly.
| [in,out] | pcrd | The transformation pull coordinate to act on |
| [in,out] | variableCoords | List of variable coords up to the coord index of pcrd |
| constexpr T gmx::divideRoundUp | ( | T | numerator, |
| T | denominator | ||
| ) |
Return numerator divided by denominator rounded up to the next integer.
| [in] | numerator | Numerator, a non-negative integer. |
| [in] | denominator | Denominator, a positive integer. |
numerator and denominator should fit into T | void gmx::doDeviceTransfers | ( | const DeviceContext & | deviceContext, |
| ArrayRef< const char > | input, | ||
| ArrayRef< char > | output | ||
| ) |
Helper function for GPU test code to be platform agnostic.
Transfers input to device 0, if present, and transfers it back into output. Both sizes must match. If no devices are present, do a simple host-side buffer copy instead.
| InternalError | Upon any GPU API error condition. |
| constexpr std::enable_if_t<BasicMdspan::is_always_contiguous(), typename BasicMdspan::pointer> gmx::end | ( | const BasicMdspan & | basicMdspan | ) |
Free end function addressing memory of a contiguously laid out basic_mdspan.
|
inline |
Helper function to ensure no pending error silently disrupts error handling.
Asserts in a debug build if an unhandled error is present. Issues a warning at run time otherwise.
| [in] | errorMessage | Undecorated error message. |
|
static |
Check if the state (loaded from checkpoint) and the run are consistent.
When the state and the run setup are inconsistent, an exception is thrown.
| [in] | params | The parameters of the bias. |
| [in] | state | The state of the bias. |
|
static |
Get the human-friendly name for atom localities.
| [in] | enumValue | The enum value to get the name for. |
|
static |
Get the human-friendly name for interaction localities.
| [in] | enumValue | The enum value to get the name for. |
|
inlinestatic |
Float erf(x).
| x | Argument. |
|
inlinestatic |
Double erf(x).
| x | Argument. |
|
inlinestatic |
Float erfc(x).
| x | Argument. |
|
inlinestatic |
Double erfc(x).
| x | Argument. |
|
inlinestatic |
Double erfc(x), but with single accuracy.
| x | Argument. |
| double gmx::erfinv | ( | double | x | ) |
Inverse error function, double precision.
| x | Argument, should be in the range -1.0 < x < 1.0 |
| float gmx::erfinv | ( | float | x | ) |
Inverse error function, single precision.
| x | Argument, should be in the range -1.0 < x < 1.0 |
|
inlinestatic |
Double erf(x), but with single accuracy.
| x | Argument. |
| std::pair<size_t, size_t> gmx::estimateBufferSize | ( | Iterator | begin, |
| Iterator | end, | ||
| Callback | cStringFromIterator | ||
| ) |
Iterate over a list of objects and calculate the maximum string length via a callback function.
| Iterator | The type of the iterator of the source strings. |
| Callback | The type of the callback function to convert iterator to C-string. |
| [in] | begin | Iterator to the beginning of the source vector of strings. |
| [in] | end | Iterator to the end of the source vector of strings. |
| [in] | cStringFromIterator | The callback function to convert iterator to C-string. |
| constexpr int32_t gmx::exactDiv | ( | int32_t | a, |
| int32_t | b | ||
| ) |
Exact integer division, 32bit.
| a | dividend. Function asserts that it is a multiple of divisor |
| b | divisor |
| std::string gmx::exaFmmTreeTypeName | ( | ExaFmmTreeType | treeType | ) |
Returns the string name for a given ExaFmm Tree Type.
| treeType | The ExaFmmTreeType enum value. |
|
inlinestatic |
Float exp(x).
| x | Argument. |
|
inlinestatic |
Double exp(x).
| x | Argument. |
|
inlinestatic |
Float 2^x.
| x | Argument. |
|
inlinestatic |
Double 2^x.
| x | Argument. |
|
inlinestatic |
Double 2^x, but with single accuracy.
| x | Argument. |
|
inlinestatic |
Copy single float to three variables.
| scalar | Floating-point input. | |
| [out] | triplets0 | Copy 1. |
| [out] | triplets1 | Copy 2. |
| [out] | triplets2 | Copy 3. |
|
inlinestatic |
Copy single double to three variables.
| scalar | Floating-point input. | |
| [out] | triplets0 | Copy 1. |
| [out] | triplets1 | Copy 2. |
| [out] | triplets2 | Copy 3. |
| ExponentialMovingAverageState gmx::exponentialMovingAverageStateFromKeyValueTree | ( | const KeyValueTreeObject & | object | ) |
Sets the exponential moving average state from a key-value-tree object.
Sets the expoential moving average state from a key-value-tree object.
|
inlinestatic |
Double exp(x), but with single accuracy.
| x | Argument. |
|
inlinestatic |
Add a new entry to the i-list as a copy of the last entry.
If the last i-entry has no j-entries, it will be replaced instead of creating a new entry.
|
inlinestatic |
Fetch two consecutive values from the Ewald correction F*r table.
Depending on what is supported, it fetches parameters either using direct load, texture objects, or texrefs.
|
static |
Initializes data structures that are going to be sent to the OpenCL device.
The device can't use the same data structures as the host for two main reasons:
This function is called before the launch of both nbnxn and prune kernels.
|
static |
Return the list of sub-group sizes supported by the device.
| devId | OpenCL device ID. |
| deviceVendor | Device vendor. |
| GpuTasksOnRanks gmx::findAllGpuTasksOnThisNode | ( | ArrayRef< const GpuTask > | gpuTasksOnThisRank, |
| const PhysicalNodeCommunicator & | physicalNodeComm | ||
| ) |
Returns container of all tasks on all ranks of this node that are eligible for GPU execution.
Perform all necessary communication for preparing for task assignment. Separating this aspect makes it possible to unit test the logic of task assignment.
| std::vector< GpuTask > gmx::findGpuTasksOnThisRank | ( | bool | haveGpusOnThisPhysicalNode, |
| TaskTarget | nonbondedTarget, | ||
| TaskTarget | nonbondedFeTarget, | ||
| TaskTarget | pmeTarget, | ||
| TaskTarget | bondedTarget, | ||
| TaskTarget | updateTarget, | ||
| bool | useGpuForNonbonded, | ||
| bool | useGpuForPme, | ||
| bool | rankHasPpTask, | ||
| bool | rankHasPmeTask | ||
| ) |
Returns container of all tasks on this rank that are eligible for GPU execution.
| [in] | haveGpusOnThisPhysicalNode | Whether there are any GPUs on this physical node. |
| [in] | nonbondedTarget | The user's choice for mdrun -nb for where to assign short-ranged nonbonded interaction tasks. |
| [in] | nonbondedFeTarget | The user's choice for mdrun -nbfe for where to assign nonbonded fe interaction tasks. |
| [in] | pmeTarget | The user's choice for mdrun -pme for where to assign long-ranged PME nonbonded interaction tasks. |
| [in] | bondedTarget | The user's choice for mdrun -bonded for where to assign tasks. |
| [in] | updateTarget | The user's choice for mdrun -update for where to assign tasks. |
| [in] | useGpuForNonbonded | Whether GPUs will be used for nonbonded interactions. |
| [in] | useGpuForPme | Whether GPUs will be used for PME interactions. |
| [in] | rankHasPpTask | Whether this rank has a PP task |
| [in] | rankHasPmeTask | Whether this rank has a PME task |
| std::filesystem::path gmx::findLibraryFile | ( | const std::filesystem::path & | filename, |
| bool | bAddCWD = true, |
||
| bool | bFatal = true |
||
| ) |
Finds full path for a library file.
Searches in the configured library directories for filename. If bAddCWD is true, searches first in the current directory. Fatal error results if the file is not found in any location and bFatal is true.
|
static |
Checks whether interactions have been assigned for one function type.
Loops over a list of interactions in the local topology of one function type and flags each of the interactions as assigned in the global isAssigned list. Exits with an inconsistency error when an interaction is assigned more than once.
|
inlinestatic |
Float Fused-multiply-add. Result is a*b + c.
| a | factor1 |
| b | factor2 |
| c | term |
|
inlinestatic |
double Fused-multiply-add. Result is a*b + c.
| a | factor1 |
| b | factor2 |
| c | term |
| std::string gmx::fmmBackendName | ( | ActiveFmmBackend | backend | ) |
Returns the string name for a given FMM backend.
| backend | The FMM backend enum value. |
| std::string gmx::fmmDirectProviderName | ( | FmmDirectProvider | directProvider | ) |
Returns the string name for a given FMM direct provider.
| directProvider | The FmmDirectProvider enum value. |
|
inlinestatic |
Float Fused-multiply-subtract. Result is a*b - c.
| a | factor1 |
| b | factor2 |
| c | term |
|
inlinestatic |
double Fused-multiply-subtract. Result is a*b - c.
| a | factor1 |
| b | factor2 |
| c | term |
|
inlinestatic |
Float Fused-negated-multiply-add. Result is -a*b + c.
| a | factor1 |
| b | factor2 |
| c | term |
|
inlinestatic |
double Fused-negated-multiply-add. Result is - a*b + c.
| a | factor1 |
| b | factor2 |
| c | term |
|
inlinestatic |
Float Fused-negated-multiply-subtract. Result is -a*b - c.
| a | factor1 |
| b | factor2 |
| c | term |
|
inlinestatic |
double Fused-negated-multiply-subtract. Result is -a*b - c.
| a | factor1 |
| b | factor2 |
| c | term |
|
inlinestatic |
Returns the MTS level at which a force group is to be computed.
| [in] | mtsLevels | List of force groups for each MTS level, can be empty without MTS |
| [in] | mtsForceGroup | The force group to query the MTS level for |
|
static |
Returns a string describing the setup of a single pair-list.
| [in] | listName | Short name of the list, can be "" |
| [in] | nstList | The list update interval in steps |
| [in] | nstListForSpacing | Update interval for setting the number characters for printing nstList |
| [in] | rList | List cut-off radius |
| [in] | interactionCutoff | The interaction cut-off, use for printing the list buffer size |
|
static |
Free the OpenCL program.
The function releases the OpenCL program assuciated with the device that the calling PP rank is running on.
| program | [in] OpenCL program to release. |
|
inlinestatic |
Load 4 floats from base/offsets and store into variables.
| align | Alignment of the memory from which we read, i.e. distance (measured in elements, not bytes) between index points. |
| base | Aligned pointer to the start of the memory. | |
| offset | Integer type with offset to the start of each triplet. | |
| [out] | v0 | First float, base[align*offset[0]]. |
| [out] | v1 | Second float, base[align*offset[0] + 1]. |
| [out] | v2 | Third float, base[align*offset[0] + 2]. |
| [out] | v3 | Fourth float, base[align*offset[0] + 3]. |
|
inlinestatic |
Load 2 floats from base/offsets and store into variables (aligned).
| align | Alignment of the memory from which we read, i.e. distance (measured in elements, not bytes) between index points. |
| base | Aligned pointer to the start of the memory. | |
| offset | Integer type with offset to the start of each triplet. | |
| [out] | v0 | First float, base[align*offset[0]]. |
| [out] | v1 | Second float, base[align*offset[0] + 1]. |
|
inlinestatic |
Load 4 doubles from base/offsets and store into variables.
| align | Alignment of the memory from which we read, i.e. distance (measured in elements, not bytes) between index points. |
| base | Aligned pointer to the start of the memory. | |
| offset | Integer type with offset to the start of each triplet. | |
| [out] | v0 | First double, base[align*offset[0]]. |
| [out] | v1 | Second double, base[align*offset[0] + 1]. |
| [out] | v2 | Third double, base[align*offset[0] + 2]. |
| [out] | v3 | Fourth double, base[align*offset[0] + 3]. |
|
inlinestatic |
Load 2 doubles from base/offsets and store into variables (aligned).
| align | Alignment of the memory from which we read, i.e. distance (measured in elements, not bytes) between index points. |
| base | Aligned pointer to the start of the memory. | |
| offset | Integer type with offset to the start of each triplet. | |
| [out] | v0 | First double, base[align*offset[0]]. |
| [out] | v1 | Second double, base[align*offset[0] + 1]. |
|
inlinestatic |
Load 4 consecutive floats from base/offset into four variables.
| align | Alignment of the memory from which we read. |
| base | Pointer to the start of the memory area | |
| offset | Index to data. | |
| [out] | v0 | 1st float, base[align*offset[0]]. |
| [out] | v1 | 2nd float, base[align*offset[0] + 1]. |
| [out] | v2 | 3rd float, base[align*offset[0] + 2]. |
| [out] | v3 | 4th float, base[align*offset[0] + 3]. |
|
inlinestatic |
Load 2 consecutive floats from base/offset into four variables.
| align | Alignment of the memory from which we read. |
| base | Pointer to the start of the memory area | |
| offset | Index to data. | |
| [out] | v0 | 1st float, base[align*offset[0]]. |
| [out] | v1 | 2nd float, base[align*offset[0] + 1]. |
|
inlinestatic |
Load 4 consecutive doubles from base/offset into four variables.
| align | Alignment of the memory from which we read. |
| base | Pointer to the start of the memory area | |
| offset | Index to data. | |
| [out] | v0 | 1st double, base[align*offset[0]]. |
| [out] | v1 | 2nd double, base[align*offset[0] + 1]. |
| [out] | v2 | 3rd double, base[align*offset[0] + 2]. |
| [out] | v3 | 4th double, base[align*offset[0] + 3]. |
|
inlinestatic |
Load 2 consecutive doubles from base/offset into four variables.
| align | Alignment of the memory from which we read. |
| base | Pointer to the start of the memory area | |
| offset | Index to data. | |
| [out] | v0 | 1st double, base[align*offset[0]]. |
| [out] | v1 | 2nd double, base[align*offset[0] + 1]. |
|
inlinestatic |
Load 2 floats from base/offsets and store into variables (unaligned).
| align | Alignment of the memory from which we read, i.e. distance (measured in elements, not bytes) between index points. |
| base | Aligned pointer to the start of the memory. | |
| offset | Integer type with offset to the start of each triplet. | |
| [out] | v0 | First float, base[align*offset[0]]. |
| [out] | v1 | Second float, base[align*offset[0] + 1]. |
|
inlinestatic |
Load 2 doubles from base/offsets and store into variables (unaligned).
| align | Alignment of the memory from which we read, i.e. distance (measured in elements, not bytes) between index points. |
| base | Aligned pointer to the start of the memory. | |
| offset | Integer type with offset to the start of each triplet. | |
| [out] | v0 | First double, base[align*offset[0]]. |
| [out] | v1 | Second double, base[align*offset[0] + 1]. |
|
inlinestatic |
Load 3 consecutive floats from base/offsets, store into three vars.
| align | Alignment of the memory from which we read, i.e. distance (measured in elements, not bytes) between index points. |
| base | Pointer to the start of the memory area | |
| offset | Offset to the start of data. | |
| [out] | v0 | 1st value, base[align*offset[0]]. |
| [out] | v1 | 2nd value, base[align*offset[0] + 1]. |
| [out] | v2 | 3rd value, base[align*offset[0] + 2]. |
|
inlinestatic |
Load 3 consecutive doubles from base/offsets, store into three vars.
| align | Alignment of the memory from which we read, i.e. distance (measured in elements, not bytes) between index points. |
| base | Pointer to the start of the memory area | |
| offset | Offset to the start of data. | |
| [out] | v0 | 1st double, base[align*offset[0]]. |
| [out] | v1 | 2nd double, base[align*offset[0] + 1]. |
| [out] | v2 | 3rd double, base[align*offset[0] + 2]. |
| real gmx::generateAndFill2DGrid | ( | Grid * | grid, |
| ArrayRef< GridWork > | gridWork, | ||
| HostVector< int > * | cells, | ||
| const rvec | lowerCorner, | ||
| const rvec | upperCorner, | ||
| const UpdateGroupsCog * | updateGroupsCog, | ||
| Range< int > | atomRange, | ||
| int | numGridAtomsWithoutFillers, | ||
| real * | atomDensity, | ||
| real | maxAtomGroupRadius, | ||
| ArrayRef< const RVec > | x, | ||
| int | ddZone, | ||
| const int * | move, | ||
| bool | computeGridDensityRatio | ||
| ) |
Sets the 2D search grid dimensions puts the atoms on the 2D grid.
| [in,out] | grid | The pair search grid for one DD zone |
| [in,out] | gridWork | Working data for each thread |
| [in,out] | cells | The grid cell list |
| [in] | lowerCorner | The minimum Cartesian coordinates of the grid |
| [in] | upperCorner | The maximum Cartesian coordinates of the grid |
| [in] | updateGroupsCog | The center of geometry of update groups, can be nullptr |
| [in] | atomRange | The range of atoms to put on this grid, may include moved atoms |
| [in] | numGridAtomsWithoutFillers | The number of atoms that are not filler particles and have not moved by to another domain by DD |
| [in,out] | atomDensity | The atom density, will be computed when <= 0 |
| [in] | maxAtomGroupRadius | The maximum radius of atom groups |
| [in] | x | The coordinates of the atoms |
| [in] | ddZone | The domain decomposition zone |
| [in] | move | Tells whether atoms have moved to another DD domain |
| [in] | computeGridDensityRatio | When true, return the grid density ratio |
computeGridDensityRatio==true, the ratio of the effective 2D grid density and the uniform grid density | RealType gmx::generateCanonical | ( | Rng & | g | ) |
Generate a floating-point value with specified number of random bits.
| RealType | Floating-point type to generate |
| Bits | Number of random bits to generate |
| Rng | Random number generator class |
| g | Random number generator to use |
This implementation avoids the bug in libc++ and stdlibc++ (which is due to the C++ standard being unclear) where 1.0 can be returned occasionally.
|
static |
Gets the period of a pull coordinate.
| [in] | pullCoordParams | The parameters for the pull coordinate. |
| [in] | pbc | The PBC setup |
| [in] | intervalLength | The length of the AWH interval for this pull coordinate |
| std::optional< ValueType > gmx::getAttribute | ( | const hid_t | container, |
| const char * | attributeName | ||
| ) |
Read an attribute of a given data type.
| ValueType | The type of the attribute to read |
| [in] | container | The HDF5 container (group or dataset) to read the attribute from. |
| [in] | attributeName | The name of the attribute to read. |
| std::optional< std::string > gmx::getAttribute< std::string > | ( | const hid_t | container, |
| const char * | attributeName | ||
| ) |
Read an attribute of a given data type.
| ValueType | The type of the attribute to read |
| [in] | container | The HDF5 container (group or dataset) to read the attribute from. |
| [in] | attributeName | The name of the attribute to read. |
| std::optional< std::vector< ValueType > > gmx::getAttributeVector | ( | const hid_t | container, |
| const char * | attributeName | ||
| ) |
Read a vector-like attribute of a given data type.
| ValueType | The type of the attribute to read |
| [in] | container | The HDF5 container (group or dataset) to read the attribute from. |
| [in] | attributeName | The name of the attribute to read. |
| std::optional< std::vector< std::string > > gmx::getAttributeVector< std::string > | ( | const hid_t | container, |
| const char * | attributeName | ||
| ) |
Read a vector-like attribute of a given data type.
| ValueType | The type of the attribute to read |
| [in] | container | The HDF5 container (group or dataset) to read the attribute from. |
| [in] | attributeName | The name of the attribute to read. |
| TranslateAndScale gmx::getCoordinateTransformationToLattice | ( | const MrcDensityMapHeader & | header | ) |
Extract the transformation into lattice coordinates.
In determining the density origin coordinates, explicit ORIGIN records (also called origin2k) in the user defined floats 13 - 15, corresponding to words 50,51 and 52 in the mrc header, precedence over ColumnRowSectionStart. Only if above values are zero, using the column, row and section start to determine the translation vector.
| [in] | header | from which the coordinate transformation is to be extracted |
| double gmx::getDeviationFromPointAlongGridAxis | ( | const BiasGrid & | grid, |
| int | dimIndex, | ||
| int | pointIndex, | ||
| double | value | ||
| ) |
Get the deviation along one dimension from the given value to a point in the grid.
| [in] | grid | The grid. |
| [in] | dimIndex | Dimensional index in [0, ndim -1]. |
| [in] | pointIndex | BiasGrid point index. |
| [in] | value | Value along the given dimension. |
| double gmx::getDeviationFromPointAlongGridAxis | ( | const BiasGrid & | grid, |
| int | dimIndex, | ||
| int | pointIndex1, | ||
| int | pointIndex2 | ||
| ) |
Get the deviation from one point to another along one dimension in the grid.
| [in] | grid | The grid. |
| [in] | dimIndex | Dimensional index in [0, ndim -1]. |
| [in] | pointIndex1 | Grid point index of the first point. |
| [in] | pointIndex2 | Grid point index of the second point. |
|
inline |
Add the API information on the specific error to the error message.
| [in] | deviceError | The error to assert hipSuccess on. |
| dynamicExtents3D gmx::getDynamicExtents3D | ( | const MrcDensityMapHeader & | header | ) |
Extract the extents of the density data.
| [in] | header | from which the extents are to be extracted |
| size_t gmx::getExclusiveScanWorkingArraySize | ( | GpuPairlist * | plist, |
| const DeviceStream & | deviceStream | ||
| ) |
Calculates working memory required for exclusive sum, used in neighbour list sorting on GPU.
This is only used for CUDA/HIP, where the actual size is calculate based on the list. For SYCL, the default value of 0 is important for the code to work correctly, this is why we have it set here.
|
static |
Compute the number of times the "local forces ready on device" GPU event will be used as a synchronization point.
In GROMACS, we usually follow the "mark once - wait once" approach. But this event is "consumed" (that is, waited upon either on host or on the device) multiple times, since many tasks in different streams depend on the local forces.
| simulationWork | Simulation workload flags. |
| domainWork | Domain workload flags. |
| stepWork | Step workload flags. |
| useOrEmulateGpuNb | Whether GPU non-bonded calculations are used or emulated. |
| alternateGpuWait | Whether alternating wait/reduce scheme is used. |
|
static |
Compute the number of times the "local coordinates ready on device" GPU event will be used as a synchronization point.
When some work is offloaded to GPU, force calculation should wait for the atom coordinates to be ready on the device. The coordinates can come either from H2D copy at the beginning of the step, or from the GPU integration at the end of the previous step.
In GROMACS, we usually follow the "mark once - wait once" approach. But this event is "consumed" (that is, waited upon either on host or on the device) multiple times, since many tasks in different streams depend on the coordinates.
This function return the number of times the event will be consumed based on this step's workload.
| simulationWork | Simulation workload flags. |
| stepWork | Step workload flags. |
| domainWork | Domain workload flags. |
| pmeSendCoordinatesFromGpu | Whether peer-to-peer communication is used for PME coordinates. |
| domainHasHomeAtoms | Whether this domain has home atoms |
|
static |
Get the internal file type from the filename.
| [in] | filename | Filename of output file. |
| InvalidInputError | When unable to work on an emoty file name. |
|
inlinestatic |
Calculate atom range and return start index and length.
| [in] | atomData | Atom descriptor data structure |
| [in] | atomLocality | Atom locality specifier |
|
inline |
Return the base name (last component of the HDF-path) of an HDF5 handle.
| [in] | handle | HDF5 handle to get the base name of. |
std::nullopt on error.
|
inline |
Return the full name (HDF-path) of an HDF5 handle.
| [in] | handle | HDF5 handle to get the name of. |
std::nullopt if the handle is invalid.
|
static |
Returns a diagonal or off-diagonal interaction mask.
| iClusterSize | The i-cluster size |
| jClusterSize | The j-cluster size |
| [in] | maskOutSubDiagonal | Whether to mask out the sub-diagonal interactions |
| [in] | ci | The i-cluster index |
| [in] | cj | The j-cluster index |
|
static |
Map a value to the nearest point in the grid.
| [in] | value | Value. |
| [in] | axis | The grid axes. |
|
static |
Return a page size, from a sysconf/WinAPI query if available, or a default guess (4096 bytes).
Returns the PBC mode based on the system PBC and vsite properties.
| [in] | pbcPtr | A pointer to a PBC struct or nullptr when no PBC treatment is required |
| double gmx::getSqrtDeterminant | ( | gmx::ArrayRef< const double > | correlationIntegral | ) |
Returns the volume element of the correlation metric.
The matrix of the metric equals the time-integrated correlation matrix. The volume element of the metric therefore equals the square-root of the absolute value of its determinant according to the standard formula for a volume element in a metric space.
The order of the tensor elements is: 1-dimensional tensor: [0] 2-dimensional tensor: [0 1; 1 2] 3-dimensional tensor: [0 1 3; 1 2 4; 3 4 5]
| [in] | correlationIntegral | A pre-filled vector of time integral elements. The correlation index lists the elements of the upper-triangular correlation matrix row-wise, so e.g. in 3D: 0 (0,0), 1 (1,0), 2 (1,1), 3 (2,0), 4 (2,1), 5 (2,2). |
|
static |
Get the flag representing the requirements for a given file output.
Also checks if the supplied topology is sufficient through the pointer to mtop.
| [in] | filetype | Internal file type used to check requirements. |
| InvalidInputError | When encountering an invalid file type. |
| double gmx::getTransformationPullCoordinateValue | ( | pull_coord_work_t * | coord, |
| ArrayRef< const pull_coord_work_t > | variableCoords, | ||
| double | t | ||
| ) |
Calculates pull->coord[coord_ind].spatialData.value for a transformation pull coordinate.
This requires the values of the pull coordinates of lower indices to be set
| [in] | coord | The (transformation) coordinate to compute the value for |
| [in] | variableCoords | Pull coordinates used as variables, entries 0 to coord->coordIndex will be used |
| [in] | t | The time |
| InconsistentInputError | when the expression uses coordinates with index equal to or larger than the index of coord. |
| std::unique_ptr< gmx_hw_info_t > gmx::gmx_detect_hardware | ( | const PhysicalNodeCommunicator & | physicalNodeComm, |
| MPI_Comm | libraryCommWorld | ||
| ) |
Run detection and make correct and consistent hardware information available on all ranks.
May do communication on libraryCommWorld when compiled with real MPI.
This routine is designed to be called once on each process. In a thread-MPI configuration, it may only be called before the threads are spawned. With real MPI, communication is needed to coordinate the results. In all cases, any thread within a process may use the returned handle.
| int gmx::gmx_mdrun | ( | int | argc, |
| char * | argv[] | ||
| ) |
Implements C-style main function for mdrun.
This implementation detects hardware itself, as suits the gmx wrapper binary.
| [in] | argc | Number of C-style command-line arguments |
| [in] | argv | C-style command-line argument strings |
| int gmx::gmx_mdrun | ( | MPI_Comm | communicator, |
| const gmx_hw_info_t & | hwinfo, | ||
| int | argc, | ||
| char * | argv[] | ||
| ) |
Implements C-style main function for mdrun.
This implementation facilitates reuse of infrastructure. This includes the information about the hardware detected across the given communicator. That suits e.g. efficient implementation of test fixtures.
| [in] | communicator | The communicator to use for the simulation |
| [in] | hwinfo | Describes the hardware detected on the physical nodes of the communicator |
| [in] | argc | Number of C-style command-line arguments |
| [in] | argv | C-style command-line argument strings |
| void gmx::gmx_nb_free_energy_kernel | ( | const AtomPairlist & | nlist, |
| const ArrayRefWithPadding< const RVec > & | coords, | ||
| bool | useSimd, | ||
| int | ntype, | ||
| const interaction_const_t & | ic, | ||
| ArrayRef< const RVec > | shiftvec, | ||
| ArrayRef< const real > | nbfp, | ||
| ArrayRef< const real > | nbfp_grid, | ||
| ArrayRef< const real > | chargeA, | ||
| ArrayRef< const real > | chargeB, | ||
| ArrayRef< const int > | typeA, | ||
| ArrayRef< const int > | typeB, | ||
| bool | computeForeignLambda, | ||
| const StepWorkload * | stepWork, | ||
| ArrayRef< const real > | lambda, | ||
| t_nrnb *gmx_restrict | nrnb, | ||
| ArrayRefWithPadding< RVec > | threadForceBuffer, | ||
| rvec * | threadForceShiftBuffer, | ||
| ArrayRef< real > | threadVc, | ||
| ArrayRef< real > | threadVv, | ||
| ArrayRef< real > | threadDvdl | ||
| ) |
The non-bonded free-energy kernel.
| [in] | nlist | A plain atom pair list containing only perturbed interactions |
| [in] | coords | The list of local and non-local coordinates |
| [in] | useSimd | Whether to use the SIMD intrinsics kernel |
| [in] | ntype | The number of non-bonded atom types |
| [in] | ic | The non-bonded interactions constants |
| [in] | shiftvec | The periodic shift vectors |
| [in] | nbfp | The matrix of LJ parameters between atom types |
| [in] | nbfp_grid | The matrix of LJ parameters for PME grid corrections |
| [in] | chargeA | List of charges per atom for state A |
| [in] | chargeB | List of charges per atom for state B |
| [in] | typeA | List of LJ atom types per atom for state A |
| [in] | typeB | List of LJ atom types per atom for state B |
| [in] | computeForeignLambda | When true, only compute energies and dV/dlambda, igore stepWork |
| [in] | stepWork | Tells what to compute, ignored and can be nullptr when computeForeignLambda=true |
| [in] | lambda | List of free-energy lambdas for different components |
| [in,out] | nrnb | Flop counters to add to |
| [in,out] | threadForceBuffer | Thread-local force buffer to accumulate into |
| [in,out] | threadForceShiftBuffer | Thread-local shift force buffer to accumulate into |
| [in,out] | threadVc | Thread-local Coulomb energy group pair buffer to accumulate into |
| [in,out] | threadVv | Thread-local VdW energy group pair buffer to accumulate into |
| [in,out] | threadDvdl | Thread-local dV/dlambda component buffer to accumulate into |
| InvalidInputError | when an excluded pair is beyond the rcoulomb with reaction-field. |
|
inlinestatic |
Do the per-step timing accounting of the nonbonded tasks.
Does timing accumulation and call-count increments for the nonbonded kernels. Note that this function should be called after the current step's nonbonded nonbonded tasks have completed with the exception of the rolling pruning kernels that are accounted for during the following step.
NOTE: if timing with multiple GPUs (streams) becomes possible, the counters could end up being inconsistent due to not being incremented on some of the node when this is skipped on empty local domains!
| GpuPairlist | Pair list type |
| [out] | timings | Pointer to the NB GPU timings data |
| [in] | timers | Pointer to GPU timers data |
| [in] | plist | Pointer to the pair list data |
| [in] | atomLocality | Atom locality specifier |
| [in] | stepWork | Force schedule flags |
| [in] | doTiming | True if timing is enabled. |
| void gmx::gpu_clear_outputs | ( | NbnxmGpu gmx_unused * | nb, |
| bool gmx_unused | computeVirial | ||
| ) |
Clears GPU outputs: nonbonded force, shift force and energy.
| void gmx::gpu_copy_xq_to_gpu | ( | NbnxmGpu gmx_unused * | nb, |
| const struct nbnxn_atomdata_t gmx_unused * | nbdata, | ||
| AtomLocality gmx_unused | aloc | ||
| ) |
Launch asynchronously the xq buffer host to device copy.
The nonlocal copy is skipped if there is no dependent work to do, neither non-local nonbonded interactions nor bonded GPU work.
| [in] | nb | GPU nonbonded data. |
| [in] | nbdata | Host-side atom data structure. |
| [in] | aloc | Atom locality flag. |
| void gmx::gpu_free | ( | NbnxmGpu gmx_unused * | nb | ) |
Frees all GPU resources used for the nonbonded calculations.
| void gmx::gpu_free_platform_specific | ( | NbnxmGpu * | nb | ) |
Releases the NBNXM GPU data structures.
This function is documented in the header file.
| struct gmx_wallclock_gpu_nbnxn_t* gmx::gpu_get_timings | ( | NbnxmGpu gmx_unused * | nb | ) |
Returns the GPU timings structure or NULL if GPU is not used or timing is off.
| NbnxmGpu* gmx::gpu_init | ( | const DeviceStreamManager gmx_unused & | deviceStreamManager, |
| const interaction_const_t gmx_unused * | ic, | ||
| const PairlistParams gmx_unused & | listParams, | ||
| const nbnxn_atomdata_t gmx_unused * | nbat, | ||
| bool gmx_unused | bLocalAndNonlocal, | ||
| const std::optional< int > gmx_unused | nLambda | ||
| ) |
Initializes the data structures related to GPU nonbonded calculations.
| void gmx::gpu_init_atomdata | ( | NbnxmGpu gmx_unused * | nb, |
| const nbnxn_atomdata_t gmx_unused * | nbat | ||
| ) |
Initializes atom-data on the GPU, called at every pair search step.
| void gmx::gpu_init_feppairlist | ( | NbnxmGpu gmx_unused * | nb, |
| const AtomPairlist gmx_unused & | h_feplist, | ||
| InteractionLocality gmx_unused | iloc, | ||
| const GridSet gmx_unused & | gridSet | ||
| ) |
Initializes fep pair-list data for GPU, called at every pair search step.
| void gmx::gpu_init_pairlist | ( | NbnxmGpu gmx_unused * | nb, |
| const struct NbnxnPairlistGpu gmx_unused * | h_nblist, | ||
| InteractionLocality gmx_unused | iloc | ||
| ) |
Initializes pair-list data for GPU, called at every pair search step.
| bool gmx::gpu_is_kernel_ewald_analytical | ( | const NbnxmGpu gmx_unused * | nb | ) |
Returns if analytical Ewald GPU kernels are used.
| void gmx::gpu_launch_free_energy_kernel | ( | NbnxmGpu gmx_unused * | nb, |
| const SimulationWorkload gmx_unused & | simulationWork, | ||
| const gmx::StepWorkload gmx_unused & | stepWork, | ||
| const InteractionLocality gmx_unused | iloc | ||
| ) |
Launch asynchronously the nonbonded free energy calculations.
Launch the Nonbonded free energy GPU kernels.
| void gmx::gpu_launch_kernel | ( | NbnxmGpu gmx_unused * | nb, |
| const StepWorkload gmx_unused & | stepWork, | ||
| InteractionLocality gmx_unused | iloc | ||
| ) |
Launch asynchronously the nonbonded force calculations.
Also launches the initial pruning of a fresh list after search.
The local and non-local interaction calculations are launched in two separate streams. If there is no work (i.e. empty pair list), the force kernel launch is omitted.
| void gmx::gpu_launch_kernel | ( | NbnxmGpu * | nb, |
| const gmx::StepWorkload & | stepWork, | ||
| const InteractionLocality | iloc | ||
| ) |
Launch GPU kernel.
As we execute nonbonded workload in separate queues, before launching the kernel we need to make sure that he following operations have completed:
These operations are issued in the local queue at the beginning of the step and therefore always complete before the local kernel launch. The non-local kernel is launched after the local on the same device/context, so this is inherently scheduled after the operations in the local stream (including the above "misc_ops"). However, for the sake of having a future-proof implementation, we use the misc_ops_done event to record the point in time when the above operations are finished and synchronize with this event in the non-local stream.
| void gmx::gpu_launch_kernel_pruneonly | ( | NbnxmGpu gmx_unused * | nb, |
| InteractionLocality gmx_unused | iloc, | ||
| int gmx_unused | numParts | ||
| ) |
Launch asynchronously the nonbonded prune-only kernel.
The local and non-local list pruning are launched in their separate streams.
Notes for future scheduling tuning: Currently we schedule the dynamic pruning between two MD steps after both local and nonlocal force D2H transfers completed. We could launch already after the cpyback is launched, but we want to avoid prune kernels (especially in the non-local high prio-stream) competing with nonbonded work.
However, this is not ideal as this schedule does not expose the available concurrency. The dynamic pruning kernel:
In the most general case, the former would require scheduling pruning in a separate stream and adding additional event sync points to ensure that force kernels read consistent pair list data. This would lead to some overhead (due to extra cudaStreamWaitEvent calls, 3-5 us/call) which we might be able to live with. The gains from additional overlap might not be significant as long as update+constraints anyway takes longer than pruning, but there will still be use-cases where more overlap may help (e.g. multiple ranks per GPU, no/hbonds only constraints). The above second point is harder to address given that multiple ranks will often share a GPU. Ranks that complete their nonbondeds sooner can schedule pruning earlier and without a third priority level it is difficult to avoid some interference of prune kernels with force tasks (in particular preemption of low-prio local force task).
| [in,out] | nb | GPU nonbonded data. |
| [in] | iloc | Interaction locality flag. |
| [in] | numParts | Number of parts the pair list is split into in the rolling kernel. |
| int gmx::gpu_min_ci_balanced | ( | NbnxmGpu gmx_unused * | nb | ) |
Calculates the minimum size of proximity lists to improve SM load balance with GPU non-bonded kernels.
|
inlinestatic |
Reduce free energy lambda data staged internally in the nbnxm module.
| [in] | nbst | Nonbonded staging data |
| [in] | iLocality | Interaction locality specifier |
| [in] | nLambda | Number of foreign lambdas |
| [out] | foreign_term | Variable to accumulate foreign lambda terms into |
|
inlinestatic |
Reduce data staged internally in the nbnxn module.
Shift forces and electrostatic/LJ energies copied from the GPU into a module-internal staging area are immediately reduced (CPU-side buffers passed) after having waited for the transfers' completion.
Note that this function should always be called after the transfers into the staging buffers has completed.
| [in] | nbst | Nonbonded staging data |
| [in] | iLocality | Interaction locality specifier |
| [in] | reduceEnergies | True if energy reduction should be done |
| [in] | reduceFshift | True if shift force reduction should be done |
| [out] | e_lj | Variable to accumulate LJ energy into |
| [out] | e_el | Variable to accumulate electrostatic energy into |
| [out] | dvdl_lj | Variable to accumulate LJ energy derivatives into |
| [out] | dvdl_el | Variable to accumulate electrostatic energy derivatives into |
| [out] | fshift | Pointer to the array of shift forces to accumulate into |
| void gmx::gpu_reset_timings | ( | struct nonbonded_verlet_t gmx_unused * | nbv | ) |
Resets nonbonded GPU timings.
| bool gmx::gpu_try_finish_task | ( | NbnxmGpu gmx_unused * | nb, |
| const StepWorkload gmx_unused & | stepWork, | ||
| AtomLocality gmx_unused | aloc, | ||
| real gmx_unused * | e_lj, | ||
| real gmx_unused * | e_el, | ||
| double gmx_unused * | dvdl_lj, | ||
| double gmx_unused * | dvdl_el, | ||
| ArrayRef< RVec > gmx_unused | shiftForces, | ||
| ForeignLambdaTerms gmx_unused * | foreign_term, | ||
| GpuTaskCompletion gmx_unused | completionKind | ||
| ) |
Attempts to complete nonbonded GPU task.
This function attempts to complete the nonbonded task (both GPU and CPU auxiliary work). Success, i.e. that the tasks completed and results are ready to be consumed, is signaled by the return value (always true if blocking wait mode requested).
The completionKind parameter controls whether the behavior is non-blocking (achieved by passing GpuTaskCompletion::Check) or blocking wait until the results are ready (when GpuTaskCompletion::Wait is passed). As the "Check" mode the function will return immediately if the GPU stream still contain tasks that have not completed, it allows more flexible overlapping of work on the CPU with GPU execution.
Note that it is only safe to use the results, and to continue to the next MD step when this function has returned true which indicates successful completion of
fshift, e_el, e_lj).In GpuTaskCompletion::Check mode this function does the timing and keeps correct count for the nonbonded task (incrementing only once per task), in the GpuTaskCompletion::Wait mode timing is expected to be done in the caller.
TODO: improve the handling of outputs e.g. by ensuring that this function explcitly returns the force buffer (instead of that being passed only to nbnxn_gpu_launch_cpyback()) and by returning the energy and Fshift contributions for some external/centralized reduction.
| [in] | nb | The nonbonded data GPU structure |
| [in] | stepWork | Step schedule flags |
| [in] | aloc | Atom locality identifier |
| [out] | e_lj | Pointer to the LJ energy output to accumulate into |
| [out] | e_el | Pointer to the electrostatics energy output to accumulate into |
| [out] | dvdl_lj | Pointer to the LJ DvDL output to accumulate into |
| [out] | dvdl_el | Pointer to the electrostatics DVDL output to accumulate into |
| [out] | shiftForces | Shift forces buffer to accumulate into |
| [out] | foreign_term | Foreign lambda terms buffer to accumulate into |
| [in] | completionKind | Indicates whether nnbonded task completion should only be checked rather than waited for |
aloc locality have completed | bool gmx::gpu_try_finish_task | ( | NbnxmGpu * | nb, |
| const StepWorkload & | stepWork, | ||
| const AtomLocality | aloc, | ||
| real * | e_lj, | ||
| real * | e_el, | ||
| double * | dvdl_lj, | ||
| double * | dvdl_el, | ||
| ArrayRef< RVec > | shiftForces, | ||
| ForeignLambdaTerms * | foreign_term, | ||
| GpuTaskCompletion | completionKind | ||
| ) |
Attempts to complete nonbonded GPU task.
See documentation in nbnxm_gpu.h for details.
| void gmx::gpu_upload_shiftvec | ( | NbnxmGpu gmx_unused * | nb, |
| const nbnxn_atomdata_t gmx_unused * | nbatom | ||
| ) |
Uploads shift vector to the GPU if the box is dynamic (otherwise just returns).
| float gmx::gpu_wait_finish_task | ( | NbnxmGpu gmx_unused * | nb, |
| const StepWorkload gmx_unused & | stepWork, | ||
| AtomLocality gmx_unused | aloc, | ||
| const bool gmx_unused | haveSoftCore, | ||
| gmx_enerdata_t gmx_unused * | enerd, | ||
| ArrayRef< RVec > gmx_unused | shiftForces, | ||
| gmx_wallcycle gmx_unused * | wcycle | ||
| ) |
Completes the nonbonded GPU task blocking until GPU tasks and data transfers to finish.
Also does timing accounting and reduction of the internal staging buffers. As this is called at the end of the step, it also resets the pair list and pruning flags.
| [in] | nb | The nonbonded data GPU structure |
| [in] | stepWork | Step schedule flags |
| [in] | aloc | Atom locality identifier |
| [in] | haveSoftCore | Whether SoftCore has been used |
| [out] | enerd | Pointer to the energy data to accumulate energies into |
| [out] | shiftForces | Shift forces buffer to accumulate into |
| [out] | wcycle | Pointer to wallcycle data structure |
| float gmx::gpu_wait_finish_task | ( | NbnxmGpu * | nb, |
| const StepWorkload & | stepWork, | ||
| AtomLocality | aloc, | ||
| const bool | haveSoftCore, | ||
| gmx_enerdata_t * | enerd, | ||
| ArrayRef< RVec > | shiftForces, | ||
| gmx_wallcycle * | wcycle | ||
| ) |
Wait for the asynchronously launched nonbonded tasks and data transfers to finish.
Also does timing accounting and reduction of the internal staging buffers. As this is called at the end of the step, it also resets the pair list and pruning flags.
| [in] | nb | The nonbonded data GPU structure |
| [in] | stepWork | Force schedule flags |
| [in] | aloc | Atom locality identifier |
| [in] | haveSoftCore | Whether SoftCore has been used |
| [out] | enerd | Pointer to the energy data to accumulate energies into |
| [out] | shiftForces | Shift forces buffer to accumulate into |
| [out] | wcycle | Pointer to wallcycle data structure |
| std::string gmx::gpuFftDescription | ( | ) |
Construct a string that describes the library that provides GPU FFT support to this build.
Returns information for describing the GPU FFT support.
| std::int64_t gmx::greatestCommonDivisor | ( | std::int64_t | p, |
| std::int64_t | q | ||
| ) |
Find greatest common divisor of two numbers.
| p | First number, positive |
| q | Second number, positive |
|
inlinestatic |
Do workgroup-level reduction of a single float.
While SYCL has sycl::reduce_over_group, it currently (oneAPI 2021.3.0) uses a very large shared memory buffer, which leads to a reduced occupancy.
sm_buf.| subGroupSize | Size of a sub-group. |
| groupSize | Size of a work-group. |
| itemIdx | Current thread's sycl::nd_item. |
| tidxi | Current thread's linearized local index. |
| sm_buf | Accessor for local reduction buffer. |
| valueToReduce | Current thread's value. Must have length of at least 1. |
tidxi 0: sum of all valueToReduce. Other threads: unspecified.
|
inlinenoexcept |
Return whether HDF5 handle is valid.
| [in] | handle | HDF5 handle to check. |
| std::tuple< StartingBehavior, LogFilePtr > gmx::handleRestart | ( | bool | isSimulationMain, |
| MPI_Comm | communicator, | ||
| const gmx_multisim_t * | ms, | ||
| AppendingBehavior | appendingBehavior, | ||
| int | nfile, | ||
| t_filenm | fnm[] | ||
| ) |
Handle startup of mdrun, particularly regarding -cpi and -append.
If there is a checkpoint file, then prepare to start from that state. If possible/required, do so with appending. If some files are not found when appending should be done, we will instead issue a fatal error to avoid unintentional problems.
If there is no checkpoint file, we return a value to indicate a new simulation is starting.
On return, fnm is updated with suffix strings for part numbers if we are doing a restart from checkpoint and are not appending. Output files may have been truncated if we are restarting from a checkpoint and are appending.
The routine also does communication to coordinate behaviour between all simulations, including for error conditions.
Note that this function looks like it does lots of different things that could be separated, but that is actually difficult. The starting behaviour can depend on the state of the filesystem and the contents of the checkpoint header, each of which we only want to read once, so we can't easily separate the decision of what to do from the details of doing it (e.g. changing output filenames or truncating output files).
| FileIOError | When the filesystem behavior prevents the user's choices being implemented. |
| InconsistentInputError | When the users's choices cannot be implemented. |
| ParallelConsistencyError | On ranks upon which the error condition was not detected. |
| [in] | isSimulationMain | Whether this rank is the main rank of a simulation |
| [in] | communicator | MPI communicator across which error behaviour must be kept consistent |
| [in] | ms | Handles multi-simulations. |
| [in] | appendingBehavior | User choice for appending |
| [in] | nfile | Size of fnm struct |
| [in,out] | fnm | Filename parameters to mdrun |
|
static |
Returns whether moltype has incompatible vsites.
For simplicity the only compatible vsites are linear 2 or 3 atom sites that are constructed in between the 2 or 3 contructing atoms,
|
static |
Function for whether the mapping has the GPU PME or Nonbonded task.
| [in] | mapping | Current GPU task mapping. |
|
static |
Function for whether the task of mapping has value TaskType.
| [in] | mapping | Current GPU task mapping. |
TaskType task was assigned to the mapping. | bool gmx::haveBiasSharingWithinSimulation | ( | const AwhParams & | awhParams | ) |
Returns if any bias is sharing within a simulation.
| [in] | awhParams | The AWH parameters. |
| bool gmx::haveGpuShortRangeWork | ( | const NbnxmGpu gmx_unused * | nb, |
| InteractionLocality gmx_unused | interactionLocality | ||
| ) |
Returns true if there is GPU short-range work for the given interaction locality.
Note that as, unlike nonbonded tasks, bonded tasks are not split into local/nonlocal, and therefore if there are GPU offloaded bonded interactions, this function will return true for both local and nonlocal atom range.
| [in,out] | nb | Pointer to the nonbonded GPU data structure |
| [in] | interactionLocality | Interaction locality identifier |
|
static |
Return true if there are special forces computed.
The conditionals exactly correspond to those in sim_util.cpp:computeSpecialForces().
| bool gmx::haveValidMtsSetup | ( | const t_inputrec & | ir | ) |
Returns whether we use MTS and the MTS setup is internally valid.
Note that setupMtsLevels would have returned at least one error message when this function returns false
|
noexcept |
Return a handle to a native HDF5 type corresponding to the templated value type.
The data type referenced by the handle is immutable and does not need to be closed.
| ValueType | Type of value. |
|
inlinenoexcept |
Return a handle to a native HDF5 type corresponding to the templated value type.
The data type referenced by the handle is immutable and does not need to be closed.
| ValueType | Type of value. |
|
inlinenoexcept |
Return a handle to a native HDF5 type corresponding to the templated value type.
The data type referenced by the handle is immutable and does not need to be closed.
| ValueType | Type of value. |
|
inlinenoexcept |
Return a handle to a native HDF5 type corresponding to the templated value type.
The data type referenced by the handle is immutable and does not need to be closed.
| ValueType | Type of value. |
|
inlinenoexcept |
Return a handle to a native HDF5 type corresponding to the templated value type.
The data type referenced by the handle is immutable and does not need to be closed.
| ValueType | Type of value. |
|
inlinenoexcept |
Return a handle to a native HDF5 type corresponding to the templated value type.
The data type referenced by the handle is immutable and does not need to be closed.
| ValueType | Type of value. |
|
inlinenoexcept |
Return a handle to a native HDF5 type corresponding to the templated value type.
The data type referenced by the handle is immutable and does not need to be closed.
| ValueType | Type of value. |
|
inline |
Return a handle to a HDF5 data type for fixed-size strings.
The string type is created with a UTF8 character set and null termination, so stored strings may be shorter than the maximum length but a fixed amount of memory is always allocated. Data sets of fixed size strings are contiguous in memory and can be compressed.
The returned handle must be closed with a call to H5Tclose to avoid leaking resources.
| [in] | maxStringLength | Fixed maximum size of string. |
| gmx::FileIOError | if maxStringLength is not a positive value. |
| int gmx::identifyAvx512FmaUnits | ( | ) |
Test whether machine has dual AVX512 FMA units.
| BasicMatrix3x3<ElementType> gmx::identityMatrix | ( | ) |
Create an identity matrix of ElementType.
| ElementType | type of matrix elements |
|
static |
Receive force indices and forces.
The number of forces was previously communicated via the header.
|
static |
Send positions from rvec.
We need a separate send buffer and conversion to Angstrom.
| int gmx::imd_sock_listen | ( | IMDSocket * | sock | ) |
Set socket to listening state.
Prints out an error message if unsuccessful.
| sock | The IMD socket. |
| IMDSocket * gmx::imdsock_accept | ( | IMDSocket * | sock | ) |
Accept incoming connection and redirect to client socket.
Prints out an error message if unsuccessful.
| sock | The IMD socket. |
| int gmx::imdsock_bind | ( | IMDSocket * | sock, |
| int | port | ||
| ) |
Bind the IMD socket to address and port.
Prints out an error message if unsuccessful. If port == 0, bind() assigns a free port automatically.
| sock | The IMD socket. |
| port | The port to bind to. |
| IMDSocket * gmx::imdsock_create | ( | ) |
Create an IMD main socket.
| int gmx::imdsock_destroy | ( | IMDSocket * | sock | ) |
Close the socket and free the sock struct memory.
Writes an error message if unsuccessful.
| sock | The IMD socket. |
| int gmx::imdsock_getport | ( | IMDSocket * | sock, |
| int * | port | ||
| ) |
Get the port number used for IMD connection.
Prints out an error message if unsuccessful.
| sock | The IMD socket. |
| port | The assigned port number. |
| int gmx::imdsock_read | ( | IMDSocket * | sock, |
| char * | buffer, | ||
| int | length | ||
| ) |
Read from socket.
| sock | The IMD socket. |
| buffer | Buffer to put the read data. |
| length | Number of bytes to read. |
| void gmx::imdsock_shutdown | ( | IMDSocket * | sock | ) |
Shutdown the socket.
| sock | The IMD socket. |
| int gmx::imdsock_tryread | ( | IMDSocket * | sock, |
| int | timeoutsec, | ||
| int | timeoutusec | ||
| ) |
Try to read from the socket.
Time out after waiting the interval specified. Print an error message if unsuccessful.
| sock | The IMD socket. |
| timeoutsec | Time out seconds |
| timeoutusec | Time out microseconds |
| int gmx::imdsock_write | ( | IMDSocket * | sock, |
| const char * | buffer, | ||
| int | length | ||
| ) |
Write to socket.
| sock | The IMD socket. |
| buffer | The data to write. |
| length | Number of bytes to write. |
| void gmx::increaseNstlist | ( | FILE * | fplog, |
| const MpiComm & | mpiCommSimulation, | ||
| t_inputrec * | ir, | ||
| int | nstlistOnCmdline, | ||
| const gmx_mtop_t * | mtop, | ||
| const matrix | box, | ||
| real | effectiveAtomDensity, | ||
| bool | useOrEmulateGpuForNonbondeds | ||
| ) |
Try to increase nstlist when using the Verlet cut-off scheme.
| [in,out] | fplog | Log file |
| [in] | mpiCommSimulation | MPI communicator for the whole simulation |
| [in] | ir | The input parameter record |
| [in] | nstlistOnCmdline | The value of nstlist provided on the command line |
| [in] | mtop | The global topology |
| [in] | box | The unit cell |
| [in] | effectiveAtomDensity | The effective atom density |
| [in] | useOrEmulateGpuForNonbondeds | Tells if we are using a GPU for non-bondeds |
|
inline |
Increment the pointer into shared memory.
| T | which type we use to calculate the new offset |
| void gmx::initCorrelationGridHistory | ( | CorrelationGridHistory * | correlationGridHistory, |
| int | numCorrelationTensors, | ||
| int | tensorSize, | ||
| int | blockDataListSize | ||
| ) |
Initialize correlation grid history, sets all sizes.
| [in,out] | correlationGridHistory | Correlation grid history for main rank. |
| [in] | numCorrelationTensors | Number of correlation tensors in the grid. |
| [in] | tensorSize | Number of correlation elements in each tensor. |
| [in] | blockDataListSize | The number of blocks in the list of each tensor element. |
| CorrelationGridHistory gmx::initCorrelationGridHistoryFromState | ( | const CorrelationGrid & | corrGrid | ) |
Allocate a correlation grid history with the same structure as the given correlation grid.
This function would be called at the start of a new simulation. Note that only sizes and memory are initialized here. History data is set by updateCorrelationGridHistory.
| [in,out] | corrGrid | Correlation grid state to initialize with. |
|
static |
Initializes a projection matrix.
| [in] | invmO | Reciprocal oxygen mass |
| [in] | invmH | Reciprocal hydrogen mass |
| [in] | dOH | Target O-H bond length |
| [in] | dHH | Target H-H bond length |
| [out] | inverseCouplingMatrix | Inverse bond coupling matrix for the projection version of SETTLE |
| bool gmx::inputSupportsListedForcesGpu | ( | const t_inputrec & | ir, |
| const gmx_mtop_t & | mtop, | ||
| std::string * | error | ||
| ) |
Checks whether the input system allows to compute bonded interactions on a GPU.
| [in] | ir | Input system. |
| [in] | mtop | Complete system topology to search for supported interactions. |
| [out] | error | If non-null, the error message if the input is not supported on GPU. |
|
static |
Checks if the given interval is defined in the correct periodic interval.
| [in] | origin | Start value of interval. |
| [in] | end | End value of interval. |
| [in] | period | Period (or 0 if not periodic). |
|
inlinestatic |
Calculate 1/x for float.
| x | Argument that must be nonzero. This routine does not check arguments. |
|
inlinestatic |
Calculate 1/x for double.
| x | Argument that must be nonzero. This routine does not check arguments. |
|
inlinestatic |
Calculate inverse cube root of x in single precision.
| x | Argument |
This routine is typically faster than using std::pow().
|
inlinestatic |
Calculate inverse sixth root of x in double precision.
| x | Argument |
This routine is typically faster than using std::pow().
|
inlinestatic |
Calculate inverse sixth root of integer x in double precision.
| x | Argument |
This routine is typically faster than using std::pow().
|
inlinestatic |
Invert a simulation-box matrix.
This routine assumes that src is a simulation-box matrix, i.e. has zeroes in the upper-right triangle.
| RangeError | if the product of the leading diagonal is too small. |
|
inlinestatic |
Invert a simulation-box matrix in src, return in dest.
This routine assumes that src is a simulation-box matrix, i.e. has zeroes in the upper-right triangle. A fatal error occurs if the product of the leading diagonal is too small. The inversion can be done "in place", i.e src and dest can be the same matrix.
| void gmx::invertMatrix | ( | const matrix | src, |
| matrix | dest | ||
| ) |
Invert a general 3x3 matrix in src, return in dest.
A fatal error occurs if the determinant is too small. src and dest cannot be the same matrix.
|
inlinestatic |
Calculate 1/x for double, but with single accuracy.
| x | Argument that must be nonzero. This routine does not check arguments. |
|
inlinestatic |
Calculate inverse sixth root of x in single precision.
| x | Argument, must be greater than zero. |
This routine is typically faster than using std::pow().
|
inlinestatic |
Calculate inverse sixth root of x in double precision.
| x | Argument, must be greater than zero. |
This routine is typically faster than using std::pow().
|
inlinestatic |
Calculate inverse sixth root of integer x in double precision.
| x | Argument, must be greater than zero. |
This routine is typically faster than using std::pow().
|
inlinestatic |
Calculate 1.0/sqrt(x) in single precision.
| x | Positive value to calculate inverse square root for |
For now this is implemented with std::sqrt(x) since gcc seems to do a decent job optimizing it. However, we might decide to use instrinsics or compiler-specific functions in the future.
|
inlinestatic |
Calculate 1.0/sqrt(x) in double precision, but single range.
| x | Positive value to calculate inverse square root for, must be in the input domain valid for single precision. |
For now this is implemented with std::sqrt(x). However, we might decide to use instrinsics or compiler-specific functions in the future, and then we want to have the freedom to do the first step in single precision.
|
inlinestatic |
Calculate 1.0/sqrt(x) for integer x in double precision.
| x | Positive value to calculate inverse square root for. |
|
inlinestatic |
Calculate 1/sqrt(x) for two floats.
| x0 | First argument, x0 must be positive - no argument checking. | |
| x1 | Second argument, x1 must be positive - no argument checking. | |
| [out] | out0 | Result 1/sqrt(x0) |
| [out] | out1 | Result 1/sqrt(x1) |
|
inlinestatic |
Calculate 1/sqrt(x) for two doubles.
| x0 | First argument, x0 must be positive - no argument checking. | |
| x1 | Second argument, x1 must be positive - no argument checking. | |
| [out] | out0 | Result 1/sqrt(x0) |
| [out] | out1 | Result 1/sqrt(x1) |
|
inlinestatic |
Calculate 1/sqrt(x) for two doubles, but with single accuracy.
| x0 | First argument, x0 must be positive - no argument checking. | |
| x1 | Second argument, x1 must be positive - no argument checking. | |
| [out] | out0 | Result 1/sqrt(x0) |
| [out] | out1 | Result 1/sqrt(x1) |
|
inlinestatic |
Calculate 1/sqrt(x) for double, but with single accuracy.
| x | Argument that must be >0. This routine does not check arguments. |
|
static |
Checks that device deviceInfo is compatible with GROMACS.
Vendor and OpenCL version support checks are executed an the result of these returned.
| [in] | deviceInfo | The device info pointer. |
|
static |
Checks that device deviceInfo is sane (ie can run a kernel).
Compiles and runs a dummy kernel to determine whether the given OpenCL device functions properly.
| [in] | deviceInfo | The device info pointer. |
| [out] | errorMessage | An error message related to a failing OpenCL API call. |
| std::bad_alloc | When out of memory. |
| EnumerationArrayType::EnumerationWrapperType gmx::keysOf | ( | const EnumerationArrayType & | ) |
Returns an object that provides iterators over the keys associated with EnumerationArrayType.
This helper function is useful in contexts where there is an object of an EnumerationArray, and we want to use a range-based for loop over the keys associated with it, and it would be inconvenient to use the very word EnumerationArray<...> type, nor introduce a using statement for this purpose. It is legal in C++ to call a static member function (such as keys()) via an object rather than the type, but clang-tidy warns about that. So instead we make available a free function that calls that static method.
| void gmx::labelInternalTopologyVersion | ( | const hid_t | baseContainer | ) |
Label the version of the internal topology module.
| [in] | baseContainer | The HDF5 container to write to. |
| void gmx::labelTopologyName | ( | const hid_t | baseContainer, |
| const char * | topName | ||
| ) |
Label the name of the simulation system.
| [in] | baseContainer | The HDF5 container to write to. |
| [in] | topName | The name of the topology. |
| void gmx::launchForceReductionKernel | ( | int | numAtoms, |
| int | atomStart, | ||
| bool | addRvecForce, | ||
| bool | accumulate, | ||
| const DeviceBuffer< Float3 > | d_nbnxmForceToAdd, | ||
| const DeviceBuffer< Float3 > | d_rvecForceToAdd, | ||
| DeviceBuffer< Float3 > | d_baseForce, | ||
| DeviceBuffer< int > | d_cell, | ||
| const DeviceStream & | deviceStream, | ||
| DeviceBuffer< uint64_t > | d_forcesReadyNvshmemFlags, | ||
| const uint64_t | forcesReadyNvshmemFlagsCounter | ||
| ) |
Backend-specific function to launch GPU Force Reduction kernel.
Select templated Force reduction kernel and launch it.
In pseudocode:
| numAtoms | Number of atoms subject to reduction. |
| atomStart | First atom index (for d_rvecForceToAdd and d_baseForce). |
| addRvecForce | When false, d_rvecForceToAdd is ignored. |
| accumulate | When false, the previous values of d_baseForce are discarded. |
| d_nbnxmForceToAdd | Buffer containing Nbnxm forces in Nbnxm layout. |
| d_rvecForceToAdd | Optional buffer containing arbitrary forces in linear layout. |
| d_baseForce | Destination buffer for forces in linear layout. |
| d_cell | Atom index to Nbnxm cell index. |
| deviceStream | Device stream for kernel submission. |
| d_forcesReadyNvshmemFlags | NVSHMEM signals from PME to PP force transfer. |
| forcesReadyNvshmemFlagsCounter | Tracks NVSHMEM signal from PME to PP force transfer. |
| void gmx::launchLeapFrogKernel | ( | int | numAtoms, |
| DeviceBuffer< Float3 > | d_x, | ||
| DeviceBuffer< Float3 > | d_x0, | ||
| DeviceBuffer< Float3 > | d_v, | ||
| DeviceBuffer< Float3 > | d_f, | ||
| DeviceBuffer< float > | d_inverseMasses, | ||
| float | dt, | ||
| bool | doTemperatureScaling, | ||
| int | numTempScaleValues, | ||
| DeviceBuffer< unsigned short > | d_tempScaleGroups, | ||
| DeviceBuffer< float > | d_lambdas, | ||
| ParrinelloRahmanVelocityScaling | parrinelloRahmanVelocityScaling, | ||
| Float3 | prVelocityScalingMatrixDiagonal, | ||
| const DeviceStream & | deviceStream | ||
| ) |
Backend-specific function to launch GPU Leap Frog kernel.
| numAtoms | Total number of atoms. | |
| [in,out] | d_x | Buffer containing initial coordinates, and where the updated ones will be written. |
| [out] | d_x0 | Buffer where a copy of the initial coordinates will be written. |
| [in,out] | d_v | Buffer containing initial velocities, and where the updated ones will be written. |
| [in] | d_f | Buffer containing forces. |
| [in] | d_inverseMasses | Buffer containing atoms' reciprocal masses. |
| dt | Timestep. | |
| doTemperatureScaling | Whether temperature scaling is needed. | |
| numTempScaleValues | Number of different T-couple values. | |
| d_tempScaleGroups | Mapping of atoms into temperature scaling groups. | |
| d_lambdas | Temperature scaling factors (one per group). | |
| parrinelloRahmanVelocityScaling | The properties of the Parrinello-Rahman velocity scaling matrix. | |
| prVelocityScalingMatrixDiagonal | Diagonal elements of Parrinello-Rahman velocity scaling matrix. | |
| deviceStream | Device stream for kernel launch. |
| void gmx::launchLincsGpuKernel | ( | LincsGpuKernelParameters * | kernelParams, |
| const DeviceBuffer< Float3 > & | d_x, | ||
| DeviceBuffer< Float3 > | d_xp, | ||
| bool | updateVelocities, | ||
| DeviceBuffer< Float3 > | d_v, | ||
| real | invdt, | ||
| bool | computeVirial, | ||
| const DeviceStream & | deviceStream | ||
| ) |
Backend-specific function to launch LINCS kernel.
| kernelParams | LINCS parameters. |
| d_x | Initial coordinates before the integration. |
| d_xp | Coordinates after the integration which will be updated. |
| updateVelocities | Whether to also update velocities. |
| d_v | Velocities to update (ignored if updateVelocities is false). |
| invdt | Reciprocal of timestep. |
| computeVirial | Whether to compute the virial. |
| deviceStream | Device stream for kernel launch. |
| void gmx::launchNbnxmKernel | ( | NbnxmGpu * | nb, |
| const StepWorkload & | stepWork, | ||
| InteractionLocality | iloc, | ||
| bool | doPrune | ||
| ) |
Launch HIP NBNXM kernel.
Launch SYCL NBNXM kernel.
| nb | Non-bonded parameters. |
| stepWork | Workload flags for the current step. |
| iloc | Interaction locality. |
| doPrune | Whether to do neighborlist pruning. |
| void gmx::launchNbnxmKernelPruneOnly | ( | NbnxmGpu * | nb, |
| const InteractionLocality | iloc, | ||
| const int * | numParts, | ||
| const int | numSciInPart | ||
| ) |
Launch HIP NBNXM prune-only kernel.
| nb | Non-bonded parameters. |
| iloc | Interaction locality. |
| numParts | Total number of rolling-prune parts. |
| numSciInPart | Number of superclusters in part. |
| void gmx::launchNbnxmKernelPruneOnly | ( | NbnxmGpu * | nb, |
| const InteractionLocality | iloc, | ||
| const int | numParts, | ||
| const int | numSciInPartMax | ||
| ) |
Launch SYCL NBNXM prune-only kernel.
| nb | Non-bonded parameters. |
| iloc | Interaction locality. |
| numParts | Total number of rolling-prune parts. |
| numSciInPartMax | Maximum number of superclusters in a part. |
| void gmx::launchNbnxmKernelTransformXToXq | ( | const Grid & | grid, |
| NbnxmGpu * | nb, | ||
| DeviceBuffer< Float3 > | d_x, | ||
| const DeviceStream & | deviceStream, | ||
| const unsigned int | numColumnsMax, | ||
| const int | gridId | ||
| ) |
Launch coordinate layout conversion kernel.
| [in] | grid | Pair-search grid. |
| [in,out] | nb | Nbnxm main structure. |
| [in] | d_x | Source atom coordinates. |
| [in] | deviceStream | Device stream for kernel submission. |
| [in] | numColumnsMax | Max. number of columns per grid for offset calculation in nb. |
| [in] | gridId | Grid index for offset calculation in nb. |
|
static |
Launch the FFT and gather stages of PME GPU.
This function only implements setting the output forces (no accumulation).
| [in] | pmedata | The PME structure |
| [in] | lambdaQ | The Coulomb lambda of the current system state. |
| [in] | wcycle | The wallcycle structure |
| [in] | stepWork | Step schedule flags |
|
inlinestatic |
Launch the prepare_step and spread stages of PME GPU.
| [in] | pmedata | The PME structure |
| [in] | box | The box matrix |
| [in] | simulationWork | Simulation schedule flags |
| [in] | stepWork | Step schedule flags |
| [in] | xReadyOnDevice | Event synchronizer indicating that the coordinates are ready in the device memory. |
| [in] | lambdaQ | The Coulomb lambda of the current state. |
| [in] | useMdGpuGraph | Whether MD GPU Graph is in use. |
| [in] | wcycle | The wallcycle structure |
| void gmx::launchScaleCoordinatesKernel | ( | int | numAtoms, |
| DeviceBuffer< Float3 > | d_coordinates, | ||
| const ScalingMatrix & | mu, | ||
| const DeviceStream & | deviceStream | ||
| ) |
Launches positions of velocities scaling kernel.
| [in] | numAtoms | Number of atoms in the system. |
| [in] | d_coordinates | Device buffer with position or velocities to be scaled. |
| [in] | mu | Scaling matrix. |
| [in] | deviceStream | Stream to launch kernel in. |
| void gmx::launchSettleGpuKernel | ( | int | numSettles, |
| const DeviceBuffer< WaterMolecule > & | d_atomIds, | ||
| const SettleParameters & | settleParameters, | ||
| const DeviceBuffer< Float3 > & | d_x, | ||
| DeviceBuffer< Float3 > | d_xp, | ||
| bool | updateVelocities, | ||
| DeviceBuffer< Float3 > | d_v, | ||
| real | invdt, | ||
| bool | computeVirial, | ||
| DeviceBuffer< float > | d_virialScaled, | ||
| const PbcAiuc & | pbcAiuc, | ||
| const DeviceStream & | deviceStream | ||
| ) |
Apply SETTLE.
Applies SETTLE to coordinates and velocities, stored on GPU. Data at pointers d_xp and d_v change in the GPU memory. The results are not automatically copied back to the CPU memory. Method uses this class data structures which should be updated when needed using update method.
| [in] | numSettles | Number of SETTLE constraints. |
| [in] | d_atomIds | Device buffer with indices of atoms to be SETTLEd. |
| [in] | settleParameters | Parameters for SETTLE constraints. |
| [in] | d_x | Coordinates before timestep (in GPU memory) |
| [in,out] | d_xp | Coordinates after timestep (in GPU memory). The resulting constrained coordinates will be saved here. |
| [in] | updateVelocities | If the velocities should be updated. |
| [in,out] | d_v | Velocities to update (in GPU memory, can be nullptr if not updated) |
| [in] | invdt | Reciprocal timestep (to scale Lagrange multipliers when velocities are updated) |
| [in] | computeVirial | If virial should be updated. |
| [in,out] | d_virialScaled | Scaled virial tensor to be updated. |
| [in] | pbcAiuc | PBC data. |
| [in] | deviceStream | Device stream to launch kernel in. |
| auto gmx::leapFrogKernel | ( | Float3 *__restrict__ | gm_x, |
| Float3 *__restrict__ | gm_x0, | ||
| Float3 *__restrict__ | gm_v, | ||
| const Float3 *__restrict__ | gm_f, | ||
| const float *__restrict__ | gm_inverseMasses, | ||
| float | dt, | ||
| const float *__restrict__ | gm_lambdas, | ||
| const unsigned short *__restrict__ | gm_tempScaleGroups, | ||
| Float3 | prVelocityScalingMatrixDiagonal | ||
| ) |
Main kernel for the Leap-Frog integrator.
The coordinates and velocities are updated on the GPU. Also saves the intermediate values of the coordinates for further use in constraints.
Each GPU thread works with a single particle.
| numTempScaleValues | The number of different T-couple values. |
| parrinelloRahmanVelocityScaling | The properties of the Parrinello-Rahman velocity scaling matrix. |
| [in,out] | gm_x | Coordinates to update upon integration. |
| [out] | gm_x0 | A copy of the coordinates before the integration (for constraints). |
| [in,out] | gm_v | Velocities to update. |
| [in] | gm_f | Atomic forces. |
| [in] | gm_inverseMasses | Reciprocal masses. |
| [in] | dt | Timestep. |
| [in] | gm_lambdas | Temperature scaling factors (one per group). |
| [in] | gm_tempScaleGroups | Mapping of atoms into groups. |
| [in] | prVelocityScalingMatrixDiagonal | Diagonal elements of Parrinello-Rahman velocity scaling matrix. |
|
static |
Do a set of nrec LINCS matrix multiplications.
This function will return with up to date thread-local constraint data, without an OpenMP barrier.
| auto gmx::lincsKernel | ( | sycl::handler & | cgh, |
| const int | numConstraintsThreads, | ||
| const AtomPair *__restrict__ | gm_constraints, | ||
| const float *__restrict__ | gm_constraintsTargetLengths, | ||
| const int *__restrict__ | gm_coupledConstraintsCounts, | ||
| const int *__restrict__ | gm_coupledConstraintsIndices, | ||
| const float *__restrict__ | gm_massFactors, | ||
| float *__restrict__ | gm_matrixA, | ||
| const float *__restrict__ | gm_inverseMasses, | ||
| const int | numIterations, | ||
| const int | expansionOrder, | ||
| const Float3 *__restrict__ | gm_x, | ||
| Float3 *__restrict__ | gm_xp, | ||
| const float | invdt, | ||
| Float3 *__restrict__ | gm_v, | ||
| float *__restrict__ | gm_virialScaled, | ||
| PbcAiuc | pbcAiuc | ||
| ) |
Main kernel for LINCS constraints.
See Hess et al., J. Comput. Chem. 18: 1463-1472 (1997) for the description of the algorithm.
In GPU version, one thread is responsible for all computations for one constraint. The blocks are filled in a way that no constraint is coupled to the constraint from the next block. This is achieved by moving active threads to the next block, if the correspondent group of coupled constraints is to big to fit the current thread block. This may leave some 'dummy' threads in the end of the thread block, i.e. threads that are not required to do actual work. Since constraints from different blocks are not coupled, there is no need to synchronize across the device. However, extensive communication in a thread block are still needed.
Reduce synchronization overhead. Some ideas are:
The use of restrict for gm_xp and gm_v causes failure, probably because of the atomic operations. Investigate this issue further.
| updateVelocities | Whether velocities should be updated this step. |
| computeVirial | Whether virial tensor should be computed this step. |
| haveCoupledConstraints | If there are coupled constraints (i.e. LINCS iterations are needed). |
| [in] | cgh | SYCL handler. |
| [in] | numConstraintsThreads | Total number of threads. |
| [in] | gm_constraints | List of constrained atoms. |
| [in] | gm_constraintsTargetLengths | Equilibrium distances for the constraints. |
| [in] | gm_coupledConstraintsCounts | Number of constraints, coupled with the current one. |
| [in] | gm_coupledConstraintsIndices | List of coupled with the current one. |
| [in] | gm_massFactors | Mass factors. |
| [in] | gm_matrixA | Elements of the coupling matrix. |
| [in] | gm_inverseMasses | 1/mass for all atoms. |
| [in] | numIterations | Number of iterations used to correct the projection. |
| [in] | expansionOrder | Order of expansion when inverting the matrix. |
| [in] | gm_x | Unconstrained positions. |
| [in,out] | gm_xp | Positions at the previous step, will be updated. |
| [in] | invdt | Inverse timestep (needed to update velocities). |
| [in,out] | gm_v | Velocities of atoms, will be updated if updateVelocities. |
| [in,out] | gm_virialScaled | Scaled virial tensor (6 floats: [XX, XY, XZ, YY, YZ, ZZ]). Will be updated if updateVirial. |
| [in] | pbcAiuc | Periodic boundary data. |
| void gmx::linearArrayIndexToMultiDim | ( | int | indexLinear, |
| int | ndim, | ||
| const awh_ivec | numPointsDim, | ||
| awh_ivec | indexMulti | ||
| ) |
Convert a linear array index to a multidimensional one.
| [in] | indexLinear | Linear array index |
| [in] | ndim | Number of dimensions of the array. |
| [in] | numPointsDim | Number of points for each dimension. |
| [out] | indexMulti | The multidimensional index. |
| void gmx::linearGridindexToMultiDim | ( | const BiasGrid & | grid, |
| int | indexLinear, | ||
| awh_ivec | indexMulti | ||
| ) |
Convert a linear grid point index to a multidimensional one.
| [in] | grid | The grid. |
| [in] | indexLinear | Linear grid point index to convert to a multidimensional one. |
| [out] | indexMulti | The multidimensional index. |
|
inlinestatic |
Load function that returns SIMD or scalar.
Note that a load of T* where T is const returns a value, which is a copy, and the caller cannot be constrained to not change it, so the return type uses std::remove_const_t.
| T | Type to load (type is always mandatory) |
| m | Pointer to aligned memory |
|
inlinestatic |
Load function that returns SIMD or scalar based on template argument.
| T | Type to load (type is always mandatory) |
| m | Pointer to unaligned memory |
|
inlinestatic |
Float log(x). This is the natural logarithm.
| x | Argument, should be >0. |
|
inlinestatic |
Double log(x). This is the natural logarithm.
| x | Argument, should be >0. |
| unsigned int gmx::log2I | ( | std::uint32_t | x | ) |
Compute floor of logarithm to base 2, 32 bit unsigned argument.
| x | 32-bit unsigned argument |
| unsigned int gmx::log2I | ( | std::uint64_t | x | ) |
Compute floor of logarithm to base 2, 64 bit unsigned argument.
| x | 64-bit unsigned argument |
| unsigned int gmx::log2I | ( | std::int32_t | x | ) |
Compute floor of logarithm to base 2, 32 bit signed argument.
| x | 32-bit signed argument |
| unsigned int gmx::log2I | ( | std::int64_t | x | ) |
Compute floor of logarithm to base 2, 64 bit signed argument.
| x | 64-bit signed argument |
| void gmx::logHardwareDetectionWarnings | ( | const gmx::MDLogger & | mdlog, |
| const gmx_hw_info_t & | hardwareInformation | ||
| ) |
Issue warnings to mdlog that were decided during detection.
| [in] | mdlog | Logger |
| [in] | hardwareInformation | The hardwareInformation |
|
inlinestatic |
Double log(x), but with single accuracy. This is the natural logarithm.
| x | Argument, should be >0. |
| ListOfLists< int > gmx::make_at2con | ( | int | numAtoms, |
| const gmx::EnumerationArray< InteractionFunction, InteractionList > & | ilist, | ||
| ArrayRef< const t_iparams > | iparams, | ||
| FlexibleConstraintTreatment | flexibleConstraintTreatment | ||
| ) |
Returns a ListOfLists object to go from atoms to constraints.
The object will contain constraint indices with lower indices directly matching the order in InteractionFunction::Constraints and higher indices matching the order in InteractionFunction::ConstraintsNoCoupling offset by the number of constraints in InteractionFunction::Constraints.
| [in] | numAtoms | The number of atoms to construct the list for |
| [in] | ilist | Interaction list, size InteractionFunction::Count |
| [in] | iparams | Interaction parameters, can be null when flexibleConstraintTreatment==Include |
| [in] | flexibleConstraintTreatment | The flexible constraint treatment, see enum above |
| ListOfLists< int > gmx::make_at2con | ( | const gmx_moltype_t & | moltype, |
| gmx::ArrayRef< const t_iparams > | iparams, | ||
| FlexibleConstraintTreatment | flexibleConstraintTreatment | ||
| ) |
Returns a ListOfLists object to go from atoms to constraints.
The object will contain constraint indices with lower indices directly matching the order in InteractionFunction::Constraints and higher indices matching the order in InteractionFunction::ConstraintsNoCoupling offset by the number of constraints in InteractionFunction::Constraints.
| [in] | moltype | The molecule data |
| [in] | iparams | Interaction parameters, can be null when flexibleConstraintTreatment==Include |
| [in] | flexibleConstraintTreatment | The flexible constraint treatment, see enum above |
| void gmx::make_local_shells | ( | const gmx_domdec_t * | dd, |
| const t_mdatoms & | md, | ||
| gmx_shellfc_t * | shfc | ||
| ) |
Gets the local shell with domain decomposition.
| [in] | dd | Domain decomposition struct, can be nullptr |
| [in] | md | The MD atom data |
| [in,out] | shfc | The shell/flexible-constraint data |
| ArrayRef< bool > gmx::makeArrayRef | ( | std::vector< BoolType > & | boolVector | ) |
| ArrayRef<std::conditional_t<std::is_const_v<T>, const typename T::value_type, typename T::value_type> > gmx::makeArrayRef | ( | T & | c | ) |
|
static |
Returns a block struct to go from atoms to constraints.
The block struct will contain constraint indices with lower indices directly matching the order in InteractionFunction::Constraints and higher indices matching the order in InteractionFunction::ConstraintsNoCoupling offset by the number of constraints in InteractionFunction::Constraints.
| [in] | numAtoms | The number of atoms to construct the list for |
| [in] | ilists | The interaction lists, size InteractionFunction::Count |
| [in] | iparams | Interaction parameters, can be null when flexibleConstraintTreatment==Include |
| [in] | flexibleConstraintTreatment | The flexible constraint treatment, see enum above |
|
static |
Makes a per-moleculetype container of mappings from atom indices to constraint indices.
Note that flexible constraints are only enabled with a dynamical integrator.
|
static |
Returns the an array with group indices for each atom.
| [in] | grouping | The partitioning of the atom range into atom groups |
| void gmx::makeClusterListSimd2xMM | ( | const Grid & | jGrid, |
| NbnxnPairlistCpu * | nbl, | ||
| int | icluster, | ||
| int | firstCell, | ||
| int | lastCell, | ||
| bool | excludeSubDiagonal, | ||
| const real *gmx_restrict | x_j, | ||
| real | rlist2, | ||
| float | rbb2, | ||
| int *gmx_restrict | numDistanceChecks | ||
| ) |
SIMD code for checking and adding cluster-pairs to the list using the 2xMM layout.
Checks bounding box distances and possibly atom pair distances. This is an accelerated version of make_cluster_list_simple.
| [in] | jGrid | The j-grid |
| [in,out] | nbl | The pair-list to store the cluster pairs in |
| [in] | icluster | The index of the i-cluster |
| [in] | firstCell | The first cluster in the j-range, using i-cluster size indexing |
| [in] | lastCell | The last cluster in the j-range, using i-cluster size indexing |
| [in] | excludeSubDiagonal | Exclude atom pairs with i-index > j-index |
| [in] | x_j | Coordinates for the j-atom, in SIMD packed format |
| [in] | rlist2 | The squared list cut-off |
| [in] | rbb2 | The squared cut-off for putting cluster-pairs in the list based on bounding box distance only |
| [in,out] | numDistanceChecks | The number of distance checks performed |
| void gmx::makeClusterListSimd4xM | ( | const Grid & | jGrid, |
| NbnxnPairlistCpu * | nbl, | ||
| int | icluster, | ||
| int | firstCell, | ||
| int | lastCell, | ||
| bool | excludeSubDiagonal, | ||
| const real *gmx_restrict | x_j, | ||
| real | rlist2, | ||
| float | rbb2, | ||
| int *gmx_restrict | numDistanceChecks | ||
| ) |
SIMD code for checking and adding cluster-pairs to the list using the 4xM layout.
Checks bounding box distances and possibly atom pair distances. This is an accelerated version of make_cluster_list_simple.
| [in] | jGrid | The j-grid |
| [in,out] | nbl | The pair-list to store the cluster pairs in |
| [in] | icluster | The index of the i-cluster |
| [in] | firstCell | The first cluster in the j-range, using i-cluster size indexing |
| [in] | lastCell | The last cluster in the j-range, using i-cluster size indexing |
| [in] | excludeSubDiagonal | Exclude atom pairs with i-index > j-index |
| [in] | x_j | Coordinates for the j-atom, in SIMD packed format |
| [in] | rlist2 | The squared list cut-off |
| [in] | rbb2 | The squared cut-off for putting cluster-pairs in the list based on bounding box distance only |
| [in,out] | numDistanceChecks | The number of distance checks performed |
| ArrayRef< const bool > gmx::makeConstArrayRef | ( | const std::vector< BoolType > & | boolVector | ) |
| ArrayRef<const typename T::value_type> gmx::makeConstArrayRef | ( | const T & | c | ) |
| std::unique_ptr<Constraints> gmx::makeConstraints | ( | const gmx_mtop_t & | mtop, |
| const t_inputrec & | ir, | ||
| pull_t * | pull_work, | ||
| bool | havePullConstraintsWork, | ||
| bool | doEssentialDynamics, | ||
| Args &&... | args | ||
| ) |
Factory function for Constraints.
We only want an object to manage computing constraints when the simulation requires one. Checking for whether the object was made adds overhead to simulations that use constraints, while avoiding overhead on those that do not, so is a design trade-off we might reconsider some time.
Using a private constructor and a factory function ensures that we can only make a Constraints object when the prerequisites are satisfied, ie. that something needs them and if necessary has already been initialized.
Using the parameter pack insulates the factory function from changes to the type signature of the constructor that don't affect the logic here.
|
static |
Returns a string with the compiler defines required to avoid all flavour generation.
For example if flavour ElecType::RF with VdwType::FSwitch, the output will be such that the corresponding kernel flavour is generated: -DGMX_OCL_FASTGEN (will replace flavour generator nbnxn_ocl_kernels.clh with nbnxn_ocl_kernels_fastgen.clh) -DEL_RF (The ElecType::RF flavour) -DEELNAME=_ElecRF (The first part of the generated kernel name ) -DLJ_EWALD_COMB_GEOM (The VdwType::FSwitch flavour) -DVDWNAME=_VdwLJEwCombGeom (The second part of the generated kernel name )
prune/energy are still generated as originally. It is only the flavour-level that has changed, so that only the required flavour for the simulation is compiled.
If elecType is single-range Ewald, then we need to add the twin-cutoff flavour kernels to the JIT, because PME tuning might need it. This path sets -DGMX_OCL_FASTGEN_ADD_TWINCUT, which triggers the use of nbnxn_ocl_kernels_fastgen_add_twincut.clh. This hard-codes the generation of extra kernels that have the same base flavour, and add the required -DVDW_CUTOFF_CHECK and "TwinCut" to the kernel name.
If FastGen is not active, then nothing needs to be returned. The JIT defaults to compiling all kernel flavours.
| [in] | bFastGen | Whether FastGen should be used |
| [in] | elecType | Electrostatics kernel flavour for FastGen |
| [in] | vdwType | VDW kernel flavour for FastGen |
| std::bad_alloc | if out of memory |
| std::vector< int > gmx::makeGpuIds | ( | ArrayRef< const int > | compatibleGpus, |
| size_t | numGpuTasks | ||
| ) |
Make a vector containing numGpuTasks IDs of the IDs found in compatibleGpus.
| std::bad_alloc | If out of memory |
| std::string gmx::makeGpuIdString | ( | const std::vector< int > & | gpuIds, |
| int | totalNumberOfTasks | ||
| ) |
Convert a container of GPU deviced IDs to a string that can be used by gmx tune_pme as input to mdrun -gputasks.
Produce a valid input for mdrun -gputasks that refers to the device IDs in gpuIds but produces a mapping for totalNumberOfTasks tasks. Note that gmx tune_pme does not currently support filling mdrun -gputasks.
| [in] | gpuIds | Container of device IDs |
| [in] | totalNumberOfTasks | Total number of tasks for the output mapping produced by the returned string. |
| std::bad_alloc | If out of memory. |
|
static |
Makes the PP communicator and the PME communicator, when needed.
Returns the Cartesian rank setup and the rank duties. Sets cr->mpi_comm_mygroup For PP ranks, sets the DD PP cell index in ddCellIndex. With separate PME ranks in interleaved order, set the PME ranks in pmeRanks.
| std::pair< hid_t, H5mdGuard > gmx::makeH5mdAttributeGuard | ( | hid_t | object | ) |
Helper function for guarding an HDF5 attribute with H5Aclose.
| [in] | object | Object to guard. |
| std::pair< hid_t, H5mdGuard > gmx::makeH5mdDataSetGuard | ( | hid_t | object | ) |
Helper function for guarding an HDF5 data set with H5Dclose.
| [in] | object | Object to guard. |
| std::pair< hid_t, H5mdGuard > gmx::makeH5mdDataSpaceGuard | ( | hid_t | object | ) |
Helper function for guarding an HDF5 data space with H5Sclose.
| [in] | object | Object to guard. |
| std::pair< hid_t, H5mdGuard > gmx::makeH5mdGroupGuard | ( | hid_t | object | ) |
Helper function for guarding an HDF5 group with H5Gclose.
| [in] | object | Object to guard. |
| std::pair< hid_t, H5mdGuard > gmx::makeH5mdGuard | ( | hid_t | object, |
| H5mdCloseType | unboundCloser | ||
| ) |
Helper function for guarding an HDF5 object with a closing function (H5Gclose, etc.).
When the returned scope guard goes out of scope the closing function is called with the object identifier as its argument, ensuring that the resource is freed. If the identifier needs to be stored for later use it should not be guarded using these functions.
Intended use is for the object to be the result of an opening or creating function call, which is why it is returned along with the guard. E.g. to open a group:
auto [object, guard] = makeH5mdGuard(openOrCreateGroup(<...>), H5Gclose);
| [in] | object | Object to guard. |
| [in] | unboundCloser | Callback function used to close the guarded object |
| std::pair< hid_t, H5mdGuard > gmx::makeH5mdPropertyListGuard | ( | hid_t | object | ) |
Helper function for guarding an HDF5 property list with H5Pclose.
| [in] | object | Object to guard. |
| std::pair< hid_t, H5mdGuard > gmx::makeH5mdTypeGuard | ( | hid_t | object | ) |
Helper function for guarding an HDF5 type with H5Tclose.
| [in] | object | Object to guard. |
| std::unique_ptr< ImdSession > gmx::makeImdSession | ( | const t_inputrec * | ir, |
| const MpiComm & | mpiComm, | ||
| const gmx_domdec_t * | dd, | ||
| gmx_wallcycle * | wcycle, | ||
| gmx_enerdata_t * | enerd, | ||
| const gmx_multisim_t * | ms, | ||
| const gmx_mtop_t & | top_global, | ||
| const MDLogger & | mdlog, | ||
| gmx::ArrayRef< const gmx::RVec > | coords, | ||
| int | nfile, | ||
| const t_filenm | fnm[], | ||
| const gmx_output_env_t * | oenv, | ||
| const ImdOptions & | options, | ||
| StartingBehavior | startingBehavior | ||
| ) |
Makes and returns an initialized IMD session, which may be inactive.
This function is called before the main MD loop over time steps.
| ir | The inputrec structure containing the MD input parameters |
| mpiComm | Communication object for my group. |
| dd | Domain decomposition object, pass nullptr when DD is not active. |
| wcycle | Count wallcycles of IMD routines for diagnostic output. |
| enerd | Contains the GROMACS energies for the different interaction types. |
| ms | Handler for multi-simulations. |
| top_global | The topology of the whole system. |
| mdlog | Logger |
| coords | The starting positions of the atoms. |
| nfile | Number of files. |
| fnm | Struct containing file names etc. |
| oenv | Output options. |
| options | Options for interactive MD. |
| startingBehavior | Describes whether this is a restart appending to output files |
| std::vector< int > gmx::makeListOfAvailableDevices | ( | gmx::ArrayRef< const std::unique_ptr< DeviceInformation >> | deviceInfoList, |
| const std::string & | devicesSelectedByUserString | ||
| ) |
Implement GPU ID selection by returning the available GPU IDs on this physical node that are compatible.
If the string supplied by the user is empty, then return the IDs of all compatible GPUs on this physical node. Otherwise, check the user specified compatible GPUs and return their IDs.
| [in] | deviceInfoList | Information on the GPUs on this physical node. |
| [in] | devicesSelectedByUserString | String like "013" or "0,1,3" typically supplied by the user to mdrun -gpu_id. Must contain only unique decimal digits, or only decimal digits separated by comma delimiters. A terminal comma is accceptable (and required to specify a single ID that is larger than 9). |
| std::bad_alloc | If out of memory. InvalidInputError If an invalid character is found (ie not a digit or ',') or if identifiers are duplicated in the specifier list. InvalidInputError If devicesSelectedByUserString specifies IDs of the devices that are not compatible. |
| std::unique_ptr< MDAtoms > gmx::makeMDAtoms | ( | FILE * | fp, |
| const gmx_mtop_t & | mtop, | ||
| const t_inputrec & | ir, | ||
| const bool | rankHasPmeGpuTask | ||
| ) |
Builder function for MdAtomsWrapper.
Builder function.
|
inline |
Make an error string following an OpenCL API call.
It is meant to be called with status != CL_SUCCESS, but it will work correctly even if it is called with no OpenCL failure.
| [in] | message | Supplies context, e.g. the name of the API call that returned the error. |
| [in] | status | OpenCL API status code |
| T gmx::makePeriodic | ( | const T | x, |
| const T | period | ||
| ) |
Return x modulo period such that it is within the interval [-0.5*period, 0.5*period].
A shift of +/- 'period' is applied, if needed.
| [in] | x | Value to correct, should be within the interval [-1.5*period, 1.5*period] |
| [in] | period | The period |
x modulo period that is within the interval [-0.5*period, 0.5*period] | uint64_t gmx::makeRandomSeed | ( | ) |
Return 64 random bits from the random device, suitable as seed.
If the internal random device output is smaller than 64 bits, this routine will use multiple calls internally until we have 64 bits of random data.
|
static |
Get the next pure or pseudo-random number.
Returns the next random number taken from the hardware generator or from PRNG.
| [in] | gen | Pseudo-random/random numbers generator/device to use. |
| std::variant< std::vector< RangePartitioning >, std::string > gmx::makeUpdateGroupingsPerMoleculeType | ( | const gmx_mtop_t & | mtop | ) |
Returns a vector with update groups for each moleculetype in mtop or an error string when the criteria (see below) are not satisfied.
An error string is returned when at least one moleculetype does not obey the restrictions of update groups, e.g. more than two constraints in a row.
Currently valid update groups are:
To have update groups, all virtual sites should be linear 2 or 3 atom constructions with coefficients >= 0 and sum of coefficients <= 1.
This vector is generally consumed in constructing an UpdateGroups object.
| [in] | mtop | The system topology |
| UpdateGroups gmx::makeUpdateGroups | ( | const gmx::MDLogger & | mdlog, |
| std::vector< RangePartitioning > && | updateGroupingPerMoleculeType, | ||
| real | maxUpdateGroupRadius, | ||
| bool | doRerun, | ||
| bool | useDomainDecomposition, | ||
| bool | systemHasConstraintsOrVsites, | ||
| real | cutoffMargin | ||
| ) |
Builder for update groups.
Checks the conditions for using update groups, and logs a message if they cannot be used, along with the reason why not.
updateGroupingPerMoleculeType can not be empty (is asserted).
If PP domain decomposition is not in use, there is no reason to use update groups.
All molecule types in the system topology must be conform to the requirements, such that makeUpdateGroupingsPerMoleculeType() returns a non-empty vector.
mdrun -rerun does not support update groups (PBC corrections needed).
When we have constraints and/or vsites, it is beneficial to use update groups (when possible) to allow independent update of groups. But if there are no constraints or vsites, then there is no need to use update groups at all.
To use update groups, the large domain-to-domain cutoff distance should be compatible with the box size.
| std::unique_ptr< VirtualSitesHandler > gmx::makeVirtualSitesHandler | ( | const gmx_mtop_t & | mtop, |
| gmx_domdec_t * | domdec, | ||
| PbcType | pbcType, | ||
| ArrayRef< const RangePartitioning > | updateGroupingPerMoleculeType | ||
| ) |
Create the virtual site handler.
| [in] | mtop | The global topology |
| [in] | domdec | The domain decomposition struct, pass nullptr when DD is not in use |
| [in] | pbcType | The type of PBC |
| [in] | updateGroupingPerMoleculeType | Update grouping per molecule type, pass empty when not using update groups |
|
static |
Manage any development feature flag variables encountered.
The use of dev features indicated by environment variables is logged in order to ensure that runs with such features enabled can be identified from their log and standard output. Any cross dependencies are also checked, and if unsatisfied, a fatal error issued.
Note that some development features overrides are applied already here: the GPU communication flags are set to false in non-tMPI and non-CUDA builds.
| [in] | mdlog | Logger object. |
| [in] | pmeRunMode | Run mode indicating what resource is PME executed on. |
| [in] | numRanksPerSimulation | The number of ranks in each simulation. |
| [in] | numPmeRanksPerSimulation | The number of PME ranks in each simulation, can be -1 |
| [in] | canUseGpuAwareMpi | Whether GPU-aware MPI can be used. |
| void gmx::mapGridToDataGrid | ( | std::vector< int > * | gridpointToDatapoint, |
| const MultiDimArray< std::vector< double >, dynamicExtents2D > & | data, | ||
| int | numDataPoints, | ||
| const std::string & | dataFilename, | ||
| const BiasGrid & | grid, | ||
| const std::string & | correctFormatMessage | ||
| ) |
Maps each point in the grid to a point in the data grid.
This functions maps an AWH bias grid to a user provided input data grid. The value of data grid point i along dimension d is given by data[d][i]. The number of dimensions of the data should equal that of the grid. A fatal error is thrown if extracting the data fails or the data does not cover the whole grid.
| [out] | gridpointToDatapoint | Array mapping each grid point to a data point index. |
| [in] | data | 2D array in format ndim x ndatapoints with data grid point values. |
| [in] | numDataPoints | Number of data points. |
| [in] | dataFilename | The data filename. |
| [in] | grid | The grid. |
| [in] | correctFormatMessage | String to include in error message if extracting the data fails. |
| IndexMap gmx::mapSelectionToInternalIndices | ( | const ArrayRef< const int32_t > & | selectedIndices | ) |
Map the selected atoms to local internal indices.
| [in] | selectedIndices | An array of selected atom indices. |
|
inlinestatic |
Add two float variables, masked version.
| a | term1 |
| b | term2 |
| m | mask |
|
inlinestatic |
Add two double variables, masked version.
| a | term1 |
| b | term2 |
| m | mask |
|
inlinestatic |
Float fused multiply-add, masked version.
| a | factor1 |
| b | factor2 |
| c | term |
| m | mask |
|
inlinestatic |
double fused multiply-add, masked version.
| a | factor1 |
| b | factor2 |
| c | term |
| m | mask |
|
inlinestatic |
Calculate 1/x for masked entry of float.
This routine only evaluates 1/x if mask is true. Illegal values for a masked-out float will not lead to floating-point exceptions.
| x | Argument that must be nonzero if masked-in. |
| m | Mask |
|
inlinestatic |
Calculate 1/x for masked entry of double.
This routine only evaluates 1/x if mask is true. Illegal values for a masked-out double will not lead to floating-point exceptions.
| x | Argument that must be nonzero if masked-in. |
| m | Mask |
|
inlinestatic |
Calculate 1/x for masked entry of double, but with single accuracy.
This routine only evaluates 1/x if mask is true. Illegal values for a masked-out double will not lead to floating-point exceptions.
| x | Argument that must be nonzero if masked-in. |
| m | Mask |
|
inlinestatic |
Calculate 1/sqrt(x) for masked entry of float.
This routine only evaluates 1/sqrt(x) if mask is true. Illegal values for a masked-out float will not lead to floating-point exceptions.
| x | Argument that must be >0 if masked-in. |
| m | Mask |
|
inlinestatic |
Calculate 1/sqrt(x) for masked entry of double.
This routine only evaluates 1/sqrt(x) if mask is true. Illegal values for a masked-out double will not lead to floating-point exceptions.
| x | Argument that must be >0 if masked-in. |
| m | Mask |
|
inlinestatic |
Calculate 1/sqrt(x) for masked entry of double, but with single accuracy.
This routine only evaluates 1/sqrt(x) if mask is true. Illegal values for a masked-out double will not lead to floating-point exceptions.
| x | Argument that must be >0 if masked-in. |
| m | Mask |
|
inlinestatic |
Multiply two float variables, masked version.
| a | factor1 |
| b | factor2 |
| m | mask |
|
inlinestatic |
Multiply two double variables, masked version.
| a | factor1 |
| b | factor2 |
| m | mask |
|
inlinestatic |
Float 1.0/x, masked version.
| x | Argument, x>0 for entries where mask is true. |
| m | Mask |
|
inlinestatic |
Double 1.0/x, masked version.
| x | Argument, x>0 for entries where mask is true. |
| m | Mask |
|
inlinestatic |
Set each float element to the largest from two variables.
|
inlinestatic |
Set each double element to the largest from two variables.
| void gmx::mdAlgorithmsSetupAtomData | ( | const gmx_domdec_t * | dd, |
| const t_inputrec & | inputrec, | ||
| const gmx_mtop_t & | top_global, | ||
| gmx_localtop_t * | top, | ||
| t_forcerec * | fr, | ||
| ForceBuffers * | force, | ||
| MDAtoms * | mdAtoms, | ||
| Constraints * | constr, | ||
| VirtualSitesHandler * | vsite, | ||
| gmx_shellfc_t * | shellfc | ||
| ) |
Sets atom data for several MD algorithms.
Most MD algorithms require two different setup calls: one for initialization and parameter setting and one for atom data setup. This routine sets the atom data for the (locally available) atoms. This is called at the start of serial runs and during domain decomposition.
| [in] | dd | Domain decomposition struct, can be nullptr |
| [in] | inputrec | Input parameter record |
| [in] | top_global | The global topology |
| [in,out] | top | The local topology |
| [in,out] | fr | The force calculation parameter/data record |
| [out] | force | The force buffer |
| [out] | mdAtoms | The MD atom data |
| [in,out] | constr | The constraints handler, can be NULL |
| [in,out] | vsite | The virtual site data, can be NULL |
| [in,out] | shellfc | The shell/flexible-constraint data, can be NULL |
|
static |
The callback used for running on spawned threads.
Obtains the pointer to the main mdrunner object from the one argument permitted to the thread-launch API call, copies it to make a new runner for this thread, reinitializes necessary data, and proceeds to the simulation.
| void gmx::mergeExclusions | ( | ListOfLists< int > * | excl, |
| gmx::ArrayRef< ExclusionBlock > | b2 | ||
| ) |
Merge the contents of b2 into excl.
Requires that b2 and excl describe the same number of particles, if b2 describes a non-zero number.
|
inlinestatic |
Set each float element to the smallest from two variables.
|
inlinestatic |
Set each double element to the smallest from two variables.
| void gmx::modifyEmbeddedFourCenterInteractions | ( | gmx_mtop_t * | mtop, |
| const std::set< int > & | embeddedIndices, | ||
| const std::vector< bool > & | isEmbeddedBlock, | ||
| const MDLogger & | logger | ||
| ) |
Modifies four-centers interactions.
Removes any other four-centers bonded interactions including 3 or more embedded atoms Any restraints and constraints will be kept
| [in,out] | mtop | topology to be modified |
| [in] | embeddedIndices | set with global indices of embedded atoms |
| [in] | isEmbeddedBlock | vector with flags for embedded atom-containing blocks |
| [in] | logger | MDLogger for logging info about modifications |
| void gmx::modifyEmbeddedThreeCenterInteractions | ( | gmx_mtop_t * | mtop, |
| const std::set< int > & | embeddedIndices, | ||
| const std::vector< bool > & | isEmbeddedBlock, | ||
| const MDLogger & | logger | ||
| ) |
Modifies three-centers interactions (i.e. Angles, Settles)
Removes any other three-centers bonded interactions including 2 or more embedded atoms Any restraints and constraints will be kept Any F_SETTLE containing embedded atoms will be converted to the pair of F_CONNBONDS
| [in,out] | mtop | topology to be modified |
| [in] | embeddedIndices | set with global indices of embedded atoms |
| [in] | isEmbeddedBlock | vector with flags for embedded atom-containing blocks |
| [in] | logger | MDLogger for logging info about modifications |
| void gmx::modifyEmbeddedTwoCenterInteractions | ( | gmx_mtop_t * | mtop, |
| const std::set< int > & | embeddedIndices, | ||
| const std::vector< bool > & | isEmbeddedBlock, | ||
| const MDLogger & | logger | ||
| ) |
Modifies pairwise bonded interactions.
Removes any other pairwise bonded interactions between embedded atoms Creates F_CONNBOND between embedded atoms Any restraints and constraints will be kept
| [in,out] | mtop | topology to be modified |
| [in] | embeddedIndices | set with global indices of embedded atoms |
| [in] | isEmbeddedBlock | vector with flags for embedded atom-containing blocks |
| [in] | logger | MDLogger for logging info about modifications |
| void gmx::MPI_Comm_free_wrapper | ( | MPI_Comm * | comm | ) |
Wrapper function for RAII-style cleanup.
This is needed to discard the return value so it can be used as a deleter by a smart pointer.
| bool gmx::mrcHeaderIsSane | ( | const MrcDensityMapHeader & | header | ) |
Checks if the values in the header are sane.
Checks extents and numbers of columns, rows and sections, as well as unit cell angles for positivity and to be within bounds.
Bounds are set generously not to hamper future creative uses of mrc files.
| int gmx::multiDimArrayIndexToLinear | ( | const awh_ivec | indexMulti, |
| int | numDim, | ||
| const awh_ivec | numPointsDim | ||
| ) |
Convert multidimensional array index to a linear one.
| [in] | indexMulti | Multidimensional index to convert to a linear one. |
| [in] | numDim | Number of dimensions of the array. |
| [in] | numPointsDim | Number of points of the array. |
| int gmx::multiDimGridIndexToLinear | ( | const BiasGrid & | grid, |
| const awh_ivec | indexMulti | ||
| ) |
Convert a multidimensional grid point index to a linear one.
| [in] | grid | The grid. |
| [in] | indexMulti | Multidimensional grid point index to convert to a linear one. |
| std::string gmx::multiGpuFftDescription | ( | ) |
Construct a string that describes the library (if any) that provides multi-GPU FFT support to this build.
Returns information for describing the multi-GPU FFT support.
|
static |
Main kernel for NBNXM.
| auto gmx::nbnxmKernelPruneOnly | ( | sycl::handler & | cgh, |
| const int | numSci, | ||
| const int | numParts, | ||
| const Float4 *__restrict__ | gm_xq, | ||
| const Float3 *__restrict__ | gm_shiftVec, | ||
| nbnxn_cj_packed_t *__restrict__ | gm_plistCJPacked, | ||
| const nbnxn_sci_t *__restrict__ | gm_plistSci, | ||
| unsigned int *__restrict__ | gm_plistIMask, | ||
| int *__restrict__ | gm_rollingPruningPart, | ||
| int *__restrict__ | gm_sciHistogram, | ||
| int *__restrict__ | gm_sciCount, | ||
| const float | rlistOuterSq, | ||
| const float | rlistInnerSq | ||
| ) |
Prune-only kernel for NBNXM.
| void gmx::nbnxmKernelSimd | ( | const NbnxnPairlistCpu & | pairlist, |
| const nbnxn_atomdata_t & | nbat, | ||
| const interaction_const_t & | ic, | ||
| const rvec * | shift_vec, | ||
| nbnxn_atomdata_output_t * | out | ||
| ) |
The actual NBNxM SIMD kernel.
| kernelLayout | The kernel layout: either 2xMM or 4xM |
| coulombType | The type of Coulomb interaction |
| vdwCutoffCheck | Whether a separate check for the VdW cutoff is needed |
| ljCombinationRule | The combination rule for the LJ parameters |
| vdwModifier | The modifier for the LJ interactions |
| ljEwald | The type of LJ Ewald treatment, can be none |
| energyOutput | Which types of output are requested |
| [in] | pairlist | The cluster pair list |
| [in] | nbat | Input data for atoms, including charges and LJ parameters |
| [in] | ic | The interaction constants |
| [in] | shift_vec | A list of PBC shift vectors |
| [in,out] | out | Struct for accumulating forces, energies and virial |
|
static |
SYCL kernel for transforming position coordinates from rvec to nbnxm layout.
| [out] | gm_xq | Coordinates buffer in nbnxm layout. |
| [in] | gm_x | Coordinates buffer. |
| [in] | gm_atomIndex | Atom index mapping. |
| [in] | gm_numAtoms | Array of number of atoms. |
| [in] | gm_cellIndex | Array of cell indices. |
| [in] | cellOffset | First cell. |
| [in] | numAtomsPerCell | Number of atoms per cell. |
| [in] | columnsOffset | Index if the first column in the cell. |
Returns the increase in pairlist radius when including volume of pairs beyond rlist.
Due to the cluster size the total volume of the pairlist is (much) more than 4/3*pi*rlist^3. This function returns the increase in radius required to match the volume of the pairlist including the atoms pairs that are beyond rlist.
| void gmx::nbnxmRefPruneKernel | ( | NbnxnPairlistCpu * | nbl, |
| const nbnxn_atomdata_t * | nbat, | ||
| ArrayRef< const RVec > | shiftvec, | ||
| real | rlistInner | ||
| ) |
Prune a single NbnxnPairlistCpu entry with distance rlistInner.
Reads a cluster pairlist nbl->ciOuter, nbl->cjOuter and writes all cluster pairs within rlistInner to nbl->ci, nbl->cj.
|
static |
Returns whether CPU SIMD support exists for the given inputrec.
If the return value is false, issue a warning to mdlog
| void gmx::nbnxn_atomdata_copy_x_to_nbat_x | ( | const GridSet & | gridSet, |
| AtomLocality | locality, | ||
| const rvec * | coordinates, | ||
| nbnxn_atomdata_t * | nbat | ||
| ) |
Transform coordinates to xbat layout.
Creates a copy of the coordinates buffer using short-range ordering.
| [in] | gridSet | The grids data. |
| [in] | locality | If the transformation should be applied to local or non local coordinates. |
| [in] | coordinates | Coordinates in plain rvec format. |
| [in,out] | nbat | Data in NBNXM format, used for mapping formats and to locate the output buffer. |
| void gmx::nbnxn_atomdata_x_to_nbat_x_gpu | ( | const GridSet & | gridSet, |
| AtomLocality | locality, | ||
| NbnxmGpu * | gpu_nbv, | ||
| DeviceBuffer< RVec > | d_x, | ||
| GpuEventSynchronizer * | xReadyOnDevice | ||
| ) |
Transform coordinates to xbat layout on GPU.
Creates a GPU copy of the coordinates buffer using short-range ordering. As input, uses coordinates in plain rvec format in GPU memory.
| [in] | gridSet | The grids data. |
| [in] | locality | If the transformation should be applied to local or non local coordinates. |
| [in,out] | gpu_nbv | The NBNXM GPU data structure. |
| [in] | d_x | Coordinates to be copied (in plain rvec format). |
| [in] | xReadyOnDevice | Event synchronizer indicating that the coordinates are ready in the device memory. If there is no need to wait for any event (e.g., the wait has already been enqueued into the appropriate stream), it can be nullptr. |
| real gmx::nbnxn_get_rlist_effective_inc | ( | int | clusterSize, |
| const RVec & | averageClusterBoundingBox | ||
| ) |
Returns the effective list radius of the pair-list.
Due to the cluster size the effective pair-list is longer than that of a simple atom pair-list. This function gives the extra distance.
| void gmx::nbnxn_gpu_compile_kernels | ( | NbnxmGpu * | nb | ) |
Compiles nbnxn kernels for OpenCL GPU given by mygpu.
With OpenCL, a call to this function must not precede nbnxn_gpu_init() (which also calls it).
Doing bFastGen means only the requested kernels are compiled, significantly reducing the total compilation time. If false, all OpenCL kernels are compiled.
A fatal error results if compilation fails.
| [in,out] | nb | Manages OpenCL non-bonded calculations; compiled kernels returned in deviceInfo members |
Does not throw
| void gmx::nbnxn_gpu_x_to_nbat_x | ( | const Grid gmx_unused & | grid, |
| NbnxmGpu gmx_unused * | gpu_nbv, | ||
| DeviceBuffer< RVec > gmx_unused | d_x, | ||
| GpuEventSynchronizer gmx_unused * | xReadyOnDevice, | ||
| AtomLocality gmx_unused | locality, | ||
| int gmx_unused | gridId, | ||
| int gmx_unused | numColumnsMax, | ||
| bool gmx_unused | mustInsertNonLocalDependency | ||
| ) |
X buffer operations on GPU: performs conversion from rvec to nb format.
| [in] | grid | Grid to be converted. |
| [in,out] | gpu_nbv | The nonbonded data GPU structure. |
| [in] | d_x | Device-side coordinates in plain rvec format. |
| [in] | xReadyOnDevice | Event synchronizer indicating that the coordinates are ready in the device memory. |
| [in] | locality | Copy coordinates for local or non-local atoms. |
| [in] | gridId | Index of the grid being converted. |
| [in] | numColumnsMax | Maximum number of columns in the grid. |
| [in] | mustInsertNonLocalDependency | Whether synchronization between local and non-local streams should be added. Typically, true if and only if that is the last grid in gridset. |
|
static |
Dispatches the non-bonded N versus M atom cluster CPU kernels.
OpenMP parallelization is performed within this function. Energy reduction, but not force and shift force reduction, is performed within this function.
| [in] | pairlistSet | Pairlists with local or non-local interactions to compute |
| [in] | kernelSetup | The non-bonded kernel setup |
| [in,out] | nbat | The atomdata for the interactions |
| [in] | ic | Non-bonded interaction constants |
| [in] | shiftVectors | The PBC shift vectors |
| [in] | stepWork | Flags that tell what to compute |
| [in] | clearF | Enum that tells if to clear the force output buffer |
| [out] | vCoulomb | Output buffer for Coulomb energies |
| [out] | vVdw | Output buffer for Van der Waals energies |
| [in] | wcycle | Pointer to cycle counting data structure. |
| void gmx::nbnxn_put_on_grid_nonlocal | ( | nonbonded_verlet_t * | nb_verlet, |
| const gmx::DomdecZones & | zones, | ||
| ArrayRef< const int32_t > | atomInfo, | ||
| ArrayRef< const RVec > | x | ||
| ) |
As nbnxn_put_on_grid, but for the non-local atoms.
with domain decomposition. Should be called after calling nbnxn_search_put_on_grid for the local atoms / home zone.
| void gmx::nbnxnInsertNonlocalGpuDependency | ( | NbnxmGpu gmx_unused * | nb, |
| InteractionLocality gmx_unused | interactionLocality | ||
| ) |
Sync the nonlocal stream with dependent tasks in the local queue.
As the point where the local stream tasks can be considered complete happens at the same call point where the nonlocal stream should be synced with the the local, this function records the event if called with the local stream as argument and inserts in the GPU stream a wait on the event on the nonlocal.
| [in] | nb | The nonbonded data GPU structure |
| [in] | interactionLocality | Local or NonLocal sync point |
|
static |
SYCL bucket sci sort kernel.
Sorts sci in order from most to least neighbours, using the count sort algorithm
Unlike the cpu version of sci sort, this kernel uses counts which only contain pairs which have not been masked out, giving an ordering which more accurately represents the work which will be done in the non bonded force kernel. The counts themselves are generated in the prune kernel.
| gm_sci | Unsorted pair list. |
| gm_sciCount | Total number of sci with exactly i neighbours |
| gm_sciOffset | Exclusive prefix sum of gm_sciCount. gm_sciOffset[i] is the offset that the first sci with i neighbours will have in the sorted sci list. All other sci with i neighbours will be placed randomly in positions gm_sciOffset[i] to gm_sciOffset[i+1] exclusive. |
| gm_sciSorted | Sorted pair list. |
|
static |
SYCL exclusive prefix sum kernel for list sorting.
As of oneAPI 2024.1, oneapi::dpl::experimental::exclusive_scan_async for inputs <= 16384 elements simply launches a single work-group and uses sycl::joint_exclusive_scan. We have, somewhat arbitrary, input size of 8192, so we're fine replicating the same approach.
NVIDIA's CUB uses fancier approach ("Single-pass Parallel Prefix Scan with Decoupled Look-back"), but we are unlikely to need it here since this kernel is very small anyway.
| workGroupSize | Size of the (only) work-group. |
| nElements | Input array size; should be a multiple of workGroupSize. |
| gm_input | Input data buffer, should contain nElements elements of type int. |
| gm_output | Output data buffer, should have enough space for nElements elements of type int. |
|
inline |
If StatePropagatorDataGpu object is needed.
| [in] | simulationWorkload | Simulation workload flags. |
| OptimisationResult gmx::nelderMead | ( | const std::function< real(ArrayRef< const real >)> & | functionToMinimize, |
| ArrayRef< const real > | initialGuess, | ||
| real | minimumRelativeSimplexLength = 1e-8, |
||
| int | maxSteps = 10'000 |
||
| ) |
Derivative-free downhill simplex optimisation.
Find a local minimum of an N-dimensional mapping  using the downhill simplex algorithm by Nelder and Mead as described in
using the downhill simplex algorithm by Nelder and Mead as described in
Saša Singer and John Nelder (2009), Scholarpedia, 4(7):2928. doi:10.4249/scholarpedia.2928
Stops when the oriented simplex length is less than a constant factor times the initial lengths or when a maximum step size is reached.
For best performance pre-condition problem magnitudes to 1.
The following algorithm is implemented in this function 1 Define the N+1 vertices of the initial simplex The inital simplex is constructed from the initial guess and N additional vertices by adding 0.05 to the initial guess (or 0.0025 if the initial guess is the null vector) from the initial vertex (in line with usual implementations).
1a Sort vertices according to function value with the lowest function value first in order to minimize the function.
2 Calculate the centroid of the simplex as arithmetic mean of all vertices except the worst,  .
.
3 Reflect the worst simplex vertex (the one with the highest function value) at the centroid to obtain a reflection point  which lies outside the vertex.
which lies outside the vertex.
3a Replace worst point with reflection point if reflection point function value is better than second worst point, but not better than best and go to 1a.
4 If the reflection point is better than all other points so far, attempt an expansion by calculating the expansion point at 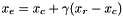 . Swap out the worst point in the vertex with the expansion point if better than reflection point, otherwise use the reflection point and go to 1a.
. Swap out the worst point in the vertex with the expansion point if better than reflection point, otherwise use the reflection point and go to 1a.
5 Attempt contraction, because reflection was not successful; 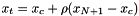 . If the contraction point is better than the worst point, swap out worst point with contracted point and go to 1a.
. If the contraction point is better than the worst point, swap out worst point with contracted point and go to 1a.
6 Shrink the vertex. Replace all points except the best one with 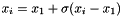 and go to 1a.
and go to 1a.
| [in] | functionToMinimize | function to be minimized |
| [in] | initialGuess | of coordinates |
| [in] | minimumRelativeSimplexLength | minimal oriented simplex length with respect to initial simplex |
| [in] | maxSteps | to run algorithm for |
| void gmx::niceHeader | ( | TextWriter * | writer, |
| const char * | fn, | ||
| char | commentChar | ||
| ) |
Prints creation time stamp and user information into a string as comments, and returns it.
| [out] | writer | Where to print the information. |
| [in] | fn | Name of the file being written; if nullptr, described as "unknown". |
| [in] | commentChar | Character to use as the starting delimiter for comments. |
| std::bad_alloc | if out of memory. |
| int gmx::nonbondedMtsFactor | ( | const t_inputrec & | ir | ) |
Returns the interval in steps at which the non-bonded pair forces are calculated.
Note: returns 1 when multiple time-stepping is not activated.
| std::remove_const_t<T> gmx::norm | ( | T * | v | ) |
Forward operations on C Array style vectors to C implementations.
Since vec.h and vectypes.h independently declare norm and norm2 in different namespaces, code that includes both headers but does not specify the namespace from which to use norm and norm2 cannot properly resolve overloads without the following helper templates.
| T | array element type (e.g. real, int, etc.) |
| v | address of first vector element |
|
static |
Normalizes block data for output.
| [in,out] | block | The block to normalize. |
| [in] | bias | The AWH bias. |
|
static |
Normalizes the free energy and PMF sum.
| [in] | pointState | The state of the points. |
| void gmx::normalizeSumPositiveValuesToUnity | ( | ArrayRef< float > | data | ) |
Divide all values of a view by a constant so that the sum of all its positive values is one.
| [in,out] | data | the input data to be normalized |
| size_t gmx::numberOfExpectedDataItems | ( | const MrcDensityMapHeader & | header | ) |
Return the number of density data items that are expected to follow this header.
| InternalError | if the number of data items cannot be determined |
|
inlinenoexcept |
Return whether object name exists in the given HDF5 container.
| [in] | container | Handle to container in which to check. |
| [in] | name | Name of object to look for. |
| hid_t gmx::openGroup | ( | const hid_t | container, |
| const char * | name | ||
| ) |
Open an existing HDF5 group.
| [in] | container | The ID of the container where the group is located, or should be created. |
| [in] | name | The name of the group. |
| FileIOError | If the group cannot be found. |
| FilePtr gmx::openLibraryFile | ( | const std::filesystem::path & | filename, |
| bool | bAddCWD = true, |
||
| bool | bFatal = true |
||
| ) |
Opens a library file for reading in an RAII-style FILE handle.
Works as findLibraryFile(), except that it opens the file and returns a file handle.
| LogFilePtr gmx::openLogFile | ( | const char * | lognm, |
| bool | appendFiles | ||
| ) |
Open the log file for writing/appending.
| FileIOError | when the log file cannot be opened. |
| hid_t gmx::openOrCreateGroup | ( | const hid_t | container, |
| const char * | name | ||
| ) |
Open an existing HDF5 group or create it if it did not exist already.
NOTE: This function is deprecated and should not be used in new code.
| [in] | container | The ID of the container where the group is located, or should be created. |
| [in] | name | The name of the group. |
| FileIOError | If the group cannot be found or created. |
|
static |
Method to open TNG file.
Only need extra method to open this kind of file as it may need access to a Selection sel, if it is valid. Otherwise atom indices will be taken from the topology mtop.
| [in] | name | Name of the output file. |
| [in] | sel | Reference to selection. |
| [in] | mtop | Pointer to topology, tested before that it is valid. |
| bool gmx::operator!= | ( | const DensityFittingParameters & | lhs, |
| const DensityFittingParameters & | rhs | ||
| ) |
Check if two structs holding density fitting parameters are not equal.
| [in] | lhs | left hand side to be compared |
| [in] | rhs | right hand side to be compared |
|
noexcept |
Check for non-equality.
| bool gmx::operator== | ( | const DensityFittingParameters & | lhs, |
| const DensityFittingParameters & | rhs | ||
| ) |
Check if two structs holding density fitting parameters are equal.
| [in] | lhs | left hand side to be compared |
| [in] | rhs | right hand side to be compared |
|
noexcept |
Comparison operator.
| bool gmx::operator== | ( | const Allocator< T1, Policy1 > & | a, |
| const Allocator< T2, Policy2 > & | b | ||
| ) |
Return true if two allocators are identical.
True if they have identical policies that are defined to be always equal (which is generally true for a stateless policy). An allocation policy with state should typically define is_always_equal to std::false_type and provide a correct equality operator.
| std::vector<char> gmx::packBufferViaIterator | ( | Iterator | begin, |
| Iterator | end, | ||
| std::vector< char > && | packingBuffer, | ||
| const size_t | maxStrLength, | ||
| Callback | cStringFromIterator | ||
| ) |
Pack a string buffer from a range of iterators and a callback function.
Caller that knows about their problem domain can pass in a buffer whose capacity meets that needed. Otherwise we fall back on the standard vector approach of resizing logarithmically
Registering a callback function avoids the H5md interface adding overloads and explicit specializations for multiple string types and multiple collection types
| Iterator | The type of the iterator to write. |
| Callback | The type of the callback function to convert iterator to C-string. |
| [in] | begin | The beginning iterator of the data to write. |
| [in] | end | The ending iterator of the data to write. |
| [in] | packingBuffer | The buffer to write the strings into. |
| [in] | maxStrLength | The maximum length of the strings in the attribute. |
| [in] | cStringFromIterator | The callback function to convert iterator to C-string. |
| std::size_t gmx::pageSize | ( | ) |
Return the memory page size on this system.
Implements the "construct on first use" idiom to avoid the static initialization order fiasco where a possible static page-aligned container would be initialized before the alignment variable was.
Note that thread-safety is guaranteed by the C++11 language standard.
|
inlinestatic |
Convert a string into an array of values.
| ValueType | array element type to convert into |
| NumExpectedValues | number of values of the array |
| InvalidInputError | if splitting the string at whitespaces does not result in NumExpectedValues or zero substrings |
| InvalidInputError | if conversion of any of the NumExpectedValues substrings of the splitted input string fails |
Converts a string into an array of type ValueType with exactly NumExpectedValues.
No result is returned if the string is empty or contains only whitespace .
|
static |
Parse a GPU ID specifier string into a container.
| [in] | gpuIdString | String like "013" or "0,1,3" typically supplied by the user. Must contain only unique decimal digits, or only decimal digits separated by comma delimiters. A terminal comma is accceptable (and required to specify a single ID that is larger than 9). |
gpuIdString.| std::bad_alloc | If out of memory. InvalidInputError If an invalid character is found (ie not a digit or ','). |
| std::vector< int > gmx::parseUserGpuIdString | ( | const std::string & | gpuIdString | ) |
Parse a GPU ID specifier string into a container describing device IDs exposed to the run.
| [in] | gpuIdString | String like "013" or "0,1,3" typically supplied by the user to mdrun -gpu_id. Must contain only unique decimal digits, or only decimal digits separated by comma delimiters. A terminal comma is accceptable (and required to specify a single ID that is larger than 9). |
| std::bad_alloc | If out of memory. InvalidInputError If an invalid character is found (ie not a digit or ',') or if identifiers are duplicated in the specifier list. |
| std::vector< int > gmx::parseUserTaskAssignmentString | ( | const std::string & | gpuIdString | ) |
Parse a GPU ID specifier string into a container describing device ID to task mapping.
| [in] | gpuIdString | String like "0011" or "0,0,1,1" typically supplied by the user to mdrun -gputasks. Must contain only decimal digits, or only decimal digits separated by comma delimiters. A terminal comma is accceptable (and required to specify a single ID that is larger than 9). |
| std::bad_alloc | If out of memory. InvalidInputError If an invalid character is found (ie not a digit or ','). |
|
static |
Returns the most suitable CPU SIMD kernel exclusion type.
Environment variables GMX_NBNXN_EWALD_TABLE and GMX_NBNXN_EWALD_ANALYTICAL override all heuristics below.
Since table lookup's don't parallelize with SIMD, analytical will probably always be faster for a SIMD width of 8 or more. With FMA analytical is sometimes faster for a width if 4 as well. In single precision, this is faster on Bulldozer. On AMD Zen1, tabulated Ewald kernels are faster on all 4 combinations of single or double precision and 128 or 256-bit AVX2.
|
static |
Returns the most suitable CPU SIMD kernel type.
Environment variables GMX_NBNXN_SIMD_4XN and GMX_NBNXN_SIMD_2XNN take priority. Then, as long as both 2x(N+N) and 4xN kernels are built, we choose between them. This is based on the SIMD acceleration choice and CPU information detected at runtime.
4xN calculates more (zero) interactions, but has less pair-search work and much better kernel instruction scheduling.
Up till now we have only seen that on Intel Sandy/Ivy Bridge, which doesn't have FMA, both the analytical and tabulated Ewald kernels have similar pair rates for 4x8 and 2x(4+4), so we choose 2x(4+4) because it results in significantly fewer pairs. For RF, the raw pair rate of the 4x8 kernel is higher than 2x(4+4), 10% with HT, 50% without HT. As we currently don't detect the actual use of HT, use 4x8 to avoid a potential performance hit. On Intel Haswell 4x8 is always faster.
| void gmx::placeCoordinatesWithCOMInBox | ( | const PbcType & | pbcType, |
| UnitCellType | unitCellType, | ||
| CenteringType | centerType, | ||
| const matrix | box, | ||
| ArrayRef< RVec > | x, | ||
| const gmx_mtop_t & | mtop, | ||
| COMShiftType | comShiftType | ||
| ) |
Moves collection of atoms along the center of mass into a box.
This ensures that the centre of mass (COM) of a molecule is placed within a predefined coordinate space (usually a simulation box).
| [in] | pbcType | What kind of PBC are we handling today. |
| [in] | unitCellType | Kind of unitcell used for the box. |
| [in] | centerType | How atoms should be centered. |
| [in] | box | The currently available box to place things into. |
| [in,out] | x | View in coordinates to shift. |
| [in] | mtop | Topology with residue and molecule information. |
| [in] | comShiftType | Whether residues or molecules are shifted. |
|
inlinestatic |
Calculate the force correction due to PME analytically in float.
See the SIMD version of this function for details.
| z2 | input parameter |
|
inlinestatic |
Calculate the force correction due to PME analytically in double.
See the SIMD version of this function for details.
| z2 | input parameter |
|
inlinestatic |
Force correction due to PME in double, but with single accuracy.
See the SIMD version of this function for details.
| z2 | input parameter |
|
static |
Blocks until PME GPU tasks are completed, and gets the output forces and virial/energy (if they were to be computed).
| [in] | pme | The PME data structure. |
| [in] | stepWork | The required work for this simulation step |
| [in] | wcycle | The wallclock counter. |
| [out] | forceWithVirial | The output force and virial |
| [out] | enerd | The output energies |
| [in] | lambdaQ | The Coulomb lambda to use when calculating the results. |
|
inlinestatic |
Calculate the potential correction due to PME analytically in float.
See the SIMD version of this function for details.
| z2 | input parameter |
|
inlinestatic |
Calculate the potential correction due to PME analytically in double.
See the SIMD version of this function for details.
| z2 | input parameter |
|
inlinestatic |
Potential correction due to PME in double, but with single accuracy.
See the SIMD version of this function for details.
| z2 | input parameter |
|
static |
Returns the point distance between from value x to value x0 along the given axis.
Note that the returned distance may be negative or larger than the number of points in the axis. For a periodic axis, the distance is chosen to be in [0, period), i.e. always positive but not the shortest one.
| [in] | axis | BiasGrid axis. |
| [in] | x | From value. |
| [in] | x0 | To value. |
| bool gmx::pointsAlongLambdaAxis | ( | const BiasGrid & | grid, |
| int | pointIndex1, | ||
| int | pointIndex2 | ||
| ) |
Checks whether two points are along a free energy lambda state axis.
| [in] | grid | The grid. |
| [in] | pointIndex1 | Grid point index of the first point. |
| [in] | pointIndex2 | Grid point index of the second point. |
| bool gmx::pointsHaveDifferentLambda | ( | const BiasGrid & | grid, |
| int | pointIndex1, | ||
| int | pointIndex2 | ||
| ) |
Checks whether two points are different in the free energy lambda state dimension (if any).
| [in] | grid | The grid. |
| [in] | pointIndex1 | Grid point index of the first point. |
| [in] | pointIndex2 | Grid point index of the second point. |
| T gmx::power12 | ( | T | x | ) |
calculate x^12
| T | Type of argument and return value |
| x | argument |
| T gmx::power3 | ( | T | x | ) |
calculate x^3
| T | Type of argument and return value |
| x | argument |
| T gmx::power4 | ( | T | x | ) |
calculate x^4
| T | Type of argument and return value |
| x | argument |
| T gmx::power5 | ( | T | x | ) |
calculate x^5
| T | Type of argument and return value |
| x | argument |
| T gmx::power6 | ( | T | x | ) |
calculate x^6
| T | Type of argument and return value |
| x | argument |
| std::unique_ptr< Awh > gmx::prepareAwhModule | ( | FILE * | fplog, |
| const t_inputrec & | inputRecord, | ||
| t_state * | stateGlobal, | ||
| const MpiComm & | mpiComm, | ||
| const gmx_multisim_t * | multiSimRecord, | ||
| bool | startingFromCheckpoint, | ||
| bool | usingShellParticles, | ||
| const std::string & | biasInitFilename, | ||
| pull_t * | pull_work | ||
| ) |
Makes an Awh and prepares to use it if the user input requests that.
Restores state from history in checkpoint if needed.
| [in,out] | fplog | General output file, normally md.log, can be nullptr. |
| [in] | inputRecord | General input parameters (as set up by grompp). |
| [in] | stateGlobal | A pointer to the global state structure. |
| [in] | mpiComm | The MPI communicator for intra-simulation communication. |
| [in] | multiSimRecord | Multi-sim handler |
| [in] | startingFromCheckpoint | Whether the simulation is starting from a checkpoint |
| [in] | usingShellParticles | Whether the user requested shell particles (which is unsupported) |
| [in] | biasInitFilename | Name of file to read PMF and target from. |
| [in,out] | pull_work | Pointer to a pull struct which AWH will couple to, has to be initialized, is assumed not to change during the lifetime of the Awh object. |
| InvalidInputError | If another active module is not supported. |
| void gmx::prepareLogAppending | ( | FILE * | fplog | ) |
Prepare to use the open log file when appending.
Does not throw.
| void gmx::printBinaryInformation | ( | FILE * | fp, |
| const IProgramContext & | programContext, | ||
| const BinaryInformationSettings & | settings | ||
| ) |
Print basic information about the executable with custom settings.
| fp | Where to print the information to. | |
| [in] | programContext | Program information object to use. |
| [in] | settings | Specifies what to print. |
| void gmx::printBinaryInformation | ( | TextWriter * | writer, |
| const IProgramContext & | programContext, | ||
| const BinaryInformationSettings & | settings | ||
| ) |
Print basic information about the executable with custom settings.
Needed to read the members without otherwise unnecessary accessors.
| [out] | writer | Where to print the information. |
| [in] | programContext | Program information object to use. |
| [in] | settings | Specifies what to print. |
| std::bad_alloc | if out of memory. |
| void gmx::printHdf5ErrorsDebug | ( | ) |
Helper function for printing debug statements.
We'd like to embed H5md diagnostic output in an exception object but it can only write it directly to a POSIX stream. Calling this helper method allows some useful information to be passed to the user.
|
static |
Help print error output when interactions are missing in a molblock.
| void gmx::printNbnxmPressureError | ( | const MDLogger & | mdlog, |
| const t_inputrec & | inputrec, | ||
| const gmx_mtop_t & | mtop, | ||
| real | effectiveAtomDensity, | ||
| const PairlistParams & | listParams | ||
| ) |
Prints an estimate of the error in the pressure due to missing interactions.
The NBNxM algorithm tolerates a few missing pair interactions. Missing pair interactions will lead to a systematic overestimates of the pressure when dispersion forces dominate at the cut-off distance. This routine prints an overestimate of the error in the average pressure.
| [in,out] | mdlog | MD logger |
| [in] | inputrec | The input parameter record |
| [in] | mtop | The global topology |
| [in] | effectiveAtomDensity | The effective atom density of the system |
| [in] | listParams | The list setup parameters |
|
static |
Checks the cycles and adds them to *set.
| int gmx::processExceptionAtExitForCommandLine | ( | const std::exception & | ex | ) |
Handles an exception and deinitializes after initForCommandLine.
| [in] | ex | Exception that is the cause for terminating the program. |
This method should be called as the last thing before terminating the program because of an exception. See processExceptionAtExit() for details. Additionally this method undoes the work done by initForCommandLine.
Does not throw.
| void gmx::readKvtCheckpointValue | ( | compat::not_null< ValueType * > | value, |
| std::string_view | name, | ||
| std::string_view | identifier, | ||
| const KeyValueTreeObject & | kvt | ||
| ) |
Read to a key-value-tree value used for checkpointing.
| ValueType |
| [in] | value | the value to be checkpointed |
| [in] | name | name of the value to be checkpointed |
| [in] | identifier | uniquely identifies the module that is checkpointing typically the module name |
| [in] | kvt | the key value tree to read from |
| InternalError | if kvt does not contain requested value. |
| template void gmx::readKvtCheckpointValue | ( | compat::not_null< std::int64_t * > | value, |
| std::string_view | name, | ||
| std::string_view | identifier, | ||
| const KeyValueTreeObject & | kvt | ||
| ) |
Read to a key-value-tree value used for checkpointing.
| ValueType |
| [in] | value | the value to be checkpointed |
| [in] | name | name of the value to be checkpointed |
| [in] | identifier | uniquely identifies the module that is checkpointing typically the module name |
| [in] | kvt | the key value tree to read from |
| InternalError | if kvt does not contain requested value. |
| template void gmx::readKvtCheckpointValue | ( | compat::not_null< real * > | value, |
| std::string_view | name, | ||
| std::string_view | identifier, | ||
| const KeyValueTreeObject & | kvt | ||
| ) |
Read to a key-value-tree value used for checkpointing.
| ValueType |
| [in] | value | the value to be checkpointed |
| [in] | name | name of the value to be checkpointed |
| [in] | identifier | uniquely identifies the module that is checkpointing typically the module name |
| [in] | kvt | the key value tree to read from |
| InternalError | if kvt does not contain requested value. |
|
static |
Initializes the PMF and target with data read from an input table.
| [in] | dimParams | The dimension parameters. |
| [in] | grid | The grid. |
| [in] | filename | The filename to read PMF and target from. |
| [in] | numBias | Number of biases. |
| [in] | biasIndex | The index of the bias. |
| [in,out] | pointState | The state of the points in this bias. |
|
inlinestatic |
Return sum of all elements in float variable (i.e., the variable itself).
| a | variable to reduce/sum. |
|
inlinestatic |
Return sum of all elements in double variable (i.e., the variable itself).
| a | variable to reduce/sum. |
|
inlinestatic |
Energy reduction kernel.
Only works for power of two array sizes.
|
inlinestatic |
Reduce i forces.
Only works for array sizes that are power of 2. Depending on architecture, reduce using DPP shuffles for main forces or atomics. Final accumulation is always done using atomics, while shift forces are using DPP shuffles for non CDNA architectures.
|
inlinestatic |
Final i-force reduction.
Reduce c_nbnxnGpuNumClusterPerSupercluster i-force components stored in fCiBuf[] accumulating atomically into a_f. If calcFShift is true, further reduce shift forces and atomically accumulate into a_fShift.
This implementation works only with power of two array sizes.
|
inlinestatic |
Local memory-based i-force reduction.
Note that this reduction is unoptimized and some of the barrier synchronization used could be avoided on >=8-wide architectures.
|
inlinestatic |
Shuffle-based i-force reduction.
We need to reduce c_clSize values spaced c_clSize threads apart (hardware threads are consecutive for tidxi, have stride c_clSize for tidxj).
We can have up to three reduction steps done with shuffles:
One step (e.g, Intel iGPU, c_clSize == 4, subGroupSize == 8): handled in a separate specialization. Two steps (e.g., NVIDIA, c_clSize == 8, subGroupSize == 32): after two shuffle reduction steps, we do atomicFetchAdd from each sub-group. Three steps (e.g., AMD CDNA, c_clSize == 8, subGroupSize == 64): similar to the two-step approach, but we have two times less atomicFetchAdd's.
|
inlinestatic |
reduceForceIAndFShiftShuffles specialization for single-step reduction (e.g., Intel iGPUs).
We have three components to reduce, but only one reduction step, so it is not possible to gather the components in fx of different threads, like we do with 2 and more reduction steps.
Therefore, first even threads handle X and odd threads handle Y; then, even threads additionally handle Z. This also requires the second fShift buffer register.
After one step of reduction using shuffles is complete, we use atomicAdd to accumulate the results in the global memory. That causes a lot of atomic operations on a single memory location, which is poorly handled by some hardware (e.g., Intel Gen9-11 and Xe LP). This can be remediated by using local memory reduction after shuffles, but that's a TODO.
|
inlinestatic |
Lowest level i force reduction.
Only works for array sizes that are power of 2. Uses atomic operations instead of shuffles.
|
inlinestatic |
Lowest level i force reduction.
Only works for array sizes that are power of 2. Uses AMD DPP instructions to avoid use of atomic operations.
|
inlinestatic |
Reduce c_clSize j-force components using local memory and atomically accumulate into a_f.
c_clSize consecutive threads hold the force components of a j-atom which we reduced in cl_Size steps using shift and atomically accumulate them into a_f.
TODO: implement binary reduction flavor for the case where cl_Size is power of two.
|
inlinestatic |
Reduce c_clSize j-force components using shifts and atomically accumulate into a_f.
c_clSize consecutive threads hold the force components of a j-atom which we reduced in log2(cl_Size) steps using shift and atomically accumulate them into a_f.
|
inlinestatic |
Reduce c_clSize j-force components using AMD DPP instruction.
c_clSize consecutive threads hold the force components of a j-atom which we reduced in log2(cl_Size) steps using shift
Note: This causes massive amount of spills with the tabulated kernel on gfx803 using ROCm 5.3. We don't disable it only for the tabulated kernel as the analytical is the default anyway.
|
inlinestatic |
Add each float to four consecutive memory locations, return sum.
| m | Pointer to memory where four floats should be incremented |
| v0 | float to be added to m[0] |
| v1 | float to be added to m[1] |
| v2 | float to be added to m[2] |
| v3 | float to be added to m[3] |
|
inlinestatic |
Add each double to four consecutive memory locations, return sum.
| m | Pointer to memory where four floats should be incremented |
| v0 | double to be added to m[0] |
| v1 | double to be added to m[1] |
| v2 | double to be added to m[2] |
| v3 | double to be added to m[3] |
| std::vector< real > gmx::removeEmbeddedClassicalCharges | ( | gmx_mtop_t * | mtop, |
| const std::set< int > & | embeddedIndices, | ||
| const std::vector< bool > & | isEmbeddedBlock, | ||
| real | refQ, | ||
| const MDLogger & | logger, | ||
| WarningHandler * | wi | ||
| ) |
Removes classical charges from embedded atoms and virtual sites.
Also removes charges from virtual sites built from embedded atoms only.
| [in,out] | mtop | topology to be modified |
| [in] | embeddedIndices | set with global indices of embedded atoms |
| [in] | isEmbeddedBlock | vector with flags for embedded atom-containing blocks |
| [in] | refQ | reference total charge of the system, used for warning messages |
| [in] | logger | MDLogger for logging info about modifications |
| [in] | wi | WarningHandler for handling warnings |
| void gmx::repartitionAtomMasses | ( | gmx_mtop_t * | mtop, |
| bool | useFep, | ||
| real | massFactor, | ||
| WarningHandler * | wi | ||
| ) |
Scales the smallest masses in the system by up to massFactor.
First finds the smallest atom mass. Then sets all masses that are smaller than the smallest mass time massFactor to the smallest mass time massFactor. The additional mass is taken away from the atom bound to the light atom. A warning is generated when light atoms are present that are unbound. An error is generated when perturbed masses are affected or when a light atom is bound to multiple other atoms or when a bound atom does becomes lighter than the smallest mass times massFactor.
| [in,out] | mtop | The topology to modify |
| [in] | useFep | Whether free-energy perturbation is active |
| [in] | massFactor | The factor to scale the smallest mass by |
| [in,out] | wi | Warning handler |
| void gmx::reportGpuUsage | ( | const MDLogger & | mdlog, |
| ArrayRef< const GpuTaskAssignment > | gpuTaskAssignmentOnRanksOfThisNode, | ||
| size_t | numGpuTasksOnThisNode, | ||
| size_t | numPpRanks, | ||
| bool | printHostName, | ||
| PmeRunMode | pmeRunMode, | ||
| const SimulationWorkload & | simulationWork | ||
| ) |
Log a report on how GPUs are being used on the ranks of the physical node of rank 0 of the simulation.
| [in] | mdlog | Logging object. |
| [in] | gpuTaskAssignmentOnRanksOfThisNode | The selected GPU IDs. |
| [in] | numGpuTasksOnThisNode | The number of GPU tasks on this node. |
| [in] | numPpRanks | Number of PP ranks on this node |
| [in] | printHostName | Print the hostname in the usage information |
| [in] | pmeRunMode | Describes the execution of PME tasks |
| [in] | simulationWork | Simulation workload descriptor |
| std::bad_alloc | if out of memory |
| void gmx::restoreCorrelationGridStateFromHistory | ( | const CorrelationGridHistory & | corrGridHist, |
| CorrelationGrid * | corrGrid | ||
| ) |
Restores the correlation grid state from the correlation grid history.
| [in] | corrGridHist | Correlation grid history to read. |
| [in,out] | corrGrid | Correlation grid state to set. |
| void gmx::resumeIttTracingWhenAppropriate | ( | ) |
Resume tracing when applicable.
When linked with Intel Tracing Technology (ITT, configured with GMX_USE_ITT), data collection can be started conditionally, or it may have been paused from the beginning. If so, resume (or start) collection now. This can help align how GROMACS reports wallcycle counting with how the tracing tool gathers data. If data collection was already started, this does nothing.
|
inlinestatic |
Float round to nearest integer value (in floating-point format).
| a | Any floating-point value |
|
inlinestatic |
double round to nearest integer value (in doubleing-point format).
| a | Any doubleing-point value |
|
inlinestatic |
Round float to int.
Rounding behavior is round to nearest. Rounding of halfway cases is implementation defined (either halfway to even or halfway away from zero).
| int gmx::runCommandLineModule | ( | int | argc, |
| char * | argv[], | ||
| ICommandLineModule * | module | ||
| ) |
Implements a main() method that runs a single module.
This method allows for uniform behavior for binaries that only contain a single module without duplicating any of the implementation from CommandLineModuleManager (startup headers, common options etc.).
The signature assumes that module construction does not throw (because otherwise the caller would need to duplicate all the exception handling code). It is possible to move the construction inside the try/catch in this method using an indirection similar to TrajectoryAnalysisCommandLineRunner::runAsMain(), but until that is necessary, the current approach leads to simpler code.
Usage:
Does not throw. All exceptions are caught and handled internally.
| int gmx::runCommandLineModule | ( | int | argc, |
| char * | argv[], | ||
| const char * | name, | ||
| const char * | description, | ||
| std::function< std::unique_ptr< ICommandLineOptionsModule >()> | factory | ||
| ) |
Implements a main() method that runs a single module.
| argc | argc passed to main(). | |
| argv | argv passed to main(). | |
| [in] | name | Name for the module. |
| [in] | description | Short description for the module. |
| factory | Factory method that creates the module to run. |
This method allows for uniform behavior for binaries that only contain a single module without duplicating any of the implementation from CommandLineModuleManager (startup headers, common options etc.).
Usage:
Does not throw. All exceptions are caught and handled internally.
|
static |
Return true if executing on compatible GPU for AMD OpenCL.
There are known issues with OpenCL when running on 32-wide AMD hardware, such as desktop GPUs with RDNA and RDNA2 architectures (gfx10xx).
|
static |
Return true if executing on compatible GPU for NVIDIA OpenCL.
There are known issues with OpenCL when running on NVIDIA Volta or newer (CC 7+). As a workaround, we recommend using CUDA on such hardware.
This function relies on cl_nv_device_attribute_query. In case it's not functioning properly, we trust the user and mark the device as compatible.
|
static |
Return true if executing on compatible OS for AMD OpenCL.
This is assumed to be true for OS X version of at least 10.10.4 and all other OS flavors.
Uses the BSD sysctl() interfaces to extract the kernel version.
|
static |
The number of sub-parts used for data storage for a GPU cluster pair.
In CUDA the number of threads in a warp is 32 and we have cluster pairs of 8*8=64 atoms, so it's convenient to store data for cluster pair halves, i.e. split in 2.
On architectures with 64-wide execution however it is better to avoid splitting (e.g. AMD GCN, CDNA and later).
|
static |
The nbnxn j-cluster size in atoms for the given NBNxM kernel type.
|
inlinestatic |
Scale positions.
To maximize the ability of the compiler to optimize, all the arrays of RVec should be annotated with gmx_restrict, so the compiler knows there is no aliasing, and for the same reason we do not use ArrayRef<RVec> for them.
|
inlinestatic |
Scale velocities.
To maximize the ability of the compiler to optimize, all the arrays of RVec should be annotated with gmx_restrict, so the compiler knows there is no aliasing, and for the same reason we do not use ArrayRef<RVec> for them.
|
inlinestatic |
Select from single precision variable where boolean is true.
| a | Floating-point variable to select from |
| mask | Boolean selector |
|
inlinestatic |
Select from double precision variable where boolean is true.
| a | double variable to select from |
| mask | Boolean selector |
|
inlinestatic |
Select from integer variable where boolean is true.
| a | Integer variable to select from |
| mask | Boolean selector |
|
inlinestatic |
Select from single precision variable where boolean is false.
| a | Floating-point variable to select from |
| mask | Boolean selector |
|
inlinestatic |
Select from double precision variable where boolean is false.
| a | double variable to select from |
| mask | Boolean selector |
|
inlinestatic |
Select from integer variable where boolean is false.
| a | Integer variable to select from |
| mask | Boolean selector |
|
inlinestatic |
Return a pointer to the prune kernel version to be executed at the current invocation.
| [in] | kernel_pruneonly | array of prune kernel objects |
| [in] | firstPrunePass | true if the first pruning pass is being executed |
| void gmx::serializeMrcDensityMapHeader | ( | ISerializer * | serializer, |
| const MrcDensityMapHeader & | mrcHeader | ||
| ) |
Serializes an MrcDensityMapHeader from a given serializer.
| [in] | serializer | the serializer |
| [in] | mrcHeader | file header to be serialized |
Maclaurin series for sinh(x)/x.
Used for NH chains and MTTK pressure control. Here, we compute it to 10th order, which might be an overkill. 8th is probably enough, but it's not very much more expensive.
| void gmx::setAttribute | ( | const hid_t | container, |
| const char * | attributeName, | ||
| const ValueType & | value | ||
| ) |
Write a scalar attribute of a given data type.
| ValueType | The type of the attribute to write |
| [in] | container | The HDF5 container (group or dataset) to write the attribute to. |
| [in] | attributeName | The name of the attribute to write. |
| [in] | value | The scalar to write. |
| void gmx::setAttribute | ( | const hid_t | container, |
| const char * | attributeName, | ||
| const char * | value | ||
| ) |
Write a scalar attribute of a given data type.
| ValueType | The type of the attribute to write |
| [in] | container | The HDF5 container (group or dataset) to write the attribute to. |
| [in] | attributeName | The name of the attribute to write. |
| [in] | value | The scalar to write. Specialization of setAttribute() for writing attributes of char* type. |
| void gmx::setAttribute | ( | const hid_t | container, |
| const char * | attributeName, | ||
| const std::string & | value | ||
| ) |
Write a scalar attribute of a given data type.
| ValueType | The type of the attribute to write |
| [in] | container | The HDF5 container (group or dataset) to write the attribute to. |
| [in] | attributeName | The name of the attribute to write. |
| [in] | value | The scalar to write. Specialization of setAttribute() for writing attributes of std::string type. |
| std::vector< char > gmx::setAttributeStringVector | ( | const hid_t | container, |
| const char * | attributeName, | ||
| std::vector< char > && | buffer, | ||
| Iterator | begin, | ||
| Iterator | end | ||
| ) |
Write a vector-like string attribute via iterators String data type is treated specially because of the HDF5 requirements for contiguous memory storage for fixed-size strings. A reusable character buffer is needed to avoid frequent memory allocations for multiple writing of different string attributes.
| Iterator | The type of the iterator to write. |
| [in] | container | The HDF5 container (group or dataset) to write the attribute to. |
| [in] | attributeName | The name of the attribute to write. |
| [in] | buffer | The buffer to write the strings into, could leave it empty {}. |
| [in] | begin | The beginning iterator of the data to write. |
| [in] | end | The ending iterator of the data to write. |
| void gmx::setAttributeVector | ( | const hid_t | container, |
| const char * | attributeName, | ||
| ArrayRef< const ValueType > | value | ||
| ) |
Write a vector-like attribute of a given data type.
| ValueType | The type of the attribute to write. |
| [in] | container | The path of the group or dataset to write the attribute to. |
| [in] | attributeName | The name of the attribute to write. |
| [in] | value | The 1D-vector to write, provided as an ArrayRef. |
| void gmx::setAttributeVector | ( | hid_t | container, |
| const char * | attributeName, | ||
| ArrayRef< const std::string > | values | ||
| ) |
Write a vector-like attribute of strings.
| [in] | container | The path of the group or dataset to write the attribute to. |
| [in] | attributeName | The name of the attribute to write. |
| [in] | values | The 1D-vector to write, provided as an ArrayRef. |
| void gmx::setAttributeVector | ( | hid_t | container, |
| const char * | attributeName, | ||
| ArrayRef< const char *const > | values | ||
| ) |
Write a vector-like attribute of C-strings.
| [in] | container | The path of the group or dataset to write the attribute to. |
| [in] | attributeName | The name of the attribute to write. |
| [in] | values | The 1D-vector to write, provided as an ArrayRef. |
| void gmx::setBoxDeformationFlowMatrix | ( | const matrix | boxDeformationVelocity, |
| const matrix | box, | ||
| matrix | flowMatrix | ||
| ) |
Set a matrix for computing the flow velocity at coordinates.
Used with continuous box deformation for calculating the flow profile. Sets a matrix which can be used to multiply with coordinates to obtain the flow velocity at that coordinate.
| [in] | boxDeformationVelocity | The velocity of the box in nm/ps |
| [in] | box | The box in nm |
| [out] | flowMatrix | The deformation rate in ps^-1 |
|
static |
Set the dynamic pairlist pruning parameters in ic.
| [in] | inputrec | The input parameter record |
| [in] | mtop | The global topology |
| [in] | effectiveAtomDensity | The effective atom density of the system |
| [in] | useGpuList | Tells if we are using a GPU type pairlist |
| [in] | listSetup | The nbnxn pair list setup |
| [in] | userSetNstlistPrune | The user set ic->nstlistPrune (using an env.var.) |
| [in] | interactionConst | The nonbonded interactions constants |
| [in,out] | listParams | The list setup parameters |
| void gmx::setLibraryFileFinder | ( | const DataFileFinder * | finder | ) |
Sets a finder for location data files from share/top/.
| [in] | finder | finder to set (can be NULL to restore the default finder). |
The library does not take ownership of finder. The provided object must remain valid until the global instance is changed by another call to setLibraryFileFinder().
The global instance is used by findLibraryFile() and openLibraryFile().
This method is not thread-safe. See setProgramContext(); the same constraints apply here as well.
Does not throw.
| void gmx::setStateDependentAwhParams | ( | AwhParams * | awhParams, |
| const pull_params_t & | pull_params, | ||
| pull_t * | pull_work, | ||
| const matrix | box, | ||
| PbcType | pbcType, | ||
| const tensor & | compressibility, | ||
| const t_inputrec & | inputrec, | ||
| real | initLambda, | ||
| const gmx_mtop_t & | mtop, | ||
| WarningHandler * | wi | ||
| ) |
Sets AWH parameters that need state parameters such as the box vectors.
| [in,out] | awhParams | AWH parameters. |
| [in] | pull_params | Pull parameters. |
| [in,out] | pull_work | Pull working struct to register AWH bias in. |
| [in] | box | Box vectors. |
| [in] | pbcType | Periodic boundary conditions enum. |
| [in] | compressibility | Compressibility matrix for pressure coupling, pass all 0 without pressure coupling |
| [in] | inputrec | Input record, for checking the reference temperature |
| [in] | initLambda | The starting lambda, to allow using free energy lambda as reaction coordinate provider in any dimension. |
| [in] | mtop | The system topology. |
| [in,out] | wi | Struct for bookeeping warnings. |
|
static |
Sets AWH parameters, for one AWH pull dimension.
| [in,out] | dimParams | AWH dimension parameters. |
| [in] | biasIndex | The index of the bias containing this AWH pull dimension. |
| [in] | dimIndex | The index of this AWH pull dimension. |
| [in] | pull_params | Pull parameters. |
| [in,out] | pull_work | Pull working struct to register AWH bias in. |
| [in] | pbc | A pbc information structure. |
| [in] | compressibility | Compressibility matrix for pressure coupling, pass all 0 without pressure coupling. |
| [in,out] | wi | Struct for bookeeping warnings. |
| void gmx::setStringAttributeByBuffer | ( | const hid_t | container, |
| const char * | attributeName, | ||
| const size_t | numberOfStrings, | ||
| const int | maxStrLength, | ||
| ArrayRef< const char > | buffer | ||
| ) |
Low-level utility function to write a string-vector attribute via a character buffer.
The size of the character buffer must be greater than or equal to numberOfStrings * (maxStrLength + 1).
| [in] | container | The HDF5 container to write the attribute to. |
| [in] | attributeName | The name of the attribute to write. |
| [in] | numberOfStrings | The number of strings in the vector. |
| [in] | maxStrLength | The maximum length of the strings in the vector. |
| [in] | buffer | The character buffer to write. |
| void gmx::setThrowForPerformanceProblems | ( | bool | newValue | ) |
Flag for controlling behaviour in cases where performance might be low.
In mdrun, by default we will make an efficient task assignment by creating as many tasks as available GPUs. If users make a partial assigment that would likely be inefficient (e.g. using fewer ranks than GPUs, or like -nb gpu -pme cpu -npme 1), we want users to think about what they are doing and be fully specific if they really want to do things their way.
In tests, we want to be able to cover many code paths on the available hardware regardless of performance. This setter allows test code to avoid irrelevant fatal errors about performance.
| SettleParameters gmx::settleParameters | ( | real | mO, |
| real | mH, | ||
| real | invmO, | ||
| real | invmH, | ||
| real | dOH, | ||
| real | dHH | ||
| ) |
Computes and returns settle parameters.
| [in] | mO | Mass of oxygen atom |
| [in] | mH | Mass of hydrogen atom |
| [in] | invmO | Reciprocal mass of oxygen atom |
| [in] | invmH | Reciprocal mass of hydrogen atom |
| [in] | dOH | Target O-H bond length |
| [in] | dHH | Target H-H bond length |
| DomainLifetimeWorkload gmx::setupDomainLifetimeWorkload | ( | const t_inputrec & | inputrec, |
| const t_forcerec & | fr, | ||
| const pull_t * | pull_work, | ||
| const gmx_edsam * | ed, | ||
| const t_mdatoms & | mdatoms, | ||
| const SimulationWorkload & | simulationWork | ||
| ) |
Set up workload flags that have the lifetime of the PP domain decomposition.
This function should be called every time after domain decomposition happens. Also note that fr->listedForcesGpu->updateHaveInteractions() should be called before this function anytime a change in listed forces assignment after repartitioning can be expected.
| [in] | inputrec | The input record |
| [in] | fr | The force record |
| [in] | pull_work | Pull data |
| [in] | ed | Essential dynamics data |
| [in] | mdatoms | Atom parameter data |
| [in] | simulationWork | Simulation workload flags |
| void gmx::setupDynamicPairlistPruning | ( | const MDLogger & | mdlog, |
| const t_inputrec & | inputrec, | ||
| const gmx_mtop_t & | mtop, | ||
| real | effectiveAtomDensity, | ||
| const interaction_const_t & | interactionConst, | ||
| PairlistParams * | listParams | ||
| ) |
Set up the dynamic pairlist pruning.
| [in,out] | mdlog | MD logger |
| [in] | inputrec | The input parameter record |
| [in] | mtop | The global topology |
| [in] | effectiveAtomDensity | The effective atom density of the system |
| [in] | interactionConst | The nonbonded interactions constants |
| [in,out] | listParams | The list setup parameters |
|
static |
Set up the different force buffers; also does clearing.
| [in] | forceHelperBuffers | Helper force buffers |
| [in] | force | force array |
| [in] | domainWork | Domain lifetime workload flags |
| [in] | stepWork | Step schedule flags |
| [in] | havePpDomainDecomposition | Whether we have a PP domain decomposition |
| [out] | wcycle | wallcycle recording structure |
| void gmx::setupGpuShortRangeWorkLow | ( | NbnxmGpu gmx_unused * | nb, |
| const ListedForcesGpu gmx_unused * | listedForcesGpu, | ||
| InteractionLocality gmx_unused | iLocality | ||
| ) |
Set up internal flags that indicate what type of short-range work there is.
As nonbondeds and bondeds share input/output buffers and GPU queues, both are considered when checking for work in the current domain.
This function is expected to be called every time the work-distribution can change (i.e. at search/domain decomposition steps).
| [in,out] | nb | Pointer to the nonbonded GPU data structure |
| [in] | listedForcesGpu | Pointer to the GPU bonded data structure |
| [in] | iLocality | Interaction locality identifier |
|
static |
For PP ranks, sets or makes the communicator.
For PME ranks get the rank id. For PP only ranks, sets the PME-only rank.
|
static |
Setup for the local GPU force reduction: reinitialization plus the registration of forces and dependencies.
| [in] | runScheduleWork | Schedule workload flag structure |
| [in] | nbv | Non-bonded Verlet object |
| [in] | stateGpu | GPU state propagator object |
| [in] | gpuForceReduction | GPU force reduction object |
| [in] | pmePpCommGpu | PME-PP GPU communication object |
| [in] | pmedata | PME data object |
| [in] | dd | Domain decomposition object |
| std::vector< MtsLevel > gmx::setupMtsLevels | ( | const GromppMtsOpts & | mtsOpts, |
| std::vector< std::string > * | errorMessages | ||
| ) |
Sets up and returns the MTS levels and checks requirements of MTS.
Appends errors about allowed input values ir to errorMessages, when not nullptr.
| [in] | mtsOpts | Options for setting the MTS levels |
| [in,out] | errorMessages | List of error messages, can be nullptr |
|
static |
Setup for the non-local GPU force reduction: reinitialization plus the registration of forces and dependencies.
| [in] | runScheduleWork | Schedule workload flag structure |
| [in] | nbv | Non-bonded Verlet object |
| [in] | stateGpu | GPU state propagator object |
| [in] | gpuForceReduction | GPU force reduction object |
| [in] | dd | Domain decomposition object |
| StepWorkload gmx::setupStepWorkload | ( | const int | legacyFlags, |
| ArrayRef< const gmx::MtsLevel > | mtsLevels, | ||
| const int64_t | step, | ||
| const DomainLifetimeWorkload & | domainWork, | ||
| const SimulationWorkload & | simulationWork | ||
| ) |
Set up force flag struct from the force bitmask.
| [in] | legacyFlags | Force bitmask flags used to construct the new flags |
| [in] | mtsLevels | The multiple time-stepping levels, either empty or 2 levels |
| [in] | step | The current MD step |
| [in] | domainWork | Domain lifetime workload description. |
| [in] | simulationWork | Simulation workload description. |
|
inlinestatic |
Helper function to set any SIMD or scalar variable to zero.
| void gmx::shiftAtoms | ( | const RVec & | shift, |
| ArrayRef< RVec > | x | ||
| ) |
Shift all coordinates.
Shift coordinates by a previously calculated value.
Can be used to e.g. place particles in a box.
| [in] | shift | Translation that should be applied. |
| [in] | x | Coordinates to translate. |
| bool gmx::simdCheck | ( | const CpuInfo & | cpuInfo, |
| SimdType | wanted, | ||
| FILE * | log, | ||
| bool | warnToStdErr | ||
| ) |
Check if binary was compiled with the provided SIMD type.
| cpuInfo | Information about the CPU we are running on |
| wanted | SIMD type to query. If this matches the suggested type for this cpu, the routine returns quietly. |
| log | If not nullptr, statistics will be printed to the file. If we do not have a match there will also be a warning. |
| warnToStdErr | If true, warnings will also be printed to stderr. |
|
inlinestatic |
Prefetch memory at address m.
This typically prefetches one cache line of memory from address m, usually 64bytes or more, but the exact amount will depend on the implementation. On many platforms this is simply a no-op. Technically it might not be part of the SIMD instruction set, but since it is a hardware-specific function that is normally only used in tight loops where we also apply SIMD, it fits well here.
There are no guarantees about the level of cache or temporality, but usually we expect stuff to end up in level 2, and be used in a few hundred clock cycles, after which it stays in cache until evicted (normal caching).
| m | Pointer to location prefetch. There are no alignment requirements, but if the pointer is not aligned the prefetch might start at the lower cache line boundary (meaning fewer bytes are prefetched). |
|
inlinestatic |
Float sin.
| x | The argument to evaluate sin for |
|
inlinestatic |
Double sin.
| x | The argument to evaluate sin for |
|
inlinestatic |
Float sin & cos.
| x | The argument to evaluate sin/cos for | |
| [out] | sinval | Sin(x) |
| [out] | cosval | Cos(x) |
|
inlinestatic |
Double sin & cos.
| x | The argument to evaluate sin/cos for | |
| [out] | sinval | Sin(x) |
| [out] | cosval | Cos(x) |
|
inlinestatic |
Double sin & cos, but with single accuracy.
| x | The argument to evaluate sin/cos for | |
| [out] | sinval | Sin(x) |
| [out] | cosval | Cos(x) |
|
inlinestatic |
Double sin, but with single accuracy.
| x | The argument to evaluate sin for |
|
inlinestatic |
Calculate sixth root of x in single precision.
| x | Argument, must be greater than or equal to zero. |
This routine is typically faster than using std::pow().
|
inlinestatic |
Calculate sixth root of x in double precision.
| x | Argument, must be greater than or equal to zero. |
This routine is typically faster than using std::pow().
|
inlinestatic |
Calculate sixth root of integer x, return double.
| x | Argument, must be greater than or equal to zero. |
This routine is typically faster than using std::pow().
|
static |
Sorts particle index a on coordinates x along dim.
Backwards tells if we want decreasing iso increasing coordinates. h0 is the minimum of the coordinate range. invh is the 1/length of the sorting range. n_per_h (>=n) is the expected average number of particles per 1/invh sort is the sorting work array. sort should have a size of at least n_per_h*c_sortGridRatio + n, or easier, allocate at least n*c_sortGridMaxSizeFactor elements.
|
static |
Set non-bonded interaction flags for the current cluster.
Sorts atoms on LJ coefficients: !=0 first, ==0 at the end.
| std::vector< bool > gmx::splitEmbeddedBlocks | ( | gmx_mtop_t * | mtop, |
| const std::set< int > & | embeddedIndices | ||
| ) |
Splits embedded atom containing molecules out of MM blocks in topology.
Modifies molblocks in topology mtop
| [in,out] | mtop | topology to be modified |
| [in] | embeddedIndices | set with global indices of embedded atoms |
| std::vector< std::filesystem::path > gmx::splitPathEnvironment | ( | const std::string & | pathEnv | ) |
Split PATH environment variable into search paths.
| [in] | pathEnv | String to split. |
| IntegerBox gmx::spreadRangeWithinLattice | ( | const IVec & | center, |
| dynamicExtents3D | extent, | ||
| IVec | range | ||
| ) |
Construct a box that holds all indices that are not more than a given range remote from center coordinates and still within a given lattice extent.
| [in] | center | the coordinates of the center of the spread range |
| [in] | extent | the end of the lattice, number of lattice points in each dimension |
| [in] | range | the distance from the center |
|
inlinestatic |
Float sqrt(x). This is the square root.
| x | Argument, should be >= 0. |
|
inlinestatic |
Double sqrt(x). This is the square root.
| x | Argument, should be >= 0. |
|
inlinestatic |
Calculate sqrt(x) for double, but with single accuracy.
| x | Argument that must be >=0. |
| T gmx::square | ( | T | x | ) |
calculate x^2
| T | Type of argument and return value |
| x | argument |
|
inlinestatic |
Store contents of float variable to aligned memory m.
| [out] | m | Pointer to memory. |
| a | float variable to store |
|
inlinestatic |
Store contents of double variable to aligned memory m.
| [out] | m | Pointer to memory. |
| a | double variable to store |
|
inlinestatic |
Store contents of integer variable to aligned memory m.
| [out] | m | Pointer to memory. |
| a | integer variable to store |
|
inlinestatic |
Store contents of float variable to unaligned memory m.
| [out] | m | Pointer to memory, no alignment requirement. |
| a | float variable to store. |
|
inlinestatic |
Store contents of double variable to unaligned memory m.
| [out] | m | Pointer to memory, no alignment requirement. |
| a | double variable to store. |
|
inlinestatic |
Store contents of integer variable to unaligned memory m.
| [out] | m | Pointer to memory, no alignment requirement. |
| a | integer variable to store. |
|
inlinestatic |
Returns the input string, throwing an exception if the demanded conversion to an array will not succeed.
| ValueType | array element type to convert into |
| NumExpectedValues | number of values of the array |
| [in] | toConvert | the string to convert |
| [in] | errorContextMessage | the message to add to the thrown exceptions if conversion of the string is bound to fail at some point |
| InvalidInputError | if splitting the string at whitespaces does not result in NumExpectedValues or zero substrings |
| InvalidInputError | if conversion of any of the NumExpectedValues substrings of the splitted input string fails |
A typical use of this function would be in .mdp string option parsing where information in the .mdp file is transformed into the data that is stored in the .tpr file.
| void gmx::sumOverSimulations | ( | ArrayRef< T > | data, |
| MPI_Comm | multiSimComm, | ||
| const bool | broadcastWithinSimulation, | ||
| const MpiComm & | mpiComm | ||
| ) |
Sum an array over all simulations on main ranks or all ranks of each simulation.
This assumes the data is identical on all ranks within each simulation.
| [in,out] | data | The data to sum. |
| [in] | multiSimComm | Communicator for the main ranks of sharing simulations. |
| [in] | broadcastWithinSimulation | Broadcast the result to all ranks within the simulation |
| [in] | mpiComm | MPI communicator for intra-simulation communication. |
|
static |
Returns if we can (heuristically) change nstlist and rlist.
| [in] | ir | The input parameter record |
|
inlinestatic |
Helper function to add a custom operation to the SYCL handler.
In ACpp, it relies on the ACPP_EXT_ENQUEUE_CUSTOM_OPERATION extension. Should not be called when the extension is not available.
|
inlinestatic |
Helper function to submit a SYCL operation without returning an event.
Gives some nice performance optimizations, especially on AMD and NVIDIA devices.
In ACpp, it relies on the ACPP_EXT_CG_PROPERTY_* and ACPP_EXT_COARSE_GRAINED_EVENTS extensions.
In DPC++, it relies (when explicitly enabled) on SYCL_EXT_ONEAPI_ENQUEUE_FUNCTIONS Falls back to the default submit otherwise.
The function aims to avoid the overhead associated with creating/recording/destroying events.
| bool gmx::systemHasConstraintsOrVsites | ( | const gmx_mtop_t & | mtop | ) |
Returns whether mtop contains any constraints and/or vsites.
When we have constraints and/or vsites, it is beneficial to use update groups (when possible) to allow independent update of groups.
|
inlinestatic |
Float tan.
| x | The argument to evaluate tan for |
|
inlinestatic |
Double tan.
| x | The argument to evaluate tan for |
|
inlinestatic |
Double tan, but with single accuracy.
| x | The argument to evaluate tan for |
|
inlinestatic |
Return true if any bits are set in the float variable.
This function is used to handle bitmasks, mainly for exclusions in the inner kernels. Note that it will return true even for -0.0f (sign bit set), so it is not identical to not-equal.
| a | value |
|
inlinestatic |
Return true if any bits are set in the double variable.
This function is used to handle bitmasks, mainly for exclusions in the inner kernels. Note that it will return true even for -0.0 (sign bit set), so it is not identical to not-equal.
| a | value |
|
inlinestatic |
Return true if any bits are set in the integer variable.
This function is used to handle bitmasks, mainly for exclusions in the inner kernels.
| a | value |
|
static |
Barrier for safe simultaneous thread access to mdrunner data.
Used to ensure that the main thread does not modify mdrunner during copy on the spawned threads.
| void gmx::throwUponInvalidHid | ( | const hid_t | id, |
| const std::string & | message | ||
| ) |
Throw a gmx::FileIOError if the HDF5 ID is invalid (H5Iis_valid <= 0).
| [in] | id | The id to check. |
| [in] | message | The message to throw. |
|
inline |
Check whether two times are nearly equal.
Times are considered close if their absolute difference is smaller than c_timePrecision.
| time | The test time |
| referenceTime | The reference time |
|
inlinestatic |
Subtract 3 floats from base/offset.
| align | Alignment of the memory to which we write, i.e. distance (measured in elements, not bytes) between index points. |
| [out] | base | Pointer to the start of the memory area |
| offset | Offset to the start of triplet. | |
| v0 | 1st value, subtracted from base[align*offset[0]]. | |
| v1 | 2nd value, subtracted from base[align*offset[0] + 1]. | |
| v2 | 3rd value, subtracted from base[align*offset[0] + 2]. |
|
inlinestatic |
Subtract 3 doubles from base/offset.
| align | Alignment of the memory to which we write, i.e. distance (measured in elements, not bytes) between index points. |
| [out] | base | Pointer to the start of the memory area |
| offset | Offset to the start of triplet. | |
| v0 | 1st value, subtracted from base[align*offset[0]]. | |
| v1 | 2nd value, subtracted from base[align*offset[0] + 1]. | |
| v2 | 3rd value, subtracted from base[align*offset[0] + 2]. |
|
inlinestatic |
Add 3 floats to base/offset.
| align | Alignment of the memory to which we write, i.e. distance (measured in elements, not bytes) between index points. |
| [out] | base | Pointer to the start of the memory area |
| offset | Offset to the start of triplet. | |
| v0 | 1st value, added to base[align*offset[0]]. | |
| v1 | 2nd value, added to base[align*offset[0] + 1]. | |
| v2 | 3rd value, added to base[align*offset[0] + 2]. |
|
inlinestatic |
Add 3 doubles to base/offset.
| align | Alignment of the memory to which we write, i.e. distance (measured in elements, not bytes) between index points. |
| [out] | base | Pointer to the start of the memory area |
| offset | Offset to the start of triplet. | |
| v0 | 1st value, added to base[align*offset[0]]. | |
| v1 | 2nd value, added to base[align*offset[0] + 1]. | |
| v2 | 3rd value, added to base[align*offset[0] + 2]. |
|
inlinestatic |
Store 3 floats to 3 to base/offset.
| align | Alignment of the memory to which we write, i.e. distance (measured in elements, not bytes) between index points. |
| [out] | base | Pointer to the start of the memory area |
| offset | Offset to the start of triplet. | |
| v0 | 1st value, written to base[align*offset[0]]. | |
| v1 | 2nd value, written to base[align*offset[0] + 1]. | |
| v2 | 3rd value, written to base[align*offset[0] + 2]. |
|
inlinestatic |
Store 3 doubles to 3 to base/offset.
| align | Alignment of the memory to which we write, i.e. distance (measured in elements, not bytes) between index points. |
| [out] | base | Pointer to the start of the memory area |
| offset | Offset to the start of triplet. | |
| v0 | 1st value, written to base[align*offset[0]]. | |
| v1 | 2nd value, written to base[align*offset[0] + 1]. | |
| v2 | 3rd value, written to base[align*offset[0] + 2]. |
|
inlinestatic |
Truncate float, i.e. round towards zero - common hardware instruction.
| a | Any floating-point value |
|
inlinestatic |
Truncate double, i.e. round towards zero - common hardware instruction.
| a | Any doubleing-point value |
| const char * gmx::unitCellTypeNames | ( | UnitCellType | type | ) |
Get names for the different unit cell representation types.
| [in] | type | What name needs to be provided. |
|
static |
unpack non-local force data buffer on the GPU using pre-populated "map" containing index information.
| [out] | gm_data | full array of force values |
| [in] | gm_dataPacked | packed array of force values to be transferred |
| [in] | gm_map | array of indices defining mapping from full to packed array |
| [in] | mapSize | number of elements in map array |
| void gmx::updateCorrelationGridHistory | ( | CorrelationGridHistory * | corrGridHist, |
| const CorrelationGrid & | corrGrid | ||
| ) |
Update the correlation grid history for checkpointing.
| [in,out] | corrGridHist | Correlation grid history to set. |
| [in] | corrGrid | Correlation grid state to read. |
|
static |
|
inlinestatic |
Update positions.
To maximize the ability of the compiler to optimize, all the arrays of RVec should be annotated with gmx_restrict, so the compiler knows there is no aliasing, and for the same reason we do not use ArrayRef<RVec> for them.
|
inlinestatic |
Update velocities.
To maximize the ability of the compiler to optimize, all the arrays of RVec should be annotated with gmx_restrict, so the compiler knows there is no aliasing, and for the same reason we do not use ArrayRef<RVec> for them.
|
inlinestatic |
Returns true if LJ combination rules are used in the non-bonded kernels.
| [in] | vdwType | The VdW interaction/implementation type as defined by VdwType enumeration. |
|
static |
Query if a value is in range of the grid.
| [in] | value | Value to check. |
| [in] | axis | The grid axes. |
|
static |
Checks if a value is within an interval.
| [in] | origin | Start value of interval. |
| [in] | end | End value of interval. |
| [in] | period | Period (or 0 if not periodic). |
| [in] | value | Value to check. |
|
noexcept |
Return true if the template value type matches the HDF5 data type.
| ValueType | Type of value to check. |
| [in] | dataType | Handle to HDF5 data type to check against. |
|
noexcept |
Return true if the template value type matches the HDF5 data type.
Helper function to allow for ValueType inference from a buffer.
| ValueType | Type of value to check. |
| [in] | dataType | Handle to HDF5 data type to check against. |
| [in] | valueBuffer | Unused buffer which allows the compiler to infer the value type. |
|
inlinenoexcept |
Return true if the template value type matches the HDF5 data type.
| ValueType | Type of value to check. |
| [in] | dataType | Handle to HDF5 data type to check against. |
|
inlinenoexcept |
Return true if the template value type matches the HDF5 data type.
| ValueType | Type of value to check. |
| [in] | dataType | Handle to HDF5 data type to check against. |
|
inlinenoexcept |
Return true if the template value type matches the HDF5 data type.
| ValueType | Type of value to check. |
| [in] | dataType | Handle to HDF5 data type to check against. |
|
static |
Returns the sum of the vsite ilist sizes over all vsite types.
| [in] | ilist | The interaction list |
| void gmx::write_IMDgroup_to_file | ( | bool | bIMD, |
| t_inputrec * | ir, | ||
| const t_state * | state, | ||
| const gmx_mtop_t & | sys, | ||
| int | nfile, | ||
| const t_filenm | fnm[] | ||
| ) |
Writes out the group of atoms selected for interactive manipulation.
Called by grompp. The resulting file has to be read in by VMD if one wants it to connect to mdrun.
| bIMD | Only springs into action if bIMD is TRUE. Otherwise returns directly. |
| ir | Structure containing MD input parameters, among those the IMD data structure. |
| state | The current state of the MD system. |
| sys | The global, complete system topology. |
| nfile | Number of files. |
| fnm | Filename struct. |
| void gmx::writeAtomicProperties | ( | AtomRange & | atomRange, |
| const hid_t | baseContainer, | ||
| const std::optional< IndexMap > & | selectedAtomsIndexMap = std::nullopt |
||
| ) |
Write atomic properties to the H5MD file.
The result atomic properties are directly stored in the baseContainer. Atomic information includes:
| [in] | atomRange | Atom range for iterating all atoms and accessing atomic properties. |
| [in] | baseContainer | The HDF5 container to write the atomic properties to. |
| [in] | selectedAtomsIndexMap | The index map of the selected atoms, not provided means considering all atoms. Providing an empty map throws an internal error. |
| void gmx::writeBonds | ( | const gmx_mtop_t & | topology, |
| const hid_t | baseContainer, | ||
| const std::optional< IndexMap > & | selectedAtomsIndexMap = std::nullopt |
||
| ) |
Write the covalent connectivity to the H5MD file.
The result bond connectivity is stored in the group <baseContainer>/bonds. The connectivity information is deduced from the topology and written as an [numBonds x 2] dataset of int64_t. If a selection is applied, only the bonds where both bonded particles are within the selection are considered.
| [in] | topology | The topology of the simulation system. |
| [in] | baseContainer | The HDF5 container to write the connectivity to. |
| [in] | selectedAtomsIndexMap | The index map of the selected atoms, not provided means considering all atoms. Providing an empty map throws an internal error. |
| void gmx::writeDisulfideBonds | ( | const gmx_mtop_t & | topology, |
| const hid_t | baseContainer, | ||
| const std::optional< IndexMap > & | selectedAtomsIndexMap = std::nullopt |
||
| ) |
Write the additional annotation of disulfide bonds to the H5MD file.
The result bond connectivity is stored in the group <baseContainer>/disulfide_bonds.
| [in] | topology | The topology of the simulation system. |
| [in] | baseContainer | The HDF5 container to write the connectivity to. |
| [in] | selectedAtomsIndexMap | The index map of the selected atoms, not provided means considering all atoms. Providing an empty map throws an internal error. |
| void gmx::writeHeader | ( | TextWriter * | writer, |
| const std::string & | text, | ||
| const std::string & | section, | ||
| bool | writeFormattedText | ||
| ) |
Write appropiate Header to output stream.
| [in] | writer | TextWriter object for writing information. |
| [in] | text | String with the header before writing. |
| [in] | section | String with section text for header. |
| [in] | writeFormattedText | If we need to format the text for LaTeX output or not |
| void gmx::writeInformation | ( | TextOutputFile * | outputStream, |
| const t_inputrec & | ir, | ||
| const gmx_mtop_t & | top, | ||
| bool | writeFormattedText, | ||
| bool | notStdout | ||
| ) |
Wrapper for writing out information.
This function is actual called from within the run method to write the information to the terminal or to file. New write out methods should be added to it instead of adding them in run.
| [in] | outputStream | The filestream used to write the information to. |
| [in] | ir | Reference to inputrec of the run input. |
| [in] | top | Local topology used to derive the information to write out. |
| [in] | writeFormattedText | Decide if we want formatted text output or not. |
| [in] | notStdout | Bool to see if we can close the file after writing or not in case of stdout. |
| void gmx::writeKeyValueTreeAsMdp | ( | TextWriter * | writer, |
| const KeyValueTreeObject & | tree | ||
| ) |
Write a flat key-value tree to writer in mdp style.
Sub-objects will output nothing, so they can be used to contain a special key-value pair to create a comment, as well as the normal key and value. The comment pair will have a key of "comment", and the value will be used as a comment (if non-empty).
| void gmx::writeKvtCheckpointValue | ( | const ValueType & | value, |
| std::string_view | name, | ||
| std::string_view | identifier, | ||
| KeyValueTreeObjectBuilder | kvtBuilder | ||
| ) |
Write to a key-value-tree used for checkpointing.
| ValueType |
| [in] | value | name of the value to be checkpointed |
| [in] | name | the value to be checkpointed |
| [in] | identifier | uniquely identifies the module that is checkpointing typically the module name |
| [in] | kvtBuilder | the key-value-tree builder used to store the checkpoint values |
| template void gmx::writeKvtCheckpointValue | ( | const std::int64_t & | value, |
| std::string_view | name, | ||
| std::string_view | identifier, | ||
| KeyValueTreeObjectBuilder | kvtBuilder | ||
| ) |
Write to a key-value-tree used for checkpointing.
| ValueType |
| [in] | value | name of the value to be checkpointed |
| [in] | name | the value to be checkpointed |
| [in] | identifier | uniquely identifies the module that is checkpointing typically the module name |
| [in] | kvtBuilder | the key-value-tree builder used to store the checkpoint values |
| template void gmx::writeKvtCheckpointValue | ( | const real & | value, |
| std::string_view | name, | ||
| std::string_view | identifier, | ||
| KeyValueTreeObjectBuilder | kvtBuilder | ||
| ) |
Write to a key-value-tree used for checkpointing.
| ValueType |
| [in] | value | name of the value to be checkpointed |
| [in] | name | the value to be checkpointed |
| [in] | identifier | uniquely identifies the module that is checkpointing typically the module name |
| [in] | kvtBuilder | the key-value-tree builder used to store the checkpoint values |
| void gmx::writeMoleculeBlocks | ( | const hid_t | baseContainer, |
| const ArrayRef< const gmx_molblock_t > | molBlocks | ||
| ) |
Write the molecule block information to the HDF5 container of GROMACS internal topology.
<baseContainer>/<moleculeTypeName> group.| [in] | baseContainer | The HDF5 container to write the topology information to. |
| [in] | molBlocks | The molecule blocks to write. |
| void gmx::writeMoleculeTypes | ( | const hid_t | baseContainer, |
| const ArrayRef< const gmx_moltype_t > | moltypes | ||
| ) |
Write a set of molecule type blocks in moltypes to the HDF5 container baseContainer.
The hierarchy is as follows:
/h5md/modules/gromacs_topology (group (baseContainer) for H5md internal topology module) ++ molecule_names (attribute for the names of molecules in the system) -- molecule1 (group for molecule 1, same group name as molecule_names[0]) ++ nr_particles (attribute for the number of particles in molecule 1) ++ nr_residues (attribute for the number of residues in molecule 1) -- id (dataset for the atomic identifier in molecule 1) -- mass (dataset for the atomic masses in molecule 1) -- charge (dataset for the atomic charges in molecule 1) -- species (dataset for the atomic species in molecule 1) -- particle_name (dataset for the atomic names (indices into particle name table) in molecule 1) -- particle_name_table (dataset for the atomic name lookup table in molecule 1) -- residue_id (dataset for the residue identifier in molecule 1) -- sequence (dataset for the residue sequence (indices into residue name table) in molecule 1) -- residue_name (dataset for the residue names (indices into residue name table) in molecule 1) -- residue_name_table (dataset for the residue name lookup table in molecule 1)
| [in] | baseContainer | The HDF5 container to write to |
| [in] | moltypes | The molecule types to write |
| void gmx::writeParameterInformation | ( | TextWriter * | writer, |
| const t_inputrec & | ir, | ||
| bool | writeFormattedText | ||
| ) |
Write information about system parameters.
This method writes the basic information for the system parameters and simulation settings as reported in the ir.
| [in] | writer | TextWriter object for writing information. |
| [in] | ir | Reference to inputrec of the run input. |
| [in] | writeFormattedText | Decide if we want formatted text output or not. |
| void gmx::writeResidueInfo | ( | AtomRange & | atomRange, |
| const hid_t | baseContainer, | ||
| const std::optional< IndexMap > & | selectedAtomsIndexMap = std::nullopt |
||
| ) |
Write residue and sequence information to the H5MD file.
The result residue-related information is stored in the group baseContainer/<groupName>. Including:
residue_name_tableresidue_name_table| [in] | atomRange | Atom range for iterating all atoms and accessing atomic properties. |
| [in] | baseContainer | The HDF5 container to write the residue information to. |
| [in] | selectedAtomsIndexMap | The index map of the selected atoms, not provided means considering all atoms. Providing an empty map throws an internal error. |
| void gmx::writeSystemInformation | ( | TextWriter * | writer, |
| const gmx_mtop_t & | top, | ||
| bool | writeFormattedText | ||
| ) |
Write information about the molecules in the system.
This method should write all possible information about the molecular composition of the system.
| [in] | writer | TextWriter object for writing information. |
| [in] | top | Local topology used to derive the information to write out. |
| [in] | writeFormattedText | Decide if we want formatted text output or not. |
|
static |
String names corresponding to ActiveFmmBackend enum values.
|
static |
Constant that tells what the architecture is.
|
static |
Mapping for enums from ChangeAtomsType.
|
static |
Mapping for enums from ChangeSettingType.
|
static |
The names of the methods to determine the amplitude of the atoms to be spread on a grid.
|
static |
Name the methods that may be used to evaluate similarity between densities.
| constexpr double gmx::c_epsilon0 |
|
static |
String names corresponding to ExaFmmTreeType enum values.
|
static |
String names corresponding to FmmDirectProvider enum values.
| const std::string gmx::c_fmmExaFmmMaxParticlesPerCellOptionName = "exafmm-max-particles-per-cell" |
MDP option name to set the maximum number of particles per cell for ExaFMM.
| const std::string gmx::c_fmmExaFmmTreeDepthOptionName = "exafmm-tree-depth" |
MDP option name to set the tree depth for ExaFMM.
| const std::string gmx::c_fmmExaFmmTreeTypeOptionName = "exafmm-tree-type" |
MDP option name to choose the tree type for ExaFMM (uniform or adaptive)
|
static |
The start and end value of the vsite indices in the ftype enum.
|
static |
The start value of the vsite indices in the ftype enum.
The validity of the start and end values is checked in makeVirtualSitesHandler(). This is used to avoid loops over all ftypes just to get the vsite entries. (We should replace the fixed ilist array by only the used entries.)
| constexpr real gmx::c_maxRInvSix = 1.0e15_real |
Higher limit for r^-6 used for Lennard-Jones interactions.
This is needed to avoid overflow of LJ energy and force terms for excluded atoms and foreign energies of hard-core states of overlapping atoms. Note that in single precision this value leaves room for C12 coefficients up to 3.4e8.
| const real gmx::c_maxSpacingScaling = 1.7 |
Scale the grid by a most at factor 1.7.
This still leaves room for about 4-4.5x decrease in grid spacing while limiting the cases where large imbalance leads to extreme cutoff scaling for marginal benefits.
This should help to avoid:
| constexpr real gmx::c_minDistanceSquared = 1.0e-12_real |
Lower limit for square interaction distances in nonbonded kernels.
This is a mimimum on r^2 to avoid overflows when computing r^6. This will only affect results for soft-cored interaction at distances smaller than 1e-6 and will limit extremely high foreign energies for overlapping atoms. Note that we could use a somewhat smaller minimum in double precision. But because invsqrt in double precision can use single precision, this number can not be much smaller, we use the same number for simplicity.
|
static |
The minimum nstlist for dynamic pair list pruning on CPUs.
In most cases going lower than 5 will lead to a too high pruning cost.
|
static |
The minimum nstlist for dynamic pair list pruning om GPUs.
In most cases going lower than 4 will lead to a too high pruning cost. This value should be a multiple of c_nbnxnGpuRollingListPruningInterval
|
static |
The interval in steps at which we perform dynamic, rolling pruning on a GPU.
Ideally we should auto-tune this value. Not considering overheads, 1 would be the ideal value. But 2 seems a reasonable compromise that reduces GPU kernel launch overheads and also avoids inefficiency on large GPUs when pruning small lists. Because with domain decomposition we alternate local/non-local pruning at even/odd steps, which gives a period of 2, this value currenly needs to be 2, which is indirectly asserted when the GPU pruning is dispatched during the force evaluation.
| constexpr float gmx::c_nbnxnMinDistanceSquared = 3.82e-07F |
Lower limit for square interaction distances in nonbonded kernels.
For smaller values we will overflow when calculating r^-1 or r^-12, but to keep it simple we always apply the limit from the tougher r^-12 condition.
|
static |
The names of the supported QM methods.
|
static |
Number of separate bins used during sorting of plist on gpu.
Ideally this number would be increased for very large system sizes (the cpu version of sorting uses 2 x avg(num cjPacked) but as sorting has negligible impact for very large system sizes we use a constant here for simplicity. On H100 sorting begins to have negligible effect for system sizes greater than ~400k atoms.
|
static |
Number of threads per block used by the gpu sorting kernel.
TODO this is a reasonable default but the number has not been tuned
|
static |
Prune kernel's jPacked processing concurrency.
The GMX_NBNXN_PRUNE_KERNEL_JPACKED_CONCURRENCY macro allows compile-time override.
| const gmx::EnumerationArray<XvgFormat, const char*> gmx::c_xvgFormatNames |
Names for XvgFormat.
Technically this duplicates a definition in pargs.cpp for legacy support code, but as the latter will go away and the alternatives are ugly, the duplication is acceptable.
|
static |
The non-bonded zone-pair setup for domain decomposition.
The first number is the i-zone, the second number the first j-zone seen by this i-zone, the third number the last+1 j-zone seen by this i-zone. As is, this is for 3D decomposition, where there are 4 i-zones. With 2D decomposition use only the first 2 i-zones and a last+1 j-zone of 4. With 1D decomposition use only the first i-zone and a last+1 j-zone of 2.
| const shift_consts_t const float const float const float const float const float float float* gmx::eLJ |
| gmx::else |
| const float gmx::epsilon |
| constexpr std::array<InteractionFunction, numFTypesOnGpu> gmx::fTypesOnGpu |
List of all bonded function types supported on GPUs.
| BondedGpuKernelBuffers float4 float3 float3* gmx::gm_fShift |
|
static |
This parameter should be determined heuristically from the kernel execution times.
This value is best for small systems on a single AMD Radeon R9 290X (and about 5% faster than 40, which is the default for CUDA devices). Larger simulation systems were quite insensitive to the value of this parameter.
|
static |
Gives the i-cluster size for each pairlist type.
|
static |
Tag output from the IMD module with this string.
|
static |
Gives the j-cluster size for each pairlist type.
|
static |
Array of the defines needed to generate a specific eel flavour.
The twin-cutoff entries are not normally used, because those setups are not available to the user. FastGen takes care of generating both single- and twin-cutoff versions because PME tuning might need both.
|
static |
Array of the defines needed to generate a specific vdw flavour.
|
static |
Names for the MTS force groups.
| constexpr unsigned int gmx::NBNXN_INTERACTION_MASK_ALL = 0xffffffffU |
Cluster-pair Interaction masks.
Bit i*j-cluster-size + j tells if atom i and j interact.All interaction mask is the same for all kernels
|
static |
Cost of non-bonded kernels.
We determine the extra cost of the non-bonded kernels compared to a reference nstlist value of 10 (which is the default in grompp).
| const std::vector<std::string> gmx::periodic_system |
symbols of the elements in periodic table
|
static |
Strings explaining why the system is incompatible with update groups.
|
static |
Constants whose bit describes a property of an atom in AtomInfoWithinMoleculeBlock.atomInfo.
No bit should exceed 1 << 31, so that it fits into a 32-bit integer.
Since the tpx format support max 256 energy groups, we do the same here, reserving bits 0-7 for the energy-group ID.
|
static |
The DD zone order.
|
static |
Define the torch datatype according to GMX_DOUBLE.
Important for converting data types, as model inference is always done in float32.
| const std::array<InteractionFunction, numFtypes> gmx::vSiteFunctionTypes |
| const std::array<InteractionFunction, numFtypes> gmx::vSiteFunctionTypesReversed |
 1.8.5
1.8.5
![\[ \mathrm{Similarity}(\rho_{\mathrm{r}},\rho_{\mathrm{c}}) = \frac{1}{N_\mathrm{voxel}}/\sum_{v=1}^{N_\mathrm{voxel}} \rho^v_{\mathrm{r}} \rho^v_{\mathrm{c}} \]](form_14.png)
![\[ \mathrm{Similarity}(\rho_{\mathrm{r}},\rho_{\mathrm{c}}) = \sum_{v=1}^{N_\mathrm{voxel}} \rho^v_{\mathrm{r}} (\log(\rho^v_{\mathrm{c}}) - \log(\rho^v_{\mathrm{r}})) \]](form_15.png)
![\[ \mathrm{Similarity}(\rho_{\mathrm{r}},\rho_{\mathrm{c}}) = \frac{\sum_{v}\left((\rho_{\mathrm{r}} - \bar{\rho}_{\mathrm{r}})(\rho_{\mathrm{c}} - \bar{\rho}_{\mathrm{c}})\right)} {\sqrt{\sum_v(\rho_{\mathrm{r}} - \bar{\rho}_{\mathrm{r}})^2 \sum_v (\rho_{\mathrm{c}} - \bar{\rho}_{\mathrm{c}})^2}} \]](form_16.png)